1.1 Biblioteka cyfrowa
Tylu ilu specjalistów zajmujących się bibliotekami cyfrowymi tyle funkcjonuje
definicji. Pozwolę sobie przytoczyć tutaj kilka najczęściej spotykanych.
Definicja z roku 1997 r. której autorem jest M. E. Lesk który określa bibliotekę
cyfrową jako : "a collection of information, which is both digitized and
organized" (zbiór informacji po pierwsze cyfrowej, po drugie uporządkowanej)
.
Definicja którą posługuje się R. M. Hayes "(...) a collection of publications
distributed or made available in digital form (i.e., which symbols are recorded
as bits and bytes - magnetic, electronic, or optical" [Zbiór publikacji
rozprowadzanych lub udostępnianych w formie cyfrowej (tj. których symbole są
zapisane w bitach i bajtach magnetycznych, elektronicznych lub optycznych)]
Według Ch.L. Borgmana : "Digital libraries are constructed - collected
and organized - by [and for] a community of users, and their functional capabilities
support the information needs and uses of that community. They are a component
of communities in which individuals and groups intract with each other, using
data, information, and knowledge resources and systems. In this sense they are
an extension, enhancement, and integration of a variety of information institutions
as physical places where resources are selected, collected, organiozed, preserverd,
and accessed in support of a user community. (Biblioteki cyfrowe są tworzone
- a ich zbiory gromadzone i klasyfikowane - przez i dla społeczności użytkowników,
a ich możliwości funkcjonalne wspierają potrzeby informacyjne i cele tej społeczności.
Są elementem społeczeństwa, w którym jednostka i grupa komunikują się i współpracują,
wykorzystując dane, źródła wiedzy i systemy. W tym sensie rozwijają się, podnoszą
jakość i integrują różne instytucje informacyjne jako miejsca, w których źródła
informacji są wybierane, gromadzone, klasyfikowane, chronione i udostępniane
użytkownikom.)
Oraz ostatnia, robocza definicja przedstawiona w roku 1998 przez Digital Library
Federation : "Digital libaries are organiozations that provide the resources,
including the specialized staff, to select, structure, offer intellectual access
to , interpret, distribute, preserve the integrity of, and ensure the persistence
over time of collections of digital works so that they are readily and economically
available for use by a defined community or set of communities." Cyfrowe
biblioteki są organizacjami, które zapewniają zasoby włączając wyspecjalizowany
personel aby wybierać, strukturalizować, oferować intelektualny dostęp, interpretować,
rozprowadzać, zachowywać integralność i zachować trwałość w czasie zbiorów dzieł
cyfrowych tak aby były gotowe i ekonomicznie dostępne do użytku dla określonej
społeczności lub zbioru społeczności.
1.2 Początki bibliotek cyfrowych
Pierwsze z systemów informacji sieciowej były rozwijane przez społeczeństwa
techniczne i profesjonalne, które koncentrowały się na swoich własnych potrzebach.
Główny nacisk położony był na udostępnianie informacji kolegom czasami również
ogółowi. Biblioteka cyfrowa przyszłości będzie istnieć wewnątrz dużo większej
ramy ekonomicznej, społecznej i prawnej.
Na przykład dzieła muzyczne stanowiące twórczość kompozytorów i muzyków powinny
być przechowywane i transmitowane w formie jak najbardziej zbliżonej do oryginału,
aby nie cierpiała na tym reputacja autorów. Dzieła takie, o ile podlegają prawu
autorskiemu, wymagają oczywiście wynagrodzenia.
Odnośne dziedziny prawa obejmują prawa autorskie, wykonawcze i inne własności
intelektualne, zniesławienie, prawo komunikacyjne, prywatność i prawo międzynarodowe.
1.3 Zmierzch epoki papieru
Czy nadchodzą czasy kiedy to drukowane książki będą rzadkością ? Jak twierdzi
Bill Gates za 25 lat książki w formie tradycyjnej będą anachronizmem, będą natomiast
dostępne w postaci cyfrowej. Tradycyjne książki staną się bardzo drogie i będzie
na nie stać tylko najbogatszych, a elektroniczne wersje gazet, czasopism i magazynów
w kioskach przestaną być czymś dziwnym. Obecnie w Internecie pojawia się coraz
więcej wydawnictw sprzedających książki w postaci elektronicznej oraz bibliotek
cyfrowych. Dzięki nim za niewielką opłatą można pobrać na dysk twardy pełnotekstową
książkę. Rozwój tego rynku stał się opłacalny w momencie, kiedy zaistniały techniczne
możliwości do bezpiecznego używania kart kredytowych. Jak również innego rodzaju
bezpiecznych form płatności. Amerykańska firma Accenture oszacowała, że w już
w roku 2005 rynek wydawniczy będzie opanowany w 10% właśnie przez książki elektroniczne.
Utrzymuje się pewne zamieszanie czego dotyczy termin ebook. Czy jest to urządzenie
ukształtowane w formie książki czy słowa i obrazki jakie są wyświetlane dzięki
niemu a może oba ? Termin książka oznacza zarówno treść a więc słowa i obraz
oraz medium (papier). Jedno bez drugiego nie jest książką.
Czym zatem jest ebook ?
Oto wybrane definicje ebooka :
- Ebook jako termin użyty aby opisać tekst analogiczny do książki będący w formie
cyfrowej do wyświetlenia na ekranie komputera.
- Książka która została przetworzona na formę cyfrową, może być czytana na komputerze
zazwyczaj przez sieć lub bezpośrednio z CD-ROMu. Ebooki mogą rozszerzać media
drukowane poprzez dodawanie linków hypertekstowych, funkcji wyszukiwania i odsyłaczy
oraz multimediów.
- Ebook to cyfrowy materiał do czytania który się odczytujemy z ekranu komputera,
notebooka lub na dedykowanym urządzeniu ze zdolnością ściągania nowych tytułów
przez sieciowe połączenie.
- Ebooki to książki w formacie pliku komputerowego i czytane na wszystkich typach
komputerów włączając urządzenia trzymane w ręku zaprojektowane specjalnie do
ich czytania. Ebooki są tak znane, jak ich drukowane odpowiedniki lub tak unikalne
jak samo medium elektroniczne, zawierające hyperlinki, dane audio i video. Ebooki
mogą być ściągane z sieci lub otrzymywane jako załączniki do listów. Ebooki
na dyskietkach lub cdromach są wysyłane pocztą lub sprzedawane jako dodatki
do różnych czasopism.
- Ebook odnosi się do elektronicznych plików słów i obrazów, które są długości
książki sformatowane do wyświetlania na jednym lub wielu urządzeniach znanych
jako czytniki ebooków i sprzedawanymi lub rozprowadzanymi jako samodzielne produkty.
Czytniki ebooków są definiowane jako urządzenia używane do czytania ebooków.
Te mogą być trzymane w ręce lub nie, dedykowane lub nie.
Niebagatelną role odegrają biblioteki, które zapewnią mechanizm dla przechowywania,
składowania i dzielenia się dokumentalnymi materiałami różnych typów. Typy informacji
jakie będą zawarte i różne media używane do gromadzenia tej informacji wpłyną
na właściwości biblioteki. Pojawienie się nowych technologii operowania informacją
wpłynął znacząco na podstawową naturę papierowych bibliotek i stworzył potrzebę
nowego typu systemów bibliotecznych jak elektroniczne i cyfrowe biblioteki.
Opóźnienia na rynku książek elektronicznych spowodowane są głównie obawami przed
crackerami , którym jak na razie żaden ze standardów zabezpieczeń książek elektronicznych
się nie oparł.
Do roku 2005 przemysł wydawniczy przewiduje stratę 1.5 mld dolarów poprzez piractwo
ebookowe. Według raportu Forester Research z roku 2000. Przewidywane jest, że
wzrost systemów współdzielenia danych każdy z każdym takich jak napster, gnutella
i freenet, łącznie z faktem, że żaden schemat szyfrowania cyfrowego nie jest
odporny na hackowanie. Stworzy to szerokie piractwo cennych książek. Ta groźba
rozpowszechnionego piractwa zagraża zdrowemu wzrostowi przemysłu wydawniczego
cyfrowego i oto dlatego ebooki są projektowane aby zapewniać prawa autorom i
wydawcom. W przeciwieństwie do urządzeń takich jak PC i PDA(Portable Data Assistant),
platforma Ebooka zawiera rygorystyczne rozwiązanie zabezpieczenia praw autorskich
które zabezpiecza prace wydawców i autorów. W konsekwencji zaprojektowano platformę
ebook od podstaw aby zapobiec bezprawnemu kopiowaniu, powielaniu i dystrybucji,
cyfrowych książek, periodyków i innych dzieł.
Ciekawą propozycją są również książki na żądanie (print on demand). Usługa ta
będzie polegała na tym, że książki będą składowane na serwerach wydawców i będą
drukowane w momencie gdy klient tego zażąda. Niesie to za sobą w zasadzie same
oszczędności. Nietrudno bowiem wyobrazić sobie sytuację, kiedy klient przychodzi
do księgarni wybiera sobie interesującą go książkę spośród wszystkich książek
dostępnych przez wszystkich wydawców. I prosi o jej wydruk. Księgarnie w tym
momencie stają się zupełnie małymi firmami, można zredukować liczbę personelu,
zaoszczędzić na transporcie, powierzchni, księgarnia nie traci klientów, ponieważ
wszystkie książki są dostępne. Księgarnia nie zamraża kapitału w towarze zamówionym
a nie odebranym przez klienta. Klient nie traci czasu szukając książek lub oczekując
na książki zamówione.
Skoro już znamy prognozy na najbliższą przyszłość przyjrzymy się uważniej systemowi
określanemu mianem biblioteki cyfrowej. Skąd się wzięły pomysły jego stworzenia
? Na jakie kluczowe pytania należy odpowiedzieć aby łatwiej było podjąć decyzję
czy potrzebujemy takiego czy nie ?
Czy dana dziedzina ma zbiór czysto cyfrowych materiałów ?
Czy konieczne jest by ten materiał był dostarczany bezpośrednio do komputerów
użytkowników ?
Czy użytkownicy rzeczywiście muszą szukać materiałów w postaci cyfrowej, czy
nie wystarczą im książki i czasopisma w tradycyjnej formie?
Jak typ/rodzaj materiałów znajdujących się w tradycyjnej bibliotece skorzystałby
najbardziej na przetworzeniu go na informacje cyfrową ?
Czy istnieje potrzeba rozprowadzania materiałów w wielu kopiach w tym samym
czasie ?
Czy materiały których szukasz można znaleźć na półce czy są to materiały unikatowe/poufne
?
Czy użytkownicy biblioteki są bardzo od niej oddaleni ?
Czy nowe materiały dostępne są w formie cyfrowej ?
Czy istnieje możliwość wymiany nowych materiałów w formie cyfrowej miedzy bibliotekami
?
Czy materiały zawarte w bibliotece są wykonane przez pracowników danej instytucji
?
Czy warto przetwarzać materiały na wersję cyfrową biorąc pod uwagę częstotliwość
wykorzystania oraz przeznaczenie ?
Czy digitalizacja sprawi, że materiał będzie częściej używany ?
Czy materiał będzie łatwiejszy do znalezienia a w ten sposób tańszy ?
Czy będzie prezentowany on w formie bardziej przyjaznej dla użytkownika ?
Jakie są koszty wprowadzania informacji do systemu ?
Czy lepiej oszczędzić wydatki (np. na digitalizację) dla bieżących kosztów administracyjnych?
Czy celem biblioteki cyfrowej jest zastąpienie biblioteki konwencjonalnej ?
Czy nie chętniej sięgnelibyśmy od razu do internetu po potrzebne materiały ?
1.4 Cel i zakres pracy
Celem pracy jest analiza szerokiego spektrum możliwości implementacji i istniejącego
oprogramowania, tak aby możliwe było wskazanie najodpowiedniejszej platformy
sprzętowo-programowej dla systemu biblioteki cyfrowej. Końcowym etapem jest
implementacja aplikacji do przeglądania dokumentów np. starodruków. Źródło aplikacji
dostępne jest w załączniku do pracy.
2. Podstawowe pojęcia używane w pracy
2.1 WWW (World Wide Web)
Sieć WWW została wymyślona w 1990 roku przez Tima Bernersa-Lee, pracownika CERN,
zrodziła się ona jako wizja sposobu publikowania w Internecie artykułów z dziedziny
fizyki bez konieczności zmuszania naukowców do żmudnego kopiowania i drukowania
plików. Sieć WWW można określić jako sieć połączonych ze sobą sieci, w których
komputery zwane serwerami, udostępniają różnego rodzaju dokumenty.
2.2 Model klient-serwer
Większość usług internetowych oparta jest na modelu klient-serwer. W modelu
tym jeden program prosi inny o wykonanie określonej usługi. Oba programy mogą
działać na tym samym komputerze, lub (znacznie częściej) na dwóch różnych. Program
żądający wykonania usługi nazywany jest klientem, a program który daną usługę
realizuje jest serwerem. Przykładem programu klienta może być przeglądarka stron
WWW.
2.3 Przeglądarka
Program który komunikując się z serwerem pobiera z niego informację i odpowiednio
ją interpretując pozwala na jej oglądanie.
2.4 Główne standardy wykorzystywane w sieci web
2.4.1 Dokumenty
W zasadzie wszystkie istniejące rodzaje dokumentów mogą być przez serwer WWW
przechowywane, część z nich jest interpretowana przez przeglądarki, reszta z
nich przez programy zewnętrzne rezydujące na komputerze użytkownika. W skład
dokumentów tekstowych wchodzą dokumenty następujących o następujących formatach
:
- HTML (HyperText Markup Language)
HTML opisuje dokument za pomocą określonego z góry zestawu znaczników o ustalonych
cechach prezentacyjnych. Niestety nie jest on w stanie sprostać bardziej zaawansowanym
potrzebom, jakie zrodził rozwój publikowania w Internecie. Ponadto dokumenty
HTML mogą lepiej lub gorzej prezentować się w oknie przeglądarki, ale nie nadają
się do przetwarzania. Nie nadają się do budowy baz danych, z którymi współpracują
serwisy informacyjne w Internecie i system e-business. Ograniczenia te dostrzeżone
zostały przez World Wide Web Consortium (W3C), czuwające nad standardami WWW
czego efektem powstanie jest język XML.
- SGML (Standard Generalized Markup Language)
Generalnie SGML służy do definiowania języków znakowania tekstu aby dzięki temu
móc go w określony automatyczny sposób przetwarzać. Mając już oznakowany tekst
aby go opublikować lub uzyskać wersję przeznaczoną do druku należy nadać elementom
jedynie cechy typograficzne (krój pisma, położenie na stronie etc.) i formatować
je na wiele sposobów. SGML został stworzony z myślą o wielkich projektach wydawniczych
oraz publikacjach, takich jak : dokumentacja techniczna, zbiory przepisów prawa,
czy publikacje naukowe. Przygotowanie takich publikacji na podstawie tekstów
oznakowanych ogólnie jest o wiele bardziej efektywne niż w przypadku wykorzystywania
tradycyjnych metod. Dzięki ogólnemu oznakowaniu łatwiej jest bowiem kontrolować
spójność kompletność i aktualność zasobów, wnosić modyfikacje oraz szybciej
przygotować nowe wydania.
- XML (eXtensible Markup Language)
XML jest uproszczoną wersją języka SGML. Można przyjąć, że XML jest następcą
HTML'a. Nie ogranicza on nas do zestawu predefiniowanych znaczników, ale pozwala
tworzyć własne. Dzięki temu można dokładniej opisać zawarte w dokumencie informacje.
Istnieje również możliwość wprowadzenia struktury przechowywanych danych. Dzięki
której mamy pełną kontrolę nad powstającymi w oparciu o nią dokumentami.
- PDF (Adobe Acrobat Portable Document Format)
Formatem odbiegającym nieco od przedstawionych powyżej jest format PDF, wynika
to w głównej mierze z tego, iż jest to format binarny, w związku z tym może
on być edytowany wyłącznie przy pomocy dodatkowych narzędzi. Drugą cechą która
wyróżnia ten format jest integracja w obrębie dokumentu tego typu tekstu i grafiki.
Format ten pozwala na zachowanie takiego samego wyglądu dokumentu w różnych
środowiskach.
PDF jest językiem opisu strony opartym o postscript, charakteryzuje go struktura
obiektowa, elementy hipertekstowe typu formularze oraz wtyczki (plug-ins), może
być odczytywany poprzez program Acrobat Reader integrujący się z przeglądarką
Internetową. Z uwagi na potencjalnie duże znaczenie tego formatu dla biblioteki
cyfrowej, więcej na jego temat w dalszym rozdziale.
2.4.2 Grafika
Do najpopularniejszych standardów graficznych możemy zaliczyć :
- JPEG
Format ten został zaprojektowany na potrzeby fotografii cyfrowej i w tym względzie
jest obecnie najlepszym rozwiązaniem. Jednocześnie należy pamiętać, że w przeciwieństwie
do innych formatów pikselowych takich jak (BMP, PCX, TIFF czy GIF) format JPEG
jest formatem stratnym (ang. lossy), co oznacza, że nie zawsze dokładnie rekonstruuje
piksele oryginalnego obrazu pełnokolorowego. Zatem przygotowane pliki w tym
formacie nie powinny być już później konwertowane do innych standardów, gdyż
wiąże się to z utratą jakości.
Przygotowując materiał na potrzeby biblioteki cyfrowej należy mieć na uwadze
fakt, iż JPEG nie jest odpowiedni dla niektórych rodzajów obrazów. Format ten
został zaprojektowany do obsługi fotografii, nie radzi sobie dobrze z ostrymi
krawędziami, charakterystycznych dla obrazów tworzonych komputerowo. Nie kompresuje
też szczególnie dobrze dużych powierzchni o jednolitym kolorze, w czym wyróżnia
się format GIF (np. rękopisy, schematy, ryciny). Ponadto nie obsługuje tzw.
kanałów alfa, co oznacza, że uniemożliwia tworzenia efektów przezroczystości.
Mimo swych wad jest najlepszym rozwiązaniem na potrzeby cyfrowej fotografii.
Główną zaletą tego formatu jest doskonały stopień kompresji zazwyczaj mieszczący
się w zakresie od 10:1 do 30:1, co ma olbrzymie znaczenie przy zapotrzebowaniu
na pamięć dla cyfrowych zdjęć.
- GIF
Główna idea, na której bazuje format GIF to redukcja palety kolorów połączona
z kompresją objętości plików wynikowych. W wyniku konwersji pliku typu truecolor
do standardu GIF głębia barw zmniejszana jest z 24 bitów (16,7 miliona kolorów)
do 8 bitów (256 kolorów). Tak przetworzony plik poddawany jest kompresji programowej.
Twórcy standardu zdecydowali się na wybór metody LZW , która opiera się na założeniu,
że w grafice występują powtarzające się wzory punktów o tej samej barwie, które
stanowią tzw. informację nadmiarową. Te wzory zastępowane są kodami liczbowymi
i zapamiętywane w tablicy kodowej. Im więcej informacji nadmiarowej zawiera
grafika, tym większy stopień kompresji można uzyskać. Algorytm LZW podobnie
jak kodowanie Huffmana należy do bezstratnych metod kompresji (ang. lossess
compession mechanisms), które nie powodują utraty danych. Zatem, po dekompresji
pliku utworzonego metodą LZW uzyskuje się informację zgodną z oryginałem. Połączenie
redukcji głębi barw z kompresją LZW pozwala uzyskać stopień kompresji od 20
do 80 procent, zależnie od wielkości i rodzaju grafiki.
W związku z tym, że redukcja barw stosowana w formacie GIF powoduje utratę części
informacji, fakt ten budzi niezadowolenie wśród wielu twórców stron WWW. 256
kolorów stanowi ich zdaniem zbyt duże ograniczenie dla funkcjonalności formatu
i jest niewystarczające do przedstawienia fotografii wysokiej jakości. Paleta
taka jest jednak zupełnie wystarczająca dla grafik, z myślą o których standard
GIF był utworzony.
Podstawowe cechy wyróżniające standard typu GIF to możliwość utworzenia:
- przeplotu
- przezroczystego tła
- animacji
- TIFF
Format TIFF powstał pierwotnie jako format dla rysunków w skali szarości. TIFF
jest uznanym przez profesjonalistów standardem, zawdzięcza to przede wszystkim
temu, iż obsługuje pliki CMYK, RGB oraz skalę szarości bez kanałów alfa. Obsługiwane
są również pliki Lab, pliki w kolorach indeksowanych i bitmapy bez kanałów alfa.
Jest to format z możliwą kompresją algorytmami LZW, RLE, JPEG, CCITT4 Fax Compresion.
Sposób zapisu informacji o obrazie pozwala na jego bardzo szybką edycję. W przypadku
dużych rysunków możemy uzyskać dostęp od razu do jego wybranego fragmentu nie
wczytując całego rysunku do pamięci. Ilość informacji przypadających na jeden
piksel może wahać się od 2 do 96 bitów. Ponadto można zapisać do niego dodatkowe
informacje tekstowe.
TIFF w/CCITT fax 4 Compression - idealnie pasujący do czarno-białych dokumentów
tekstowych. Format ten dostarcza wysoki poziom szczegółu (600 dpi) w połączeniu
z małym rozmiarem plików (poniżej 100kb na stronę tekstu 5x8 cali). Może być
używany jako format pliku archiwalnego.
- PNG (Portable Network Graphics)
Format ten powstał jako bezpatentowa alternatywa dla formatu GIF. Jest to format
bezstratny, używany jest głównie do wyświetlania obrazków z sieci WWW. W odróżnieniu
od formatu GIF liczba bitów w których może być zapisana informacja o kolorze
to 24 , możliwe jest również zapisanie informacji o przezroczystości. Format
ten obsługiwany jest przez przeglądarki internetowe od wersji 3.0 tak dla Netscape
Navigatora jak i dla Internet Explorera. Obsługuje skalę szarości oraz tryb
RGB z jednym kanałem alfa, a tryb bitmapowy i kolory indeksowane bez kanałów
alfa.
- PhotoCD
Format Photo CD opracowała firma Kodak, w celu przechowywania wysokiej jakości
zdjęć na płytach CD. Zdjęcia umieszczane na płytach CD są skanowane bezpośrednio
z błony fotograficznej. Każdy z plików tego formatu skanowany jest w pięciu
lub sześciu poziomach rozdzielczości (w zależności od wersji) zaczynając od
bardzo niskiej (128x192 piksele) a kończąc na bardzo wysokiej (4096x6144 piksele),
każdy z plików zawiera te wszystkie poziomy. Edytory plików PhotoCD pozwalają
na wybranie rozmiaru pliku z którym chcemy pracować, jak również konwersję jego
na inne formaty.
- DjVu
Format DjVu jest najnowszym z formatów graficznych. Doskonale nadaje się do
przechowywania wysokiej jakości fotografii. Pod nazwą DjVu kryją się trzy stratne
technologie kompresji, których należy użyć w zależności od materiałów które
mamy. Pierwsza z nich to DjVuText, stworzona dla obrazów bitonalnych lub z przeważającą
liczbą kolorów jednorodnych. Wybranie tego algorytmu pozwala stworzyć od 3 do
10 razy mniejsze pliki niż te zapisane w formacie TIFF lub PDF. DjVuPhoto to
druga z kompresji, której należy użyć w przypadku zdjęć. W porównaniu do kompresji
używanej w plikach JPEG, otrzymujemy 2 razy mniejszy plik wynikowy, obrazek
będący składową strony www pojawia się bardzo szybko i stopniowo polepsza się
jego jakość, dekompresja obrazów o dużych rozdzielczościach odbywa się w locie,
dzięki temu możliwe jest ich płynne zbliżanie i przeglądanie. Dla przykładu
możliwe jest przeglądanie rysunków o rozdzielczości 4000x4000 punktów, na komputerze
wyposażonym w 32MB pamięci operacyjnej bez wykorzystywania pamięci swap. DjVuLayered
jest kolejną z metod kompresji stosowaną do skanowanych dokumentów w kolorze
lub skali szarości, które zawierają tekst i obrazy. Zatem idealna dla dokumentów
historycznych, manuskryptów, czasopism, katalogów, komiksów itp. Niestety, przeglądarki
internetowe nie obsługują tego formatu, aby można było przeglądać pliki tego
typu należy zainstalować odpowiednią wtyczkę.
- MrSID (Multi-Resolution Seamless Image Database)
Format ten jest podobny do formatu DjVu, ponieważ DjVu obsługuje tylko przestrzeń
kolorów YCrCb, może on nie nadawać się dla pewnych typów aplikacji medycznych,
geologicznych itd. Wspiera on technologię opartą o selektywną dekompresję, powoduje
ona, że dekompresowane są tylko te dane które będą wyświetlane, można zatem
używać jednego obrazu jako źródła reprodukcji obrazów oraz jako piktogramów
na stronę WWW. Plikowi TIFF o wielkości 55MB odpowiada 5MB plik w formacie JPEG
i tylko 1.6MB MrSID. Istnieje także odmiana tego formatu szeroko stosowana w
aplikacjach typu GIS (Geographic Information Systems).
2.4.3 Muzyka
- MIDI (Musical Instrument Digital Interface)
Główną zaletą tego formatu muzycznego jest transmitowanie poprzez Sieć jedynie
danych sterujących (m.in. nazwa aktualnie używanego instrumentu, wysokość poszczególnych
dźwięków, czasu trwania i dynamiki dźwięku), co w efekcie wpływa nieznacznie
na zajętość wykorzystywanego pasma transmisyjnego. Z reguły pliki tego typu
charakteryzują się niewielkimi rozmiarami (od kilku do kilkudziesięciu KB).
Interpretacją dźwięku zajmuje się w tym przypadku komputer-klient, wykorzystując
w tym celu możliwości zainstalowanej karty dźwiękowej. Oczywiście, ze względu
na charakter tego formatu (przesyłanie tylko dźwięków zgodnych ze standardem
MIDI) może mieć on głównie zastosowanie, gdy tradycyjna biblioteka posiada materiały
muzyczne zgodne z tym standardem.
- WAV (wave)
Dźwięk w postaci cyfrowej zapisywany jest w tzw. plikach audio, z których najbardziej
popularnym formatem jest standard WAV (ang. wave - fala; średnio 5 min. muzyki
WAV zajmuje ponad 50 MB danych), zapewniający jakość płyty kompaktowej. W zbiorach
takich są przechowywane zarówno krótkie próbki brzmień instrumentów jak i całe
utwory muzyczne. Najistotniejszą cechą tego formatu jest fakt, iż nie wykorzystuje
on żadnego algorytmu kompresji, przez co wykorzystywany jest głównie do przechowywania
krótkich fragmentów dźwiękowych. Oczywiście otrzymane w ten sposób cyfrowe przekształcenia
wciąż wymagałyby pojemnych nośników danych, a co za tym idzie łączy o dużych
przepustowościach.
- MP3
Format MP3 to obecnie najbardziej popularna metoda przechowywania skompresowanego
dźwięku. Niestety kompresja w przypadku tego formatu wiąże się ze stratą jakości
(najczęściej słabo lub wcale nieodczuwalną). Kompresja zastosowana w formacie
MP3 pozwala zaoszczędzić ogromną ilość miejsca. (Utwór trwający 4.15 minuty
w formacie WAV zajmuje około 45,1 MB, podczas gdy w formacie MP3 tylko 3,4 MB
przy przepustowości 128 Kb/s).
2.4.4 Standardy multimedialne
- RM (RealMedia)
To pliki, zawierające materiał, który jest dostarczany w sposób strumieniowy,
odtwarzane przez program RealPlayer.
- MPEG (Moving Picture Expert Group)
MPEG jest standardem kodowania ruchomych obrazów. Współczynnik kompresji obrazu
jest bardzo wysoki, dzięki temu przepustowość sieci 1.5Mb/s pozwala na bezproblemową
realizację funkcji multimedialnych. Samo kodowanie MPEG jest procesem bardzo
złożonym, w związku z czym wymaga dużej mocy procesora i dużo pamięci. Aby płynnie
odtwarzać dane video potrzeba procesora o mocy minimum 58 MIPS'ów.
- Flash
Flash jest językiem przy pomocy którego tworzy się multimedialne aplikacje na
strony WWW. Zwykle składają się one z grafik wektorowych, ale mogą również obejmować
bitmapy i dźwięki. Flasha można używać do tworzenia animacji takich jak loga,
różnego rodzaju menu ułatwiające nawigację, sekwencje komiksowe lub nawet cale
strony. Prezentacja we flashu jest binarnym plikiem .swf o zazwyczaj niewielkich
rozmiarach przez co szybko ładowanych. Pliki złożone w większości z grafik wektorowych
mogą być pokazane, w wyższych wersjach przeglądarek internetowych, bez utraty
jakości.
- SMIL (Synchronized Multimedia Integration Language)
Format ten scala niezależne obiekty multimedialne : wideo, grafikę, dźwięk itd.
w jedną prezentację multimedialną. Podstawowe zalety SMIL'ea to :
- możliwość tworzenia prezentacji z plików rozmieszczonych na różnych serwerach
- możliwość dostosowania ścieżki dźwiękowej i/lub napisów do języka wybranego
w odtwarzaczu
- możliwość przesyłania różnego rodzaju formatów, bez łączenia ich w jedną całość
2.5 Digitalizacja
Jest to proces polegający na zamianie informacji analogowej na cyfrową. Termin
ten odnosi się do obrazów, książek, danych audio oraz danych audio-video. Digitalizacja
jest niezbędnym etapem na drodze do archiwizacji oraz udostępniania danych.
W zależności od medium wejściowego proces digitalizacji przebiega inaczej. Należy
uwzględnić różne jego parametry. Najbardziej skomplikowanym rodzajem digitalizacji
jest digitalizacja książek, a wygląda ona tak :
- przygotowanie materiałów do skanowania
- skanowanie
- OCR
- tworzenie baz danych tekstu
- tworzenie linków
- indeksowanie
W przypadku digitalizacji obrazów pomijamy proces OCR oraz tworzenie baz danych
tekstu. Po zeskanowaniu należy obraz (w zależności od przeznaczenia) poddać
kompresji. W przypadku danych audio skanowanie zamieniamy na proces samplowania
lub jeśli mamy dane cyfrowe na płytach CD procesowi ekstrahowania. Dzięki tym
procesom otrzymujemy pliki WAV, (format omówiony powyżej), który najlepiej poddać
kompresji.
- Kompresja
Kompresja polega na zmniejszaniu objętości zbiorów danych. Kompresje można podzielić
na dwa typy :
- stratną
- bezstratną
Kompresja stratna stosowana jest w przypadku obrazów oraz dźwięku. Algorytmy
kompresji opierają się ona na niedoskonałości narządów wzroku i słuchu.
Kompresja bezstratna stosowana jest dla głównie dla tekstów. Czasami występuje
również w niektórych formatach obrazów, ale wtedy są to najczęściej obrazy o
szczególnym znaczeniu (na przykład archiwalnym).
Stopień kompresji zależy w głównej mierze od formatu zapisu danych, a co się
z tym wiąże od algorytmu kompresji wykorzystanym w danym formacie, a także od
materiału poddawanego kompresji.
2.6 OCR (Optical Charakter Recognition)
OCR można uznać za jedną z metod kompresji. Idea OCR polega na rozpoznawaniu
obrazów znaków i zamianie ich na kody ASCII. Dokument który powstaje w ten sposób
może zostać wyeksportowany do jednego z popularnych edytorów tekstowych a tam
w pełni modyfikowany. Warto zaznaczyć iż OCR pozwala zmniejszyć objętość dokumentów
do 15 razy. Niestety techniki rozpoznawania znaków nie są doskonałe, wiec niejednokrotnie
rozpoznane teksty wymagają ręcznych poprawek. Często jest to związane ze złą
jakością zeskanowanego materiału poddawanego obróbce. Metoda OCR nadaje się
tylko dla dokumentów tekstowych.
2.7 METADANE
Metadane to : "dodatkowa informacja, która jest niezbędna dla zasadniczych
danych wprowadzana dla zwiększenia użyteczności danych podstawowych". Z
kolei autorka K. Burnett zajmująca się tą problematyką twierdzi, iż "metadane
są to dane, które charakteryzują dane źródłowe, opisują ich relacje z innymi
danymi i przyczyniają się do efektywnego wykorzystania danych źródłowych"
. Istnieje również definicja, iż metadane "to każda informacja, która wspiera
efektywne wykorzystanie danych źródłowych uwzględniając przy tym pomoc w zarządzaniu
danymi, sprawnym dostępie do nich oraz ich analizę" .
Najpopularniejsze formaty metadanych to :
- Dublin Core
- Marc
- Text Encoded Description
- Encoded Archiwal Description
- Virtual Resources Association
- Common Information Model
- XML
2.7.1 Dublin Core
Format ten został stworzony przez bibliotekarzy i obecnie on najczęściej wykorzystywanym
formatem opisu dokumentów elektronicznych. Elementy Dublin Core mogą być podzielone
na trzy klasy.
ZAWARTOŚĆ(Content) WŁASNOŚĆ INTELEKTUALNA(Intellectual Property) DOOKREŚLENIE(Instantation)
Tytuł (Title) Twórca (Creator) Data (Date)
Opis (Description) Współtwórca (Contributor) Format (Format)
Źródło (Source) Własność (Rights) Identyfikator (Identifier)
Język (Language)
Relacja (Relation)
Miejsce i czas (Coverage)
Szczegółowy opis elementów można znaleźć w [1]. Cechy, które charakteryzują
Dublin Core to :
- prostota - nawet niezbyt wprawny użytkownik może się nim posługiwać
- spójność - dostarcza te same kategorie metadanych dla różnych typów dokumentów
- jednolitość - międzynarodowy charakter formatu pozwala na stosowanie go na
całym świecie
- elastyczność - można tworzyć w nim zarówno proste, jak i bardzo złożone opisy
- dopasowanie - DC może pracować w różnych środowiskach i narzędziach.
Elementy Dublin Core w dokumencie pisanym w języku HTML umieszcza się w znacznikach
META. Niestety z uwagi na twórców stron, którzy chcąc sztucznie podnieść atrakcyjność
strony wypełniają znaczniki META dużą liczbą nadmiarowych informacji, znaczniki
META są często ignorowane przez wyszukiwarki internetowe. Lekarstwem na to może
być XML.
2.7.2 MARC (MAchine-Readable Cataloguing)
Marc jest najstarszym z formatów wymiany danych bibliograficznych. Jest to standard
akceptowany i powszechnie stosowany w bibliotekach na całym świecie. Obecnym
centrum wspierania standardu MARC jest Biblioteka Kongresu Stanów Zjednoczonych.
Pierwotny format MARC'a nazywał się LC MARC ewoluował on z czasem do formy obecnej
zwanej MARC 21, które z kolei stanowi podstawę dla wielu odmian narodowych i
międzynarodowych. MARC odegrał poważną rolę w procesie automatyzacji bibliotek.
W MARC'u rozwinięte zostały takie usługi jak wypożyczenia biblioteczne, tworzenie
kolekcji zbiorów, współdzielenie zasobów. Struktura rekordu składa się z etykiety
rekordu i pól danych. Rekord MARC zawiera nie tylko pola złożone ze znaków ale
także opisy jak te pola należy interpretować. Na pole rekordu składa się niestety
pewna stała liczba znaków. Nowoczesne systemy nie mają takich ograniczeń. Z
uwagi na liczbę pól w MARC'u można zawrzeć bardzo dokładne opisy bibliograficzne
różnych obiektów, głównie jednak książek, czasopism, nośników audio i video.
Rozszerzeniem funkcjonalności jest pole 856, które określa gdzie znajduje się
forma cyfrowa danego dokumentu. A podpola określają pochodzenie pliku, jaką
drogą jest on dostępny, informację o kompresji pliku i programie który należy
użyć do dekompresji, wielkości pliku i inne. Pole 256 charakteryzuje plik komputerowy,
516 określa typ pliku, 538 określa wymagania systemowe. Ponieważ format MARC
jest bardzo skomplikowanym formatem, pociąga to za sobą konieczność obsługi
przez osobę wykwalifikowaną odchodzi się od formatu MARC zastępując go prostszymi
formatami.
2.7.3 XML (eXtensible Markup Language)
XML jest językiem łączącym w sobie najlepsze cechy formatów SGML i HTML. Celem
języka XML jest :
- umożliwienie definiowania składni rożnego rodzaju dokumentów
- umożliwienie interpretacji dokumentów, dostarczanych przez sieć WWW, w zależności
od używanej przeglądarki
- umożliwienie użycia różnego typu dowiązań między dokumentami
- Dzięki temu możliwe będzie :
- wymienianie danych między aplikacjami, użytkownikami w sposób zautomatyzowany
- prezentowanie dokumentów z różnych dziedzin przy pomocy jednolitego oprogramowania
- przetwarzanie i wyszukiwanie danych w jednolity sposób
- podzielenie i współdzielenie dokumentów
Cechy języka XML :
- XML można używać w istniejących protokołach sieciowych (HTTP, MIME).
- XML poprzez wykorzystanie okrojonej struktury SGML jest językiem o wiele od
niego prostszym, przez co o wiele łatwiej jest napisać program przetwarzający
dokumenty XML.
- Dokumenty napisane w XML'u są dość zrozumiałe dla laików.
Prawidłowo napisany dokument XML :
- Deklaruje zasoby wewnętrzne, użyte w dokumencie.
- Wylicza zasoby zewnętrzne będące częścią dokumentu.
- Wylicza rodzaje użytych zasobów innych niż XML.
- Wylicza zasoby o formacie nie tekstowym wykorzystane w dokumencie i określa
aplikacje pomocnicze, jakie mogą być potrzebne.
Cechy które odróżniają XML'a od SGML'a i HTML'a to :
- Modularność. Wiele dokumentów XML może zostać połączonych w jedną całość.
- Internacjonalizacja. Użycie znaków diakrytycznych jest znacznie prostsze z
uwagi na rezygnację z kodu ASCII na rzecz Unicode.
- Ukierunkowanie na dane. XML jest o wiele bardziej ukierunkowany na obsługę
danych, wspomaga również ściślejszą ich kontrolę.
- Elastyczność. Mechanizmy XML'a pozwalają łączyć obiekty bez konieczności istnienia
dokumentu docelowego.
Dokument XML ma postać tekstu. Jego struktura logiczna jest opisana znacznikami,
których zbiór sami definiujemy. Każdy element struktury opisany jest przez znacznik.
Strukturę dokumentów opisują dodatkowe struktury (opisane poniżej).
Faktyczną siłę XML'a stanowią moduły dodatkowe :
Wykorzystując rozszerzenia XML'a takie jak DTD i XScheme można tworzyć własne,
struktury dokumentów, które nie dość że będą poprawnie wyświetlane, to będą
doskonale opisane. Dokumenty w formacie XML są dokumentami tekstowymi interpretowanymi
przez różnego rodzaju narzędzia. Faktyczną siłę XML'a stanowią jego rozszerzenia
:
- DTD (Document Type Definition) Określa on logiczną strukturę dokumentu, wzajemne
zależności zachodzące pomiędzy jej częściami składowymi oraz ich prawidłową
kolejność. DTD może opisywać strukturę całych klas dokumentów, ponieważ stworzenie
odpowiedniej struktury nie jest zadaniem łatwym, zdefiniowano już część z nich
np. DTD dla wydawnictw periodycznych (ISO 12083 serial DTD), książek (AAP -
American Associated Press book DTD), równań matematycznych (ISO 12083 maths
DTD) itd.
- XML Schema alternatywny do powyższego język definicji dokumentów, ale oferuje
znacznie bogatszą w stosunku do DTD kontrolę nad zawartością, pozwala znacznie
dokładniej określać typy zawartości dokumentów tj. definiować typy złożone,
określać minimalne i maksymalne liczby powtórzeń elementów.
- Xlink jest językiem definiowania powiązań między dokumentami XML, oferuje
znacznie większą elastyczność w stosunku do rozwiązań stosowanych w HTML'u.
Dzięki niemu można tworzyć połączenia dwukierunkowe, jak również listę powiązań
przechowywać poza dokumentami (np. w bazie danych).
- XHTML jest formatem pośrednim w transformacjach XSLT do formatu HTML, w którym
struktura elementów oraz deklaracje elementów odpowiadają strukturze oraz deklaracjom
elementów języka HTML.
- Xpatch to język w którym definiuje się odwołania do części składowych struktury
dokumentu XML (elementów, atrybutów tekstu itd.) Wykorzystywany w arkuszach
stylów XSL:FO, transformacja XSL oraz zapytaniach języka XQL
- XQL (XML Query Language) język do formułowania zapytań o zawartość dokumentu
XML.
- XSL:FO (Extensible Stylesheet Language - Formatting Objects) - język definiowania
arkuszy stylów dla dokumentów XML. Narzędzie interpretujące XSL:FO najczęściej
wykorzystują transformację dokumentu źródłowego do formatu PDF.
- XSLT (Extensible Stylesheet Language Transformations) - język używany do definiowania
transformacji dokumentu XML do innych dokumentów np. XML lub tekstowych jak
również do HTML z wykorzystaniem formatu XHTML. Transformacje takie nazywa się
arkuszami stylów.
- XPointer & XFragments - składnie umożliwiające odwoływanie się do określonych
fragmentów dokumentu XML,
- CSS - plik stylów dokumentu, stosujący się zarówno do plików HTML, jak i XML,
- DOM (Document Object Model) - obiektowy model dostępu do zawartości dokumentów
XML, realizowany przez procesory XML. Procesor DOM tworzy w pamięci drzewo obiektów
odpowiadających strukturze dokumentu. Aplikacja korzystająca z procesora ma
możliwość przeszukiwania drzewa i odczytywania poszczególnych wartości, możliwe
są również zmiany.
- SAX (Simple API for XML) - jest modelem dostępu do zawartości dokumentu XML,
przez procesory XML. Działanie jego polega na generowaniu zdarzeń odpowiadających
elementom struktury dokumentu. Zdarzenia te są następnie obsługiwane przez aplikację
która korzysta z procesora.
- VoiceXML - jest specyfikacją, która definiuje język XML dla aplikacji głosowych.
Dzięki temu możliwa jest wymiana informacji pomiędzy człowiekiem a systemem
komputerowym przy pomocy głosu.
XML stosowany jako format wymiany danych bibliograficznych jest najmłodszym
z formatów.
2.8 Protokoły wymiany danych
2.8.1 HTTP (HyperText Transfer Protocol)
Jest to protokół komunikacji przeglądarek i serwerów WWW zaprojektowany tak
aby klient HTTP mógł pobierać/wysyłać dane z/do serwera HTTP. Jest to protokół
bezpołączeniowy tzn. że przeglądarka i serwer nie łączą się na dłużej, a jedynie
na czas przesyłania danych. HTTP to chyba najbardziej typowy przykład modelu
klient-serwer. Przeglądarka wysyła do serwera zlecenie. Serwer przetwarza je
i odsyła odpowiedź. Wszystkie transmisje HTTP mają właśnie taką formę.
2.8.2 SSL (Secure Socket Layer)
To bezpieczny standard komunikacji w Internecie. Podobnie jak omówiony wcześniej
HTTP protokół ten służy do wymiany informacji między serwerem HTTP a przeglądarką,
z tą różnicą, że dane wymieniane tą drogą są szyfrowane. Szyfrowanie odbywa
się przy użyciu kluczy publicznych. Scenariusz połączenia (w dużym skrócie)
wygląda tak : otwierane jest połączenie, klient i serwer wymieniają się kluczami
publicznymi, następuje ich weryfikacja, po weryfikacji (jeśli ta przebiegła
sprawnie) dane są wymieniane w postaci zaszyfrowanej. Dużą zaletą SSL jest to,
że jest to protokół którego działanie nie wymaga od użytkownika żadnej konfiguracji
przeglądarki. Dzięki wykorzystaniu SSL'a w Internecie można przeprowadzać bezpieczne
operacje finansowe.
2.8.3 Z39.50
Jest to standard amerykański, który służy do pozyskiwania informacji bibliograficznej.
Umożliwia on komunikację pomiędzy systemami pracującymi na zróżnicowanych platformach
systemowych i wykorzystujących różne oprogramowanie. Stworzenie tego protokołu
miało na celu wyeliminowanie problemów związanych z przeszukiwaniem wielu baz
danych. Włączona została opcja równoległego wyszukiwania. Działanie protokołu
Z39.50 opiera się na wymianie komunikatów pomiędzy dwoma aplikacjami, którymi
są : Z-klient i Z-serwer, który z kolei jest powiązany z jedna lub kilkoma bazami.
Protokół Z39.50 wykorzystywany jest najczęściej z poziomu katalogu OPAC .
2.9 Pełnotekstowa baza danych
Pełnotekstowa baza danych jest strukturą która zawiera wszystkie dane, metadane
oraz dodatkowe informacje które będą stanowiły trzon merytoryczny biblioteki
cyfrowej. Podstawowe cechy pełnotekstowej bazy danych to :
- Możliwość indeksowania dokumentów i szybkiego przeszukiwania ich zawartości
pod kątem występowania danej frazy.
- W parametrach wyszukiwania mogą wystąpić operatory AND, OR, NOT oraz znaki
maskujące typu *, ?
- Wynik wyszukiwania możemy poddać sortowaniu według relewantności tzn. według
liczby wystąpień danego słowa/frazy w tekście.
- Możemy uzyskać informację o pozycji słowa w tekście
- Optymalne indeksowanie z wykorzystaniem stoplisty (jest to oczywiście opcją,
którą warto rozważyć)
- Przeszukiwanie nawet bardzo dużych baz danych jest bardzo wydajne.
- Tworzenie/aktualizacja indeksów jest bardzo szybkie.
3. Biblioteka cyfrowa
Na bibliotekę cyfrową składają się trzy elementy : dane, oprogramowanie oraz
sprzęt komputerowy.
Najogólniej oprogramowanie biblioteki cyfrowej, możemy podzielić na kilka klas.
Pierwsza z nich bierze pod uwagę, to czy oprogramowanie jest komercyjne, darmowe
czy jest to projekt własny. Druga klasa czy jest to system scentralizowany czy
rozproszony. Istotną klasę stanowią systemy w których całość oprogramowania
rezyduje na serwerze umieszczonym poza biblioteką i do którego personel biblioteki
nie ma dostępu.. Część z wymienionych klas może się wzajemnie przenikać.
Z uwagi na rosnące zapotrzebowanie kręgów edukacyjnych na systemy wymiany, przeszukiwania
i udostępniania informacji, na rynku pojawia się coraz więcej tego typu komercyjnych
rozwiązań. Przykładami tego typu rozwiązań są produkty SUN'a lub IBM'a.
Produkty open-source pretendujące do zaszczytnego miana bibliotek cyfrowych
także ostatnimi czasy pojawiły się na rynku, należą do nich : Greenstone, TurboWebPL
i inne.
Projekty własne leżą w nurcie zainteresowań różnych uczelni, są one najlepiej
udokumentowane, niezwiązane z żadnym konkretnym sprzętem i wykorzystują najnowsze
niejednokrotnie bardzo zaawansowane i nowoczesne techniki. Podejście tego typu
jest bardzo ciekawe, z naukowego punktu widzenia, aczkolwiek może się zdarzyć
że któraś z wdrożonych nowinek nie stanie się standardem albo co gorsze przestanie
nim być.
Ostatnia ze wspomnianych klas dotyczy coraz bardziej popularnej usługi, obejmującej
oprogramowanie z półki, dostarczane zgodnie z modelem ASP (Application Service
Providing). Najogólniej mówiąc system jest przechowywany i uruchamiany z serwera
sprzedawcy. Klient płaci dzierżawę za korzystanie z aplikacji. Dostęp do aplikacji
odbywa się przez sieć Internet. Przykładem biblioteki cyfrowej opartej o ten
model jest biblioteka DigiTool oferowana przez firmę Ex Libris[17]. Za wykorzystaniem
ASP przemawia bardzo wiele :
- Klienci nie muszą inwestować w tworzenie własnej infrastruktury informatycznej
(sprzęt, sieć, ludzie). Cała odpowiedzialność za działanie udostępnionego systemu
spada na dostawcę. Podobnie z serwisowaniem. Klient płaci abonament za użytkowane
oprogramowanie, a koszty abonamentu obejmują również koszty aplikacji, administrowanie,
serwisowanie aplikacji oraz koszty sprzętu.
- Koszty korzystania z oprogramowania ASP są rozłożone w czasie.
- W zależności od abonamentu można dzierżawić różne wersje oprogramowania (np.
bardziej lub mniej spersonifikowane) Wielu dostawców ASP w ramach abonamentu
dostarcza najnowsze wersje oprogramowania w cenie abonamentu.
- usługi dostarczane przez ASP mogą być uruchomione bardzo szybko.
Istotne jest aby usługobiorca posiadał stały i niezawodny dostęp do Internetu.
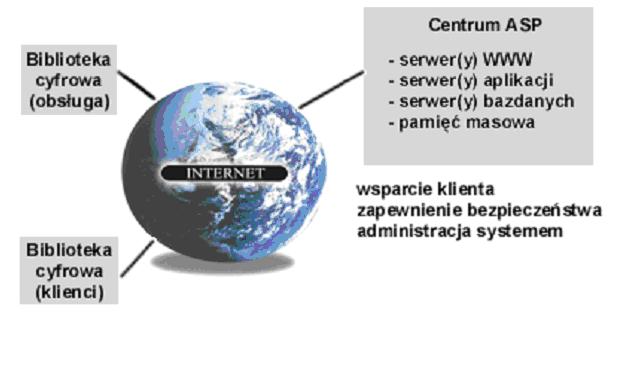
Przykładową architekturę techniczną ASP dla biblioteki cyfrowej przedstawia
Rys. 3.1.
Rys. 3.1
W pracy tej zwrócę uwagę na cechy którymi powinien się charakteryzować "własny
projekt" biblioteki cyfrowej.
Dane biblioteki cyfrowej w tej pracy będę określał mianem "obiektów cyfrowych",
które przechowywane są w repozytoriach i identyfikowalne przez unikalne numery.
Informacja przechowana w obiekcie cyfrowym to "zawartość obiektu cyfrowego",
która dzieli się na dane oraz informacje o danych zwane metadanymi. W repozytoriach
mogą być przechowywane obiekty cyfrowe wszystkich typów zaczynając od tekstów,
obrazów, dzieł muzycznych, programów komputerowych, baz danych, modeli, projektów,
danych video kończąc na obiektach złożonych ze wszystkich wymienionych typów.
Podstawowe formaty przechowywanych obiektów cyfrowych zostały omówione w rozdziale
"Podstawowe pojęcia używane w pracy"
Repozytoria są obiektami o określonej architekturze, zależnej od przechowywanych
w nich danych. Obiekt przechowywany w repozytorium będzie różnił się od obiektu
który otrzyma użytkownik. Każdy z obiektów w repozytorium posiada własny log
transakcji dokonywanych na nim zmian. Ponadto repozytorium gwarantuje, że tylko
poprawne operacje są przeprowadzane na obiektach danego typu. Istnieje kilka
komend odnoszących się do repozytorium tj. komendy dające dostęp do danych i
metadanych, żądania serwisowe pozwalające modyfikować dane i metadane oraz komendy
dodatkowe pozwalające na dodawanie i usuwanie obiektów.
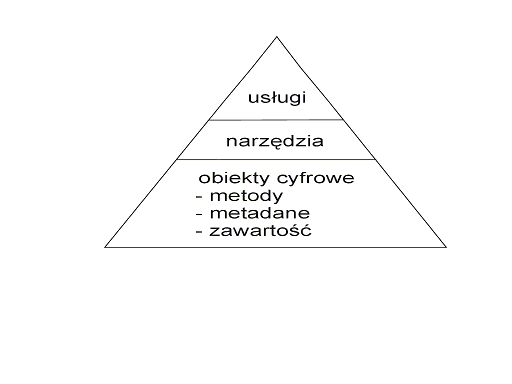
Tak może wyglądać logiczny model biblioteki cyfrowej (Rys. 3.2) :
Rys 3.2
Górna warstwa opisuje usługi, które są dostępne dla użytkowników. Usługi umożliwiają
wykonywanie żądań użytkowników np. wyszukiwania, przeszukiwania, wyświetlania,
nawigacji, manipulowania obiektami cyfrowymi, itd.. Warstwa środkowa to narzędzia,
które wykonują żądania warstwy usług. Narzędzia dysponują zbiorem zachowań,
które reprezentują akcje wykonywane przez użytkownika. Warstwa obiektów cyfrowych
może składować obiekty w rozproszonych lub scentralizowanych repozytoriach.
Obiekty mogą być podzielone na klasy np. osobne klasy stanowią dzienniki, czasopisma,
manuskrypty. Metody są czynnościami, które można wykonać w odniesieniu do danej
klasy obiektów cyfrowych. Metadane opisujące obiekt cyfrowy można podzielić
na trzy typy :
- Metadane opisujące - używane do wyszukiwania i identyfikacji obiektu.
- Metadane strukturalne - używane do logicznej prezentacji i nawigowania w danym
obiekcie.
- Metadane administracyjne - reprezentuje informację o danym obiekcie : datę
stworzenia, format pliku, informacje o prawach autorskich itd.
3.1 Funkcje bibliotek cyfrowych
Biblioteki tradycyjne pełnią trzy podstawowe funkcje :
- gromadzą
- przechowują
- udostępniają / dostarczają
3.1.1 gromadzenie
W bibliotece cyfrowej terminy te również istnieją, nabierają jednak całkowicie
nowego wymiaru.
Proces gromadzenia możemy określić mianem procesu pozyskiwania materiałów, w
bibliotece cyfrowej polega na ich zakupie lub stworzeniu. Tworzenie w ogólności
polega na zamianie postaci analogowej na postać cyfrową i opisaniu otrzymanych
w ten sposób danych.
Zanim to uczynimy musimy odpowiedzieć sobie na parę bardzo ważnych pytań. (Uwagi
te dotyczą skanowania i archiwizacji materiałów piśmienniczych). Jak skanować
materiały różnych typów? W jakich formatach je zachowywać ? Czy i kiedy używać
kliszy filmowej jako medium pośredniczącego pomiędzy formą drukowaną a postacią
cyfrową ?
Zasady postępowania z różnymi typami materiałów przedstawia poniższa tabela
(Tab. 3.1) :
Tab. 3.1
Dla obiektów, których nie ma w tym spisie stosujemy następującą zasadę dobierając
rozdzielczość skanowania : Określamy co jest najmniejszym znaczącym elementem,
który musi być czytelny w produkcie końcowym. W przypadku tekstów sprawa jest
względnie prosta : szukamy najmniejszych liter, cyfr, znaków diakrytycznych
lub symboli, które muszą być wyraźnie widoczne. W drukowanych książkach najmniejszym
tekstowym elementem jest często numerowanie stron lub litery z diakrytykami;
w przypadku dokumentów ręcznie pisanych jest duże zróżnicowanie. Dużo trudniej
jest określić co jest najmniejszym znaczącym elementem w fotografii lub dziele
sztuki. Częściowo zależy to od tego kto będzie używał skanowanego obrazu i w
jaki sposób. Amator może patrzeć na fotografię krajobrazu zwyczajnie, podczas
gdy geolog może potrzebować rozróżnić warstwowość klifu w tle.
Dla różnego rodzaju obiektów stosujemy różną głębie pikseli i tak skanowanie
w :
- 2 bitowej głębi zaleca się w przypadku :
normalnie współcześnie drukowanych czarno-białych tekstów, rozdzielczość 600
dpi (jak w tabelce powyżej), sztuka liniowa powinna być skanowana z rozdzielczością
600 dpi jeśli linie są delikatne i blisko siebie, Jeśli linie są grube, szeroko
rozstawione 300 dpi powinno wystarczyć. Należy spróbować.
- skali szarości :
ręcznie pisane dokumenty, maszynowe pisanie, manuskrypty, materiały archiwalne,
które są nominalnie czarno-białe lecz zawierają tonację i różnorodność gęstości
atramentu i tonalności, ilustracje półtonowe, skanować w rozdzielczości 300
dpi, jeśli tekst jest duży 200 dpi może okazać się wystarczające. Dla fotografii
czarno-białych 300dpi może wystarczyć chyba że fotografie zawierają dużo szczegółów.
Im starszy dokument tym bardziej kolorowa skala może być odpowiednia.
- kolorze :
mapy, plakaty skanowane w rozdzielczości 200dpi, kolorowe fotografie 300dpi
powinno wystarczyć, papirusy zalecana rozdzielczość 600 dpi gdy ziarna papieru
muszą być uchwycone.
Należy być świadomym, że im większa głębia koloru i wyższa rozdzielczość tym
więcej potrzebujemy miejsca aby to składować. Dla przykładu pliku archiwalnego,
do druku i na stronę WWW utworzonego ze zdjęcia 35 mm (Tab. 3.2) :
Format pliku Rozdzielczość Rozmiar pliku
TIFF 2048x3072, 24-bity 18,000 kilobajtów
PhotoCD 2048x3072, 24-bity 4,000 kilobajtów
JPEG 2048x3072, 24-bity 400 kilobajtów (średnia jakość)
Tab. 3.2
Podczas skanowania materiałów we własnym zakresie należy zwrócić uwagę na jeden
bardzo ważny aspekt :
Skany, które będziemy wykonywać powinny posiadać szare i kolorowe standardowe
pasy. Pasy te to wąskie skrawki papieru zawierające odcienie od białego do szarego
oraz standardowe bloki kolorowe, plus skala calowa lub metryczna. Celem tych
pasów jest :
- oddanie widzowi skali przedmiotu
- umożliwienie skanerowi i widzowi kalibrację sprzętu aby umożliwić jak najlepsze
oglądanie i druk z dokładnym kolorem.
Podczas skanowania materiałów w skali szarości dołączamy pas szary, do materiałów
kolorowych dołączamy pas kolorowy i szary. Pas kolorowy jest używany do ustalenia
dokładności koloru, natomiast pas szary do ustalenia odpowiedniej jasności.
Umieszczanie pasów powinno być stałe aby można je było później w łatwy sposób
usunąć, aby niepotrzebnie nie zajmowały miejsca.
W przypadku gdy chcemy materiał archiwalny zachować na mikrofilmach i stworzyć
wersję cyfrową danego materiału. Należy najpierw stworzyć wersję pośrednia a
następnie ją zeskanować. Pośrednictwo filmu to głównie slajdy 35mm, przezrocza
4x5, mikrofilm, mikrofiszka pojedynczo-klatkowa. Najlepiej jest używać negatywów
kiedy jest to możliwe. Za każdym razem, kiedy slajd lub inny typ filmu jest
duplikowany traci szczegóły i rozdzielczość i w rezultacie skan jest gorszej
jakości.
Generalnie lepiej jest pracować z negatywem niż pozytywem nie tylko z powodu
generacyjnej utraty ale ponieważ negatyw dostarcza płynniejszej krzywej w zakresie
dynamicznym więc miejsca za jasne i cienie lepiej się przenoszą. Dodatkowe informacje
dostępne są w pracy magisterskiej Pani Anny Błażewicz [15].
W trakcie procesu gromadzenia do repozytorium trafiają nowe obiekty, aby była
możliwość ich odszukania należy je opisać. Celowi temu służą metadane. Metadane
w bibliotece cyfrowej powinny opisywać każdy obiekt. Zastosowane oprogramowanie
powinno pozwalać na łatwe konwertowanie metadanych pomiędzy różnymi standardami,
ponadto powinna być możliwość tworzenia osobnych szablonów lub formatów dla
nowych projektów. Różne typy obiektów wymagają różnych metadanych.
Metadane opisujące obrazy.
Do podstawowych metadanych opisujących obrazy należą :
- format pliku
- typ obrazu (bitmapa, rysunek wektorowy)
- kompresja
- wymiary
- metoda kodowania koloru (RGB, CMYK etc.)
- rozdzielczość koloru (głębokość koloru, luminacja etc.)
- kompletność (szczegół, całość, część)
Nieco inaczej wygląda proces archiwizacji danych dźwiękowych. Kopia o najwyższej
jakości (nie poddana stratnej kompresji) zostaje zachowana w archiwum, a wersje
w formatach real audio i/lub mp3 udostępnione są na stronach WWW.
Metadane opisujące pliki audio :
- częstotliwość samplowania (11kHz/s dla mowy, 44kHz dla muzyki o jakości CD)
- mono, stereo, kwadro czy inne.
- liczba ścieżek
- Format zapisu danych (.Mp3,.Wav, .Snd, .MID etc.)
Archiwizacja danych video
Podstawową wadą kompresorów video jest to iż kompresja jest zazwyczaj stratna.
Objawia się to w ten sposób, że materiał traci ostrość.
Biorąc pod uwagę, że absolutna wierność oryginałowi potrzebna jest tylko w studiach
filmowych należy rozważyć czy faktycznie potrzebujemy idealnej kopii. Większość
kodeków video jest w stanie kompresować dzisiaj obraz z jakością zbliżoną do
DVD przy kompresji rzędu 1:7.
Podstawowe metadane opisujące pliki video
- czarno-biały czy kolorowy
- głębia koloru
- ilość ramek przypadających na sekundę obrazu
- format zapisu (.Avi, .Mov, .etc)
- rozdzielczość
- częstotliwość dźwięku
- liczba kanałów audio
- kodek Audio
- kodek Video
Oczywiście parametrów charakteryzujących film jest dużo więcej, gdyż są to w
zasadzie wszystkie dane dotyczące obrazów i dźwięku połączone razem oraz parę
dodatkowych.
- przechowywanie
- formatowanie
- indeksowanie
Dane oraz metadane przechowywane są w repozytoriach. Repozytorium jest strukturą
opartą o bazę danych obsługującą język XML.
Metadane w bibliotece cyfrowej powinny opisywać każdy obiekt. Zastosowane oprogramowanie
powinno pozwalać na łatwe konwertowanie metadanych pomiędzy różnymi standardami,
ponadto powinna być możliwość tworzenia osobnych szablonów lub formatów dla
nowych projektów.
Jak już wspomniałem, prezentując model logiczny biblioteki cyfrowej, wyróżniamy
3 rodzaje metadanych :
- opisujące
- strukturalne
- administracyjne
Metadane opisujące to nic innego jak opisy bibliograficzne np. w MARC'u.
Metadane strukturalne to dane odnoszące się do prezentacji oraz nawigacji po
obiekcie cyfrowym, zawierające również informację o jego wewnętrznej organizacji.
Metadane administracyjne składają się z informacji, które potrzebne są, aby
repozytorium mogło zarządzać swoją cyfrową zawartością. Obejmują one :
- dane odnoszące się do utworzenia cyfrowego obiektu (data pozyskania, rozdzielczość,
itd.)
- dane pozwalające na identyfikację obiektu (wersja/wydanie) i pomagające ustalić
co jest potrzebne do przeglądania go lub użycia (miejsce przechowywania, typ
kompresji, nazwa pliku)
- informacje o prawie własności, prawach, itd.
Metadane administracyjne są bardzo ważne w przypadku długoterminowego zarządzania
obiektami, dobrze zaprojektowany schemat może procentować w przyszłości. Mogłoby
się zdarzyć, że w repozytorium znajdują się pliki zawierające istotne dane,
ale nie wiadomo jakim programem je przetworzyć, repozytorium powinno zawierać
informację o takim programie albo nawet sam program.
3.1.2 udostępnianie
- przeszukiwanie i wyszukiwanie
Coraz większa liczba systemów dostarcza, większej ilości atrybutów wyszukiwania.
Istnieje kilka metod wyszukiwań/przeszukiwań. Podstawowym z nich, najbardziej
prymitywnym jest wyszukiwanie sekwencyjne. Polega ono na przeglądaniu dokumentu
strona po stronie. Dzięki temu rodzajowi wyszukiwania redukujemy pierwszoplanowe
koszty indeksacji. Kolejną z metod, które możemy zastosować to podział materiału
na foldery i stopniowe ich zagnieżdżanie. Dodatkowo można stworzyć aliasy do
poszczególnych folderów. Aby wyszukiwanie było szybsze dane zaczęto zapisywać
w postaci rekordów w bazach danych. Zaindeksowane i poprawnie utrzymywane rekordy
pozwalają na ich bardzo szybkie wyszukiwanie. Mając bazę danych możemy, wykorzystując
jej właściwości stworzyć dodatkowe relacje i zastosować indeksy słów kluczowych.
Oznacza to wprawdzie dodatkową pracę dla personelu, ale znacznie polepsza trafność
i czas wyszukiwania. W tym wypadku musimy zwrócić uwagę aby system eliminował
synonimy. Aby było to możliwe być może należałoby zastosować wymóg wybierania
słów kluczy z wcześniej zatwierdzonej listy, zwanej listą kontrolowanego słownictwa.
Najbardziej zaawansowane metody wyszukiwania to wyszukiwanie pełnotekstowe i
wyszukiwanie rozmyte. Pozwalają one wykorzystywać różnego rodzaju maski typu
'*' (do zastępowania ciągów znaków) i '?' (do zastępowania pojedynczych liter).
Ponadto rozpoznawane są literówki, różne formy wyrazów i idiomy. Aby wyszukiwanie
to było bardziej pełne zastosowanych jest tu wiele wewnętrznych liczników słów.
Mówią one ile razy dane słowo występuje w tekście, jaka jest odległość między
poszczególnymi słowami w tekście, jaki jest porządek wyszukiwanych słów.
Możliwości biblioteki cyfrowej powinny obejmować wyszukiwanie : według autora,
tytułu, tematu, dobrą nawigację wśród zwróconych wyników, możliwość zastosowania
algebry boolowskiej, obsługę wyrażeń bliskoznacznych lub tematu wyrazów, wyszukiwanie
słów kluczowych w tytule, wyszukiwanie pełnotekstowe. Istotna jest również możliwość
używania określonych kombinacji wyszukiwania w zbiorze wyszukanych informacji
i używanie tezaurusa.
Z punktu widzenia użytkownika istotne jest aby mógł on w bardzo szerokim zakresie
modyfikować interfejs.
Bardzo ważną funkcją jest aby moduł, prócz trybu on-line , pracował również
w trybie wsadowym. Istotne jest to szczególnie w przypadku importu rekordów,
robieniu backup'u, czy aktualizacji dużych retrospektywnych rekordów bibliograficznych
i plików. Szczególnie jest to przydatne gdy serwer nie dysponuje zbyt duża mocą,
wówczas bardziej zasobochłonne zadania mogą być wykonywane nie w czasie rzeczywistym
tylko poza godzinami szczytu.
Jeśli sieć jest bardzo obciążona można podzielić bazę na tematy. Dla weryfikacji
poprawności rekordów w bazie danych wykorzystuje się różnego rodzaju słowniki.
Można również sprawdzać dane wprowadzane on-line przez użytkowników, niestety
aby móc to wykonywać efektywnie potrzebny jest dedykowany interfejs dla systemu
windows inny od tego który można uruchomić w przeglądarce. Powinna pojawić się
również możliwość przeszukiwania rozproszonego.
Najistotniejsze funkcje które powinny znaleźć się w module przeszukiwania to
funkcje importu, eksportu, sporządzania różnego rodzaju raportów oraz możliwości
zmian interfejsu użytkownika. Najpopularniejszym z formatów wymiany rekordów
są LCMARC i UKMARC. Przy ich pomocy można importować opisy bibliograficzne z
biblioteki kongresu.
Aby rozszerzyć możliwości wyszukiwania, biblioteka powinna mieć możliwość komunikacji
z innymi systemami. Można to zapewnić wykorzystując programy obsługujące protokół
Z30.50. Z drugiej strony na serwerze biblioteki powinien pracować program, udostępniający
opisy bibliograficzne zgromadzonych materiałów, światu. Szczegółowe informacje,
na temat protokołów wymiany informacji, można znaleźć w pracy Pani Agaty Hintz.
[]
- obsługa wielu języków
Bardzo istotnym czynnikiem w bibliotece cyfrowej jest obsługa wielu języków
zarówno w metadanych jak i w tekście. I tak wspierany powinien być pełny zakres
znaków ASCII i UNICODE . Problem obsługi wielu języków dotyczy większości powyższych
modułów / usług. Obsługa wielojęzykowości powinna zostać rozważona już na etapie
projektowania struktury bazy danych. Interfejsy służące do wprowadzania znaków
nie obejmowanych przez kod ASCII powinny udostępniać odpowiednie kroje czcionek
oraz być tak zaprojektowane aby można było w prosty sposób wprowadzać owe znaki.
Interfejsy poprzez które klient będzie otrzymywał dane powinny umożliwiać poprawne
wyświetlanie znaków nie romańskich. Przeglądarki Internet Explorer 5.1 i późniejsze,
wykorzystują kodowanie UTF-8 i w bardzo efektywny sposób radzą sobie z wyświetlaniem
znaków zakodowanych w Unikodzie. Jeśli nie jest to zaimplementowane rodzi się
pytanie jak jest to obsługiwane przez wyszukiwarkę i w jaki sposób zachowuje
się biblioteka jeżeli wyszukiwarka nie odbiera diakrytyków ?
- typy obsługiwanych obiektów
Spektrum obsługiwanych obiektów w bibliotece cyfrowej jest bardzo istotną cechą.
Biblioteka cyfrowa powinna obsługiwać możliwie dużo formatów, łącznie z formatami
objętymi ochroną prawną. Należy jednak zwrócić uwagę aby obiekty zachowane były
w formatach nie objętych takową. Obiekty, które powinny być obsługiwane przez
bibliotekę cyfrową należą do kilku kategorii :
obiekty tekstowe
Wśród obiektów tekstowych najważniejszymi formatami są :
- PDF
- ASCII
- HTML
- XML
-SGML
-Microsoft Word
obiekty graficzne
Najważniejszymi formatami są :
- TIFF
- JPEG
- GIF
- BMP
- PCD
- PCX
- PNG
obiekty dźwiękowe :
- MP3
- MIDI
- WAV
obiekty multimedialne :
- Real Audio
- MPEG
- AVI
- MOV
- QuickTime
Należy zwrócić uwagę aby była możliwość konwersji lub eksportu danych, do któregoś
z wyżej wymienionych formatów. Aby zapewnić dostęp do obiektów multimedialnych
należy dać do nich dostęp w sposób strumieniowy. Obsługę tego typu transmisji
powinien zapewniać serwer. Jeśli zasoby multimedialne znajdują się na odrębnym
serwerze musi być możliwość elastycznego tworzenia dowiązań do nich i weryfikacji
czy się nadal tam znajdują.
3.1.3 dostarczanie
Wynikiem wyszukiwania/przeszukiwania w trybie normalnym lub wsadowym są dane.
Biblioteka powinna zapewniać usługi dostarczania owych danych na różne sposoby.
Podstawowym sposobem jest przedstawianie wyników on-line, w oknie wyszukiwarki.
I z tego poziomu powinna się pojawić możliwość wysłania danych na określony
email lub serwer ftp, bądź w dedykowane miejsce do którego personel biblioteki
będzie miał dostęp aby nagrać przesłane dane na płytę CD. Taka sama gama możliwości
powinna być dostępna z poziomu przeglądanych konkretnych dla przykładu artykułów,
rozdziałów artykułów. Oczywiście jest to założenie czysto teoretyczne, gdyż
trzeba wziąć pod uwagę ochronę praw autorskich.
Istotne jest aby te wszystkie usługi były dostępne dla personelu biblioteki,
mam tu na myśli zlecenie wydawane personelowi przez klienta, który poszukuje
materiałów o określonej tematyce i prosi o dostarczenie ich na któryś z w/w
sposobów.
Nowym rodzajem danych, z którymi raczej nie spotykamy się w tradycyjnych bibliotekach
są dane multimedialne i sposób ich dostarczania. W przypadku biblioteki cyfrowej
po zlokalizowaniu zasobu o takim charakterze możemy uzyskać dostęp do niego
na dwa sposoby:
-"ściągnij i odtwórz"
-"rozpocznij ściąganie i zacznij odtwarzać"
Pierwszy przypadek jest typowy. Dostęp do zasobu możemy uzyskać, jeśli ten znajduje
się w całości na naszym lokalnym dysku, czyli czekamy na plik zawierający np.
animację, film, muzykę. Drugi przypadek jest o wiele ciekawszy, albowiem umożliwia
on odtwarzanie danych w czasie rzeczywistym. Ogólny schemat działania odtwarzacza
mediów strumieniowych wygląda następująco : rozpocznij ściąganie zasobu, jeśli
masz już wystarczającą ilość danych i łącze jest wystarczająco szybkie rozpocznij
odtwarzanie, a w tle ściągaj dalszą część. Protokołami odpowiedzialnymi za transmisje
w czasie rzeczywistym są RTP (Real-Time Transport Protocol), RTCP (Real-Time
Control Protocol), RTSP (Real-Time Streaming Protocol) może być również wykorzystywany
protokół RSVP (Resource Reservation Protocol). Rola RTP to identyfikacja przenoszonych
danych, numerowanie sekwencji oraz umieszczanie znaczników czasowych. RTCP analizuje
stan połączenia i na podstawie zebranych informacji steruje wydajnością dostarczania
nowych porcji informacji. RTSP przesyła strumień multimedialny techniką unicast
lub multicast. Sposób tworzenia strumienia polega na podziale danych na pakiety
o odpowiedniej wielkości (zależnej od dostępnego pasma). Dane mogą być dostarczane
w oparciu o protokoły TCP, UDP, IP Multicast lub RTP. Dzięki RSVP możliwe jest
zarządzanie sesjami przesyłania strumieni i rezerwacja pasma. RTP wspiera synchronizację
i QoS .
Najbardziej znanymi dostawcami programowych serwerów i odtwarzaczy mediów strumieniowych
są firmy : RealNetworks i Microsoft. RealNetworks jest producentem serwera RealServer
G2, odtwarzacza RealPlayer (ostatnio udostępniony został odtwarzacz RealOne)
i kodera przekształcającego dane audio i video na format RealMedia nazywanego
RealProducerem. RealServer obsługuje strumieniowo, nie tylko pliki .rm ale także
: ASF (Advanced Streaming Format), Vivo, AIFF, AU, WAV, AVI i QuickTime. Jakby
tego było mało serwer obsługuje dodatkowe standardy prezentacji :
- RealText - umożliwia uzupełnienie multimedialnych transmisji o napisy
- RealPix - umożliwia przesyłanie statycznych, wolno zmieniających się obrazów
- RealFlash - umożliwia łączenie i synchronizowanie animacji Flash z przekazem
dźwiękowym i video
- Pliki zdarzeń - umożliwiają synchronizowanie RealPlayer'a z przeglądarką.
Oprogramowanie w podstawowej wersji dostępne jest za darmo, możliwa jest wtedy
obsługa do 25 strumieni danych jednocześnie. Ponad to, system jest wieloplatformowy,
istnieją wersje dla system Mac, Windows i wielu platform unixowych.
System obsługujący media strumieniowe Microsoftu nazywa się Windows Media Technologies.
Do wyświetlania strumienia danych potrzebny jest program Windows Media Player,
tak samo jak w przypadku RealNetworks serwer i koder. Obsługiwane formaty to
ASF, RealAudio, RealVideo i inne. System Microsoftu pozwala na zabezpieczanie
plików przed piractwem, polega to na ich szyfrowaniu. Do odtworzenia wymagany
jest klucz licencyjny. Największą wadą systemu Microsoftu jest ograniczenie,
tylko i wyłącznie do środowiska Windows, tak po stronie klienta jak i po stronie
serwera.
- urządzenia dostępowe
Rozpatrując temat dostarczania należy zwrócić uwagę na urządzenia, których będą
używać klienci aby korzystać z zasobów biblioteki. Mogą nimi być :
- standardowe stacje robocze
- ebooki
- palmtopy
- telefony komórkowe
- palmtopy z bezprzewodowym dostępem do Internetu
Nie każde z tych urządzeń musi koniecznie służyć jako urządzenie do przeglądania
zawartości biblioteki, niektóre z nich mogą pełnić pewne funkcje pomocnicze.
Istnieje zatem potrzeba umożliwienia dostępu każdemu z tych urządzeń do zawartości
lub usług biblioteki. Standardowa stacja robocza (komputer klasy PC), może dysponować
wszystkimi możliwościami. Biblioteka jest projektowana pod kątem dostarczania
informacji dla klientów wykorzystujących głównie urządzenia tego typu, stąd
rodzi się potrzeba rozpoznawania urządzeń pozostałych typów i dostarczania im
informacji w odpowiednim formacie. Należy jednak zwrócić uwagę, że niektóre
z urządzeń są tak ubogie pod względem technicznym, że niektóre z usług nie będą
dla nich dostępne. Osobne serwisy i dodatkowa infrastruktura informatyczna wymagane
będą dla klientów korzystających z urządzeń bezprzewodowych, takich jak ebooki,
palmtopy, telefony komórkowe, wykorzystujących sieci komórkowe, przewodowe lub
bezprzewodowe. Aby interaktywna komunikacja przez sieć komórkową była możliwa
należy skorzystać z protokołu WAP (Wireless Application Protocol). Komunikacja
przewodowa możliwa jest przez modemy lub bezpośrednie podłączenie do sieci np.
Ethernet. Natomiast komunikacja przez komputerowe sieci bezprzewodowe możliwa
jest dzięki zastosowaniu podczerwieni, technologii Bluetooth lub innych sieci
opartych o protokół 802.11b.
Inną formą udostępniania, różnego rodzaju, informacji może być ich export i
udostępnianie np. na płytach CD. Bardzo dużą pomocą w takich sytuacjach są programy
typu "Web to EXE" zadaniem ich jest konwersja zbiorów plików HTML
do pojedynczego pliku EXE. Jakie możliwości mają tego typu aplikacje opiszę
na przykładzie programu WebExe 1.4 firmy aw-soft. Podstawowe zalety :
- nie wymagają dodatkowego oprogramowania do uruchomienia pliku exe
- funkcje typu kopiuj, szukaj, drukuj lub zapisz mogą zostać wyłączone
- można ustawić hasło dostępu
- można ustawić datę wygaśnięcia dokumentu
- możliwość przeszukiwania pełnotekstowego
- wszystkie pliki są kompresowane algorytmem ZIP (redukcja zawartości nawet
do 50%)
- wyświetlana zawartość jest ładowana do pamięci i z niej bezpośrednio wyświetlana,
nie są tworzone tymczasowe pliki na dysku
- zintegrowana przeglądarka wspiera większość specyfikacji języka HTML 3.2,
wiele rozszerzeń języka HTML 4 i różne właściwości kaskadowego arkusza stylów
(CCS)
- elektroniczna pomoc przy tworzeniu kolekcji
- wsparcie dla wielu języków
- Podstawowe wady :
- z uwagi na bezpieczeństwo danych, nie jest to rozwiązanie nadające się do
publikacji pełnotekstowych
- brak obsługi języka polskiego
- są dedykowane dla systemu operacyjnego Windows
Jest to bardzo ciekawe rozwiązanie, niestety na platformę PC nie ma programów,
które w 100% chroniłyby swoją zawartość i stworzenie takowych jest niemożliwe.
- bezpieczeństwo dostarczania
Zabezpieczenie środowiska pracy przed ingerencją z zewnątrz jest bardzo ważne.
Trzeba zwrócić również uwagę aby system biblioteczny nie mógł zaszkodzić żadnym
systemom zewnętrznym. Dla przykładu, usługa dostarczania nie powinna pozwalać
na zalewanie masową korespondencja obcych, złośliwie lub przez nieuwagę podanych,
adresów kont pocztowych. Ta sama uwaga odnosi się do kont ftp.
- ochrona
Celem ochrony w module udostępniania jest zabezpieczenie przede wszystkim interesów
autorów udostępniających swoje dzieła i wykorzystujących do tego celu bibliotekę
cyfrową. Ochrona w tym znaczeniu powinna :
- uniemożliwić niepowołanym użytkownikom dostęp do materiałów cyfrowych
- uniemożliwić lub ograniczyć w stopniu maksymalnym określonym grupom użytkowników
robienie kopii materiałów ze stron biblioteki,
- znakować materiały.
Zanim napiszę coś więcej o metodach zabezpieczania przed nieuprawnionym kopiowaniem,
chciałbym nadmienić, iż nie ma metod idealnych. Każdą z zastosowanych technologii
można obejść w jakiś mniej lub bardziej wyrafinowany sposób. Przy każdej z metod
wspomnę o sposobach jej obejścia.
Aby zabezpieczanie interfejsu udostępniania biblioteki cyfrowej miało sens
trzeba spełnić parę ogólny warunków odnoszących się generalnie do bezpieczeństwa
WWW :
- serwer(y) na których pracuje biblioteka musi być odporny na różnego rodzaju
ataki
- serwer(y) powinny zapewniać usługi uwierzytelniania siebie jak i klientów.
- jedno hasło i jedna nazwa użytkownika powinna być dostępna na każdym z serwerów
- jeśli jest firewall te same protokoły powinny być przed nim jak i za nim
- udostępniać usługi pozwalające szyfrowane połączenia do niego.
- serwer WWW zainstalowany na serwerze musi obsługiwać SSL (Secure Socket Layer).
- język programowania, użyty w interfejsie udostępniania musi zapewniać bezpieczeństwo.
- sposób napisania aplikacji webowych nie powinien dawać możliwości łatwego
nadużywania możliwości systemu (system często sprawdzanych haseł, weryfikowania
adresów ip, 'bezpieczny' styl programowania etc.),
- zachowanie użytkowników powinno być monitorowane.
Ataki, których możemy się spodziewać to przede wszystkim ataki : na serwer,
na aplikacje webowe oraz ataki pośrednie. Możemy wyróżnić także ataki mające
na celu zakłócenie pracy serwera. Do takich należą ataki typu DoS (Denial of
Service) lub DDoS(Distributed Denial of Service).
Ataki na serwer polegają na wykorzystaniu luk w jego zabezpieczeniach i wykonaniu
odpowiedniego kodu, który umożliwi włamywaczowi pełen dostęp do atakowanego
systemu. Uwagę należy zwrócić na poprawne zainstalowanie aplikacji, zainstalowanie
wszystkich uaktualnień systemu oraz przyjąć zasadę ograniczonego zaufania, udostępniać
możliwe mało usług, regularnie przeglądać logi systemu.
Ataki na aplikacje webowe wykorzystują fakt występowania błędów, które pozostawili
projektanci. Szczególnie należy zwrócić uwagę na :
-weryfikowanie danych otrzymywanych od klienta w formularzach, nigdy nie należy
im ufać !
-usunięcie z systemu niezabezpieczonych, tylko "nam" znanych, tylnych
wyjść
-nie przekazywanie, istotnych parametrów w adresach URL
-kontrolowanie cookies
-zabezpieczenie wejścia, w taki sposób aby przez wykonywanie skryptów CGI nie
było możliwe wykonywanie operacji niepożądanych.
-możliwość przepełnienia bufora przez atakującego
-każdorazową weryfikację dostępu do stron chronionych hasłem, niekoniecznie
jawną
Ataki pośrednie dokonywane są nie bezpośrednio na port HTTP tylko na porty przypisane
innym usługom np. SMTP, FTP, SSH lub DNS.
Podstawową ochroną serwerów powinno być stosownie poprawnie skonfigurowanych
zapór ogniowych i systemów wykrywania wtargnięć. Do bardziej wyrafinowanych
technik można zaliczyć :
-wyjścia kontrolowane
-pułapki
-stosowanie urządzeń separujących
-systemy samonaprawcze
-systemy monitorujące ruch i odpierające ataki typu DoS
Większe bezpieczeństwo transmisji może zagwarantować nam następca protokołu
IP protokół IPv6. Bezpieczną wymianę informacji, pomiędzy klientem a serwerem,
zapewniają dedykowane protokoły.
Jednym z nich jest S-HTTP (Secure-HTTP) umożliwia on bezpieczną wymianę informacji
niestety tylko wykorzystując HTTP. Ponad to S-HTTP nie jest standardem.
Kolejnym z zabezpieczeń jest "nakładka" na TCP/IP zwana SSL (Secure
Socket Layer), dzięki temu bezpiecznie transportowane mogą być strony WWW, emaile
i newsy. SSL wykorzystuje certyfikaty X.509, zatem jest skalowalny do wielkości
Internetu. Nie jest to niestety standard Internetowy. Właścicielem referencyjnej
implementacji SSL jest firma Netscape ona też udziela na nią licencji. Dla instytucji
niekomercyjnych licencja ta jest bezpłatna. Jeśli SSL zostanie wyparte przez
inny protokół z pewnością będzie on bazował na rozwiązaniach SSL'a.
Jeszcze innym z zabezpieczeń jest SST (Secure Transaction Technology). Protokół
ten jest przeznaczony do prowadzenia bezpiecznych zakupów w Internecie. Został
on włączony do ogólniejszego protokołu PCT.
Kolejnym z protokołów jest PCT (Private Communication Technology) opracowany
tak samo jak SST przez firmy Microsoft i VISA bazuje na SST poszerzonym o cechy
protokołu SSL. Czyli jest zgodny "w dół" z SSL'em. Dokumentacja do
PCT jest udostępniana bezpłatnie. PCT nie jest standardem Internetowym.
Jeśli powyższe warunki mamy spełnione i posługujemy się którymś z wymienionych
protokołów, możemy przyjrzeć się zabezpieczeniom stosowanym przed nieuprawnionym
kopiowaniem.
Pierwsze z zabezpieczeń gwarantuje nam serwer, który ma włączone szyfrowanie
informacji, na linii przeglądarka użytkownika serwer. Gdyby szyfrowanie nie
było włączone wszystkie dane mogą zostać śledzone i zapisane dzięki wykorzystaniu
programów monitorującym ruch w sieci.
Kolejne z zabezpieczeń to modyfikacja interfejsu aby nie można było zapisywać
stron WWW. Osiągnąć to można dzięki odpowiednim programom napisanym w javascripcie.
Zabezpieczenia te nie są nigdy doskonałe i dokładniejsze przyjrzenie się działaniu
kodu w javascripcie pozwala na znalezienie jego potencjalnie słabych punktów.
Trudno mi w tym momencie mówić dokładnie o metodach obejścia, gdyż tyle ile
implementacji tego typu zabezpieczeń tyle może być metod obejścia.
Kolejne z zabezpieczeń może być rozszerzeniem zabezpieczenia powyższego. Polega
ono na czasowym blokowaniu przeglądanych, np. przeglądanych stron książki, w
przypadku zbyt "szybkiego czytania". Metodą obejścia tego rodzaju
zabezpieczenia jest napisanie prostego programu, który będzie automatycznie
z zadanym opóźnieniem "przerzucał strony książki" i zapisywał obrazy
poszczególnych stron lub ich źródła na dysk twardy.
Gotowe rozwiązanie oferuje firma Moonlight Software, która jest autorem programu
WebCrypt Pro. Program ten pozwala na "szyfrowanie" kodu HTML. Kod
HTML, który dzięki temu powstaje jest "zabezpieczony" przed oglądaniem,
rysunków umieszczonych na stronie WWW nie można zapisać na dysk (w standardowy
sposób), zapisanie pełnej strony na dysk jest niemożliwe, popup toolbar w Internet
Explorerze 6 jest wyłączany, nie ma możliwości zaznaczania tekstu i wydruku
strony. Mechanizmy wykorzystane w tym oprogramowaniu opierają się w całości
na javascripcie. Wygenerowany "zaszyfrowany kod" jest faktycznie zapisem
szesnastkowym "szyfrowanej strony" wzbogaconym o wyżej wymienione
blokady. Tego typu zabezpieczenia nie stanowią żadnej przeszkody dla bardziej
wprawnych użytkowników.
Z uwagi na to, iż najcenniejszy dla użytkowników jest tekst, który można poddawać
w prosty sposób edycji, można pokusić się o generowanie w czasie rzeczywistym
obrazów tekstu. W tym momencie jest on czytelny, ale zupełnie nie nadaje się
do obróbki edytorem tekstu. Oczywiście mając wygenerowane w ten sposób rysunki,
można posłużyć się w tym momencie programem OCR, ale narzut czasowy związany
z tym jest duży. Aby utrudnić, ewentualne próby ekstrakcji tekstu programami
OCR, można generować obrazy tekstu, które są nałożone na inne obrazy.
Ostatnią z metod, która jest według mnie metoda najdoskonalszą, jest implementacja
appletu javy, przez który można przeglądać zawartość biblioteki. Jest to metoda
bardzo podobna do metody powyższej ale znacznie mniej obciążająca serwer i nie
pozwalająca na zachowywanie tekstu, poprzez zapisywanie źródła strony.
Wszystkie z powyższych metod zabezpieczania zawartości biblioteki można obejść
w prosty sposób zrzucając zawartość ekranu. Przed tym niestety uchronić się
nie możemy.
Komercyjnym rozwiązaniem w dziedzinie blokowania plików i dystrybucji kluczy
jest Adobe Content Server2. Pozwala on na komercyjną dystrybucję plików PDF.
Cena takiego systemu to 5000$ za oprogramowanie oraz 3% tantiemy za każdy sprzedany
plik przy pomocy tego systemu. Zasadniczymi wadami systemu jest to, że można
go używać tylko z plikami PDF, wymaga dodatkowego serwera, pracuje na platformie
windows i MS IIS oraz generuje wysokie koszty.
Znakowanie materiałów typu obrazy, dźwięk i dane video udostępnianych w bibliotece
cyfrowej jest możliwe dzięki znakom wodnym. Technika ta została wprowadzona
w roku 1996 przez firmę IBM, algorytm znakowania gwarantuje wysoki poziom :
- przezroczystości
- niezawodności
- przetrwalności
- bezpieczeństwa
Oznakowanie, tego typu jest dokonywane w sposób uniemożliwiający jego usunięcie,
nie przeszkadza przy oglądaniu materiałów i umożliwia szybką identyfikację w
przypadku skopiowania takiego zasobu. Znaku wodnego nie można usunąć poprzez
przetworzenie lub zniekształcenie polegające np. na kompresji, zmianie rozdzielczości,
obrót obcięcie.
Inną metodą znakowania jest steganografia. Polega ona na ukrywaniu jednego rodzaju
informacji w innej np. w obrazach można ukrywać teksty, znaki graficzne itd.
- Autoryzacja
Niebagatelną rolę w bibliotece cyfrowej odgrywa autoryzacja użytkowników zwana
również uwierzytelnianiem. Uwierzytelnianie oznacza ustalanie, czy osoba próbująca
uzyskać dostęp do określonych zasobów jest faktycznie tą, za którą się podaje.
Dzięki uwierzytelnieniu możemy oferować różne typy dostępu do zawartości i usług
oferowanych przez dane miejsce WWW. Kiedy już ustalimy kim jest użytkownik możemy
udostępnić mu zasoby do których ma prawa. W zależności od informacji dostarczanej
przez dane miejsce WWW potrzeba mniej lub bardziej wyszukanych mechanizmów autoryzacji.
Istnieje parę metod pozwalających na uwierzytelnienie użytkownika w bibliotece
cyfrowej:
-metoda login, hasło
-hasło maskowane - różni się tym od powyższej metody, że podczas wprowadzania
nie podaje się całego hasła a tylko wybrane jego znaki
-token - Token jest spersonalizowanym urządzeniem kryptograficznym. Przypomina
zwykle swoim wyglądem kieszonkowy kalkulator lub breloczek do kluczy. Zadaniem
tokena jest generowanie jednorazowych haseł (kodów), których system wymaga do
identyfikacji klienta i potwierdzania operacji dokonywanych przez Internet.
Token jest najczęściej zabezpieczony przed użyciem przez osoby niepowołane -
do jego aktywacji potrzebne jest podanie kodu. Wymagany jest on szczególnie
dla tych użytkowników bankowości internetowej którzy chcą np. wysyłać przez
Internet polecenia przelewu na dowolne, niezapisane wcześniej w systemie, rachunki
bankowe. Token zaliczany jest do sposobów tzw. silnego uwierzytelniania.
-metody biometryczne :
-odcisk palca
-geometria twarzy, dłoni itp.
-głos
-obraz tęczówki, siatkówki
-sposób pisania
-następujące protokoły zdalnego uwierzytelniania, zainstalowane w ścianach ogniowych,
dają bezpieczny dostęp do wewnętrznych zasobów upoważnionym użytkownikom :
-RADIUS
-TACACS
-LDAP
-PAP/CHAP
-Kerberos
-Domeny NTLM
-karty kodów - metoda polega na losowym wygenerowaniu dla każdego z klientów
listy haseł, które będą wykorzystywane przy autoryzacji transakcji. Jedna z
list haseł znajduje się na serwerze, drugą z list otrzymuje klient w postaci
wydrukowanej. Przy logowaniu się system pyta o kolejne hasło z listy. Po wykorzystaniu
listy haseł, dostawca usługi generuje nową listę i dostarcza ją klientowi
System wymiany dokumentów pomiędzy personelem biblioteki cyfrowej powinien odbywać
się z wykorzystaniem podpisu elektronicznego - wg PN-I-02000 (Polska Norma).
Podpisem elektronicznym jest : "Przekształcenie kryptograficzne danych
umożliwiające odbiorcy danych sprawdzenie autentyczności i integralności danych
oraz zapewniające nadawcy ochronę przed sfałszowaniem danych przez odbiorcę."
Cztery główne warunki podpisu cyfrowego:
- uniemożliwienie podszywanie się innych pod daną osobę (uwierzytelnienie osoby,
autentyfikacja),
- zapewnienie wykrywalności wszelkiej zmiany w danych transakcji (integralność
transakcji),
- zapewnienie niemożliwości wyparcia się podpisu przez autora,
- umożliwienie weryfikacji podpisu przez osobę niezależną.
W podpisie cyfrowym potrzebna jest para kluczy (publiczny i prywatny). Klucz
prywatny zna tylko użytkownik i od bezpieczeństwa tego klucza zależy bezpieczeństwo
wszystkich operacji wykonywanych przy pomocy pary tych kluczy. Klucz publiczny
jest jawny przy jego pomocy tworzony jest podpis cyfrowy. Podpis elektroniczny
jest generowany i weryfikowany następująco :
Wszystkie dane operacji są formatowane w ciąg bitów. Na podstawie tych danych
algorytm haszujący generuje krótką wartość hash. Następnie ta krótka wartość
hash jest szyfrowana za pomocą klucza prywatnego użytkownika. Zaszyfrowana w
ten sposób wiadomość jest podpisem cyfrowym danej transakcji. Operacja ta powinna
odbywać się na komputerze użytkownika, a następnie dane operacji powinny trafić
na serwer. Na serwerze następuje weryfikacja prawdziwości podpisu. Na podstawie
sformatowanych danych generowany jest hash A. Podpis cyfrowy jest odszyfrowywany
za pomocą klucza publicznego użytkownika. Otrzymana wiadomość to hash B. Jeśli
obie wartości są równe to podpis jest prawidłowy.
Aby uniknąć podszywania się pod inne osoby poprzez generowanie nowych kluczy
publicznych wykorzystuje się mechanizm "certyfikatów cyfrowych". Certyfikat
cyfrowy to blok danych zawierający klucz użytkownika oraz potwierdzenie, jakim
jest podpis elektroniczny, jego autentyczności przez osobę trzecią. Certyfikaty
wydawane są przez urzędy certyfikacji. Wszelkie modyfikacje, w danych które
są przedmiotem transakcji są wykrywane, co zapewnione jest dzięki algorytmowi
haszującemu. Zaszyfrowanie wartości hash uniemożliwia zmianę transakcji jak
i odpowiadającego jej podpisu.
Elementem narażonym na największe niebezpieczeństwo w systemach wykorzystujących
podpis cyfrowy jest klucz prywatny. Zdobycie jego pozwala na podszywanie się
pod właściciela. Aby takim sytuacjom zapobiec stosuje się kryptograficzne karty
elektroniczne, posiadają one zapisany wewnątrz klucz, a samo generowanie podpisu
następuje wewnątrz procesora karty. Każde użycie karty wymaga podania hasła.
Klucze publiczne stosuje się w wielu protokołach o które opiera się bezpieczny
transfer danych w Internecie : SSL (Secure Socket Layer), S/MIME (Secure MIME),
SET(Secure Electronic Transaction) oraz w podpisywaniu appletów Javy.
Generalnie metody uwierzytelnień możemy podzielić na dwie kategorie :
- proste uwierzytelnianie
- silne uwierzytelnianie
Proste uwierzytelnianie odpowiada uwierzytelnianiu wykorzystywanemu w systemach
komputerowych i polega ono na podaniu identyfikatora użytkownika i hasła.
Silne uwierzytelnianie opiera się na tym co użytkownik posiada, tzn. tokeny,
karty kodów jednorazowych, karty chipowe i magnetyczne. Silne uwierzytelnianie
jest często połączone z prostym.
Istnieją również systemy bibliotek cyfrowych, które nie wymagają autoryzacji
zwykłych użytkowników. Przykładem takiego systemu jest GreenStone. Autoryzacja
login, hasło jest wymagana dla użytkowników zarządzających kolekcjami obiektów.
3.1.4 odpłatności
Wykorzystując system mikropłatności można w prosty sposób pobierać opłaty za
różnego rodzaju usługi oferowane na stronach WWW. Opłaty w ogólności można pobierać
za wszystko, poczynając od wejścia na stronę, wyszukiwanie, przeglądanie do
wyspecjalizowanych usług. Najniższą opłatą w przypadku Polski jest jeden grosz.
System mikropłatności jest na razie na całym świecie w fazie zaawansowanego
eksperymentu, ale w przyszłości będzie już to bardzo popularna, jeśli nie najpopularniejsza,
forma płatności cybercashem. W Polsce próbuje wdrożyć go firma eCard, stworzona
przez ComputerLand, BRE Bank i Wielkopolski Bank Kredytowy.
Witryna, która chce sprzedawać swoje produkty wykorzystując system mikropłatności
powinna zainstalować aplikację dzięki której można realizować sprzedaż przez
Internet. A firma eCard udostępnia oprogramowanie integrujące aplikację sprzedaży
z systemem mikropłatności. Napisanie witryny wykorzystującej system mikropłatności
nie jest niczym skomplikowanym. Aby skorzystać z systemu mikropłatności jako
usługobiorca jedyne co trzeba zrobić to założyć mikrokonto i wpłacić na nie
np. kilkadziesiąt złotych. Od tego momentu można dokonywać zakupów na witrynach
zintegrowanych z systemem eCard.
Jak wygląda dokonywanie zakupów w systemie korzystającym z mikropłatności ?
Klient wchodząc na stronę deklaruje chęć dokonania zakupu, zostaje przeniesiony
na stronę mikropłatności eCardu. Jeśli ma konto wprowadza identyfikator i hasło.
Potwierdza informację o aktualnym stanie konta, listę wybranych towarów oraz
kwotę należności. Akceptuje transakcję, system zdejmuje z konta określoną sumę
i księguje ją na koncie strony
Rys. 3.3
gdzie klient dokonał zakupu. I wysyła do serwisu informację, że transakcja została
zrealizowana (klient zapłacił). Jak dobywa się transakcja przedstawia Rys. 3.3.
eCard pobiera prowizję od realizowanych transakcji, jej wysokość jest zależna
od miesięcznych obrotów na witrynie.
3.2 oprogramowanie
3.2.1 funkcje oprogramowania klienta
Oprogramowanie do którego dostęp ma klient ma za zadanie ułatwiać nawigację
w zbiorze danych znajdujących się w bibliotece cyfrowej. Jego podstawową funkcją
jest wyszukiwanie/przeszukiwanie oraz ułatwienie przeglądania znalezionego materiału.
Dodatkową funkcjonalnością mogą być możliwości :
- kopiowania zaznaczonych fragmentów materiałów do innych lokalizacji
- znakowania materiałów (wirtualne notatki na marginesie, zakładki)
- informowania innych użytkowników o znalezionych materiałach
- transformacji materiałów do formy nadającej się do bezpośredniego wydruku
(PDF)
- dokładnej analizy materiałów (np. starodruków, map itd.)
- dostępu do listy dyskusyjnej biblioteki
- zaznaczania fragmentów tekstów i nawigacja pomiędzy nimi lub późniejsze grupowe
przeglądanie
- przeglądania kilku książek równocześnie
- sprawdzenia zaznaczonego słowa w słowniku np. języka polskiego, języków obcych
- informowania o książkach o podobnej tematyce dostępnych w bibliotece cyfrowej
lub tradycyjnej
- szybkiego sprawdzenia listy książek autora właśnie czytanej książki
- sprawdzenia swojej wiedzy poprzez udostępnione np. testy
- wykorzystania syntezatora mowy
- hibernacji sesji, polegającej na zapisaniu aktualnego "stanu ekranu"
użytkownika i odzyskiwaniu go np. po określonym upływie czasu lub na innej maszynie
- i inne
Docelowa lista funkcjonalności będzie zależeć od potrzeb klientów.
3.2.2 funkcje oprogramowania zarządzającego
- edycją i gromadzeniem
Ponieważ, nie każdy rodzaj materiału, który jest w postaci cyfrowej nadaje się,
od razu, do składowania, musi on zostać poddany określonym procesom normalizacji/kompilacji.
Dla przykładu, dokumenty programu Microsoft Word, muszą zostać przetworzone
do postaci XML'a. Skanowane materiały należy poprawić a następnie nałożyć na
nie znaki wodne. Prezentacje multimedialne składane z różnego rodzaju materiałów,
każdy z nich wymaga osobnej obróbki, by następnie dokonać kompilacji wszystkiego
do jednego pliku. Zabiegi te niestety wykonuje się używając licznych zewnętrznych
narzędzi (edytorów XML'a, programów graficznych, koderów medii strumieniowych,
programów do znakowania). W wyniku otrzymujemy dane, w postaci pliku/plików
które należy umieścić w odpowiednim repozytorium, przypisać do kolekcji i skatalogować.
I właśnie to jest to, co można zrealizować przez moduł gromadzenia.
- tworzeniem i udostępnianiem
Celem tego modułu było umożliwienie tworzenia i pielęgnacji obiektów. Pod pojęciem
pielęgnacji należy rozumieć możliwość ingerowania w treść którą zawiera obiekt.
- monitorowaniem, logowaniem i statystykami
Monitorowanie pozwala na nadzorowaniu, w czasie rzeczywistym, szeregu parametrów
np.:
- ogólnych :
- ile klientów w danym momencie korzysta z biblioteki z podziałem na gości,
zwykłych użytkowników, personel i administratorów
- jak bardzo jest obciążony system (dostępna wolna pamięć, obciążenie procesora)
- dotyczących obiektów :
- które obiekty są właśnie przeglądane
- jak długi czas jest poświęcany na oglądanie danego obiektu
- dotyczących klientów :
- skąd dany klient się łączy
- czego klient szuka
- jakiej klient używa przeglądarki
- czy klient usiłuje kopiować tekst
Logowanie odpowiada za zapisywanie przykładowych wyżej wymienionych parametrów
i generowanie na ich podstawie okresowych statystyk.
- moduł zarządzania obiektami
Moduł powinien pozwalać na elastyczną prezentację obiektów używając szablonów
przypisanych do kolekcji lub indywidualnych grup. Organizowanie obiektów powinno
obejmować możliwości przypisania ich do różnych grup i kolekcji, jak również
łączenie wielu obiektów w jeden abstrakcyjny obiekt. Moduł zarządzania obiektami
powinien również pozwalać na ustalanie praw dostępu do obiektów tj. praw :
-odczytu
-tworzenia
-modyfikacji
-usuwania
w odniesieniu do grup użytkowników którzy próbują uzyskać dostęp do niego. W
zależności od stosowanych przez narzędzi powyższe prawa dostępu mogą mieć inny
charakter. Moduł powinien obsługiwać funkcję wyszukiwania duplikatów obiektów
w bazie danych.
- moduł zarządzania użytkownikami
Każdy z użytkowników :
- posiada swój identyfikator i hasło
- należy do jednej lub wielu grup
- posiada swój profil
Hasło i identyfikator jednoznacznie identyfikują użytkownika w systemie, na
ich podstawie użytkownik otrzymuje identyfikatory grup do których należy.
Przynależność do grupy determinuje dostęp do obiektów należących do różnych
grup i kolekcji, przy czym dostęp oznacza tu prawa do odczytu, modyfikacji,
uruchamiania. Profil zawiera ustawienia przypisane danemu użytkownikowi, mogą
być przez niego modyfikowane. Uruchamiając ten moduł będzie możliwość edytowania
wyżej wymienionych parametrów : użytkowników i grup użytkowników. Tu można też
zdefiniować listę adresów IP z których dostęp do zasobów biblioteki będzie zabroniony,
jak i listę adresów z których będzie dostęp na konto gość (nie będzie wymagane
podanie hasła) oraz czas bezczynności po jakim użytkownik jest automatycznie
wylogowywany. Moduł ten też umożliwia komunikację personelu biblioteki z użytkownikami.
- moduł zarządzania usługami
Dzięki temu modułowi, personel biblioteki, ma możliwość dawać lub odbierać prawa
użytkownikom i grupom użytkowników do określonych usług np. korzystania z bibliotecznej
listy dyskusyjnej, możliwości robienia wirtualnych notatek czy wkładania wirtualnych
zakładek.
3.3 projekt
3.3.1 implementacja projektu i języki programowania
Bardzo popularną metodą programowania jest programowanie zorientowane obiektowo
- OOD (Obiect Oriented Design). W programowaniu obiektowym tworzymy obiekty,
które są instancjami wcześniej zaprojektowanych klas. Klasy w naszym przypadku
będą nazwami materiałów przechowywanych w bibliotece. Klasami np. mogą być :
skrypty, mapy, czasopisma etc. Klasy mają "zawartość". Zawartością
mogą być pola klasy np. liczba stron skryptu, jak również obiekty innych klas.
Np. klasa skrypt zawiera obiekty klasy rozdział. Klasy mogą posiadać własne
metody, które określają czynności, które możemy wykonywać na obiektach danej
klasy. Np. posiadając obiekt o nazwie "programowanie_w_javie" klasy
książka możemy wywołać (wcześniej zaimplementowaną metodę) wyświetl_stronę(nr_strony).
Tak będzie wyglądać kompletne wywołanie metody aby wyświetlić stronę 30 : programowanie_w_javie.wyświetl_strone(30).
Zaletą takiego podejścia jest możliwość stosowania różnych metod do różnych
klas obiektów oraz możliwość wykorzystania wcześniej napisanych komponentów
co czyni tworzenie nowych modułów dużo szybszym i łatwiejszym.
Najniższą warstwę na której się wszystko opiera w bibliotece cyfrowej stanowi
baza danych. Aby komunikacja baza danych-użytkownik była możliwa potrzebny jest
interfejs dostępu do niej. Interfejs może być stworzony dla wielu systemów operacyjnych.
Aby zapewnić przenośność, dostęp do biblioteki będzie odbywał się głównie przy
pomocy przeglądarki sieciowej. Obecnie na rynku istnieje bardzo wiele języków
dzięki którym można stworzyć poprawnie działające interfejsy. Języki takie możemy
podzielić na 2 grupy języki kompilowane i języki interpretowane. Do języków
interpretowanych należą : PERL, PHP, ASP, VBScript, Python i inne. Języki kompilowane
to : C, Java i inne. Językiem który zasługuje na szczególną uwagę i który, z
uwagi na cechy, które zaraz wymienię, wydaje mi się być idealnym do zastosowań
typu biblioteka cyfrowa jest Java.
Pierwszą z cech i wydaje mi się najważniejszą z cech języka Java jest bezpieczeństwo.
Drugą niezależność od platformy sprzętowej. Trzecią obiektowość, a co za tym
idzie elastyczność, która z kolei wpływa na szybkość tworzenia zaawansowanych
projektów. Czwartą wsparcie interfejsów programistycznych języka XML. Minusem
Javy jest mała szybkość wykonywania kodu programów w niej napisanych. Wynika
to z tego, iż kod jest tłumaczony na formę pośrednią, dzięki której może on
być wykonywany na każdej platformie sprzętowej. W przyszłości prędkość wykonywania
programów javy zapewne znacznie wzrośnie. Wyniknie to bezpośrednio z postępu
technologicznego jak i powstania dedykowanych rozwiązań sprzętowych.
W zależności od zastosowań Javy do dyspozycji mamy jej trzy wydania :
- Java 2 Platform, Standard Edition (J2SE) - dla stacji roboczych i komputerów
biurowych
- Java 2 Platform, Micro Edition (J2ME) - dla urządzeń typu pagery, telefony
komórkowe, systemy PDA (Personal Digital Asistant)
- Java 2 Platform, Enterprise Edition (J2EE)- dla aplikacji działających na
serwerze
J2EE zawiera bardzo ważne API dzięki którym można budować potężne aplikacje,
należą do nich :
- Java Server Pages(JSP)
- Java Database Connection (JDBC)
- Java XML
- Java Servlets
- Enterprise JavaBeans
- Java Transaction API (JTA)
- Java Transaction Service (JTS)
- Java Naming and Directory Interface (JNDI)
- Java Message Service (JMS)
- Java IDL i Remote Method Invocation (RMI)
Z racji, że nasza aplikacja jest aplikacją typowo serwerową posłużymy się J2EE.
Programy w javie mogą być uruchamiane jako samodzielne aplikacje na komputerze
klienta lub jako aplikacje dostępne przez WWW. Aplikacje javy dostępne przez
WWW to Servlety i Applety. Applety działają po stronie klienta. Servlety wykonują
się po stronie serwera. Dzięki środowisku Javy są łatwiejsze w implementacji,
szybciej działają i nie są podatne na błędy programistów tak jak standardowe
mechanizmy CGI.
Po stronie klienta, Java oferuje również kilka rozszerzeń, do najważniejszych
z nich należą java3d, która umożliwia wykorzystanie procesorów graficznych,
dostępnych coraz częściej, na kartach graficznych. Dzięki niemu możliwa jest
realizacja funkcji interfejsu OpenGL i DirectX.
Kolejnym składnikiem biblioteki Javy (począwszy od JDK 1.2) jest Swing. Jest
to oprogramowanie implementujące graficzny interfejs użytkownika napisane w
100% w Javie. Dzięki mechanizmowi "look & feel" zmiana wyglądu
i funkcjonalności elementów jest bardzo łatwa. A bogaty zestaw komponentów wyższego
poziomu typu listy, tabele, podwójne panele, wskaźniki progresu, itd. czynią
z niego rozszerzenie bardzo przydatne.
Rozszerzeniem Javy na które warto zwrócić uwagę jest technologia JavaServer
Pages. JavaServer Pages są rozszerzeniem technologii Java Servlet rozwijanej
przez Apache Software Group. Zaletami JSP są :
- dostęp do wszystkich rozszerzeń Javy
- możliwość używania z dowolnym systemem operacyjnym dysponującym środowiskiem
runtime Java oraz na dowolnym serwerze aplikacji
- efektywność, wynikająca ze sposobu uruchamiania serwletu. Jeśli aplikacja
bazująca na serwlecie nie zostanie zamknięta, dopóty serwlety wykonują się w
obrębie procesu który działa, a każde nowe żądanie, nie uruchamia całej masy
procesów potrzebnych do utworzenia nowego procesu, tylko tworzy nowy wątek Proces
serwleta zamyka serwer np. w momencie kiedy zamykany jest proces serwera.
- skalowalność, możliwa jest współpraca komponentów rozmieszczonych na różnych
serwerach aplikacji
- bezpieczeństwo, które JSP dziedziczy z języka java
- zaawansowany mechanizm obsługi sesji
- kontener serwletów rozróżnia kontekst i w zależności od niego deleguje zadania
do różnych aplikacji
- od wersji 2.2 możliwe jest pakowanie zasobów (typu statyczne strony WWW, aplety,
servlety itd. oraz deskryptora rozmieszczenia) do plików archiwum .war. Wszystkie
serwery zgodne ze specyfikacją Servleta 2.2 potrafią instalować plik war, dzięki
temu możliwe jest szybkie i bezproblemowe instalowanie nowych aplikacji WWW
- możliwe jest oddzielenie przetwarzania żądania, logiki biznesowej i prezentacji.
Podejście takie umożliwia podział prac pomiędzy programistów i projektantów
stron WWW. Schemat poszczególnych warstw przedstawia ryc. XX, a omówiony został
w rozdziale dotyczącym oprogramowania serwera WWW.
W przypadku biblioteki cyfrowej, wskazane jest, sięgnąć po model aplikacji oparty
o Enterprise JavaBeans (EJB). Jest to najbardziej zaawansowany z modeli, programowania
w Javie, ale też najbardziej elastyczny. Ułatwi on implementację, komunikacji
z przeglądarkami, samodzielnymi aplikacjami, urządzeniami PDA i innymi. Dzięki
wykorzystaniu modelu zawierającego EnterpriseJavaBeans, możliwe jest pisanie
aplikacji skalowalnych i łatwych w pielęgnacji. Oczywiście wymaga to odmiennego
projektowania aplikacji.
Językiem, który posłuży nam do opisywania danych zawartych w bibliotece będzie
XML. Dołączając do kodu XML struktury dokumentów opisane przy pomocy mechanizmu
DTD (Document Type Definition) lub rozszerzające DTD XML Schema oraz XSL, otrzymujemy
elementy z których, w połączeniu z językiem java, można stworzyć narzędzia umożliwiające
proste i szybkie generowanie dobrze opisanych, przez co doskonale nadających
się do wymiany, dokumentów. Możliwe jest również dynamiczne generowanie dokumentów
w różnych formatach, w zależności od tego czego potrzebujemy.
DTD pozwala na systematyzację opisu budowy tekstu. Niestety ogranicza się on
tylko do identyfikacji wzajemnego położenia części składowych dokumentu. Związki
zawierania się oraz kolejności występowania elementów opisywane są przy pomocy
wyrażeń regularnych, które definiują ich model zawartości. DTD potrafi jedynie
kontrolować podstawowe parametry struktury. Nie ma możliwości definiowania typów
wykraczających poza model zawartości, przez co nie ma możliwości narzucenia
ograniczeń na zawartość elementów. Alternatywnymi rozwiązaniami są XML-Data,
RDF (Resource Description Format), DCD (Document Content Description) oraz XSchema.
Cechą odróżniającą XSchema od XML-Data, RDF i DCD jest to, że nie wymaga on
włączenia do DTD informacji o schemacie. W XSchema DTD jest zawarte w środku.
Ponadto stosowany sposób opisu jest zgodny ze standardowym XML. XSchema jest
wynikiem wielu dyskusji prowadzonych w grupie projektantów XML'a, nie było tu
wsparcia przemysłu, ale ciężka praca setek ludzi. Za standardem XML-Data stoi
Microsoft, za RDF Netstacape a DCD to wynik to kompromisu pomiędzy dwoma wcześniejszymi
produktami za którymi stoi W3C. Przyjrzyjmy się zatem możliwościom oferowanym
przez Xschema. Xschema rozszerza możliwości DTD, zachowując wszystkie jego najistotniejsze
cechy. Główne rozszerzenie polega na umożliwieniu określania typów zawartości
elementów i wartości atrybutów, tak przez wskazywanie typów predefiniowanych
jak i użycie typów własnych. Istnieje możliwość wprowadzania dwóch rodzajów
zawartości - prostych i złożonych. Typy proste to typy wbudowane (liczba, napis,
wartość logiczna) a także typy stworzone na ich bazie. Wykorzystywane są głównie
do określania dopuszczalnych wartości atrybutów i zawartości elementów. Typy
złożone są definicjami modeli zawartości, poszerzone o atrybuty związane z definiowanym
elementem. Mając strukturę logiczną dokumentu możemy sprawdzić w bardzo prosty
sposób jego poprawność. Istnieje wiele narzędzi, które umożliwiają taką właśnie
walidację. Jeśli połączymy kod realizujący zadanie z walidatorem, poprawność
kodu sprawdzana będzie przez narzędzie walidujące. Jeśli przy tym struktura
dokumentu będzie prawidłowa możemy oszczędzić sporo czasu w procesie programowania.
Aby wyświetlenie kodu XML było możliwe w przeglądarce musimy go w jakiś sposób
sformatować. Niestety przeglądarki firm Netscape i Microsoft bardzo różnie podchodzą
do tego zagadnienia, więc może okazać się, że w jednej przeglądarce kod będzie
wyświetlany poprawnie, podczas gdy w drugiej nie. Do formatowania treści dokumentu
XML można podejść na trzy sposoby. Pierwszą metodą jest wykorzystanie języka
DSSSL (Document Style Semantics and Specification Language). Druga z metod to
posłużenie się CSS. Trzecią z metod jest wykorzystanie możliwości XSL (eXtensible
Style Language).
DSSSL jest kompletnym językiem programowania stylu dokumentów SGML, który może
być stosowany również do dokumentów XML. Jest to narzędzie wyjątkowo silne,
ale również bardzo złożone w obsłudze, a w przypadku wykorzystania dla potrzeb
sieciowych zbyt potężne. DSSSL nie jest jednak szeroko stosowane.
CSS jest językiem obsługi stylów HTML, który z powodzeniem może być wykorzystywany
do formatowania dokumentów XML.
XSL jest językiem definiowania arkuszy stylów. Składania XSL jest oparta na
składni XML a idea działania na DSSSL.
3.3.2 oprogramowanie dostarczane z zewnętrz
Jednym z najważniejszych elementów biblioteki cyfrowej jest baza danych. Będzie
ona pełniła rolę przechowalni danych. Bazę danych która byłaby najodpowiedniejsza
dla naszych potrzeb powinny charakteryzować następujące cechy :
- relacyjność
- gwarancja bezpieczeństwa i prywatności
- wydajny mechanizm indeksowania
- obsługa pełnego język zapytań SQL
- praca na platformie UNIX
- skalowalność
- obsługa języka XML i Java
- możliwość tworzenia kolekcji
- obsługa XML-owych języków zapytań (Xquery/Xpatch/XQL)
- wsparcie dla standardów takich jak Xlink, XSchema
- zdolność obsługi dużych woluminów i dużej liczby użytkowników
- możliwość współpracy z serwerami aplikacyjnymi oraz innymi bazami danych
Bardzo ważne jest aby wirtualna maszyna Javy była zintegrowana z motorem bazy
danych, gdyż zapewnia to bardzo wysoką wydajność.
W zależności od rodzaju przechowywanych dokumentów w bazie danych, istnieją
dwa podejścia :
-danocentryczne
-dokumentocentryczne
Dokument, którego struktura jest całkowicie regularna i zawartość jest prawie
niezmienna, przystosowany do obróbki przez komputery, jest dokumentem dano-centrycznym.
Przykładami takich mogą być : zamówienia sprzedaży, rozkłady lotów, dane naukowe,
notowania giełdowe oraz informacje opisujące książki.
Dokumentocentryczne natomiast są : książki, listy, ogłoszenia oraz prawie wszystkie
ręcznie pisane dokumenty. Charakteryzuje je brak struktury lub struktura mniej
regularna, a podstawowe elementy z których się składają mogą mieć różną zawartość
np. w pracy magisterskiej podstawowym elementem jest rozdział, składać się on
może z tytułu i zawartości przy czym zawartością mogą być rysunki, tabele, treść,
podrozdziały, wszystkie te elementy mogą występować w różnej kolejności.
Z uwagi na to, że większość informacji przechowywanych w bibliotece cyfrowej
charakteryzuje duża zmienność, zalecane jest podejście dokumentocentryczne.
Wpływa to również, w pewnym stopniu, na decyzję o wyborze bazy danych.
Różni producenci baz danych w różny sposób wspierają XML. Jedni z nich tworzą
nowe funkcje, inni tworzą zupełnie nowe produkty ukierunkowane na XML'a. Jedną
z relacyjnych, doskonałych, baz danych wspierających XML'a jest Oracle. Obsługa
XML'a wspierana jest w nich od wersji 8i. Elementy wspierające XML'a to : procesory
XML dla PL/SQL, javy oraz C/C++, XML-SQL Utility oraz Oracle XSQL Servlet. Procesory
XML wspierają następujące standardy :
- interfejs SAX
- model DOM (poziomu pierwszego)
- przestrzeń nazw XML
- przekształcenia XSLT (od wersji drugiej)
Korzystając z procesorów XML, można przeprowadzić kontrolę składniową i strukturalną.
XML-SQL Utility
Dzięki temu produktowi możliwe jest generowanie dokumentów XML na podstawie
bezpośrednich zapytań do bazy danych, jak również wprowadzanie danych do bazy
na podstawie dokumentu XML.
XML-SQL Servlet
Produkt ten integruje wymienione powyżej usługi włączając dodatkowo serwer WWW
oraz obsługę HTTP. Komunikacja aplikacji klienta z XML-SQL polega na wysłaniu
przez klienta zapytania HTTP, zawierającego treść zapytania SQL. Zapytanie to
aby mogło być zrealizowane musi być umieszczone w dokumencie XML w elemencie
query. Skrypt xsql realizujący przykładowe zapytanie :
<?xml version="1.0"?>
<xsql:query connection="test" xmlns:xsql="urn:oracle-xsql">
select * from autorzy
</xsql:query>
Wykorzystując arkusz stylów XSLT możemy sformatować nasz dokument tak aby przeglądarka
potrafiła go zinterpretować.
Firma Oracle bardzo poważnie podeszła do XML'a. Dzięki tak silnym narzędziom
jak parsery XML, XSU i wreszcie XML-SQL można skupić swoją uwagę na, w naszym
przypadku, merytorycznej stronie funkcjonowania biblioteki. Należy również podkreślić,
że produkty Oracle'a są w bardzo dużym stopniu zgodne z ustaleniami W3C.
Odmienną klasę produktów, stanowią XML'owe natywne bazy danych. Przykładem takiej
jest Tamino firmy Software AG. Bazy tego typu oferują wszystkie możliwości relacyjnych
baz danych, uzupełniając ich funkcjonalność o specyficzne metody dostępu oferowane
przez XML. Natywność oznacza przechowywanie danych w postaci naturalnej. Każdy
z dokumentów XML jest podstawową jednostką logicznego składowania, tak jak krotki
w relacyjnej bazie danych. Podstawowymi cechami natywnych baz danych są :
-obsługa kolekcji dokumentów
-obsługa jednego lub więcej języków zapytań, XPatch, XQL. Wybierając bazę danych
należy sprawdzić, czy obsługiwane języki zapytań spełniają nasz potrzeby oferując
np. pełnotekstowe wyszukiwanie, składanie dokumentów z różnych fragmentów innych
dokumentów
-różne techniki aktualizacji i usuwania. Często wykorzystywane są do tego własne
języki twórców baz danych, aczkolwiek są tendencje do wykorzystywania standardu
XUpdate.
-wsparcie dla transakcji, blokowania i współbieżności. W obecnej chwili blokowanie
dotyczy całego "dokumentu", przy czym od nas zależy co będzie dokumentem,
może nim być np. rozdział
-API (Application Programming Interface) umożliwiają podłączenie do bazy danych,
eksplorację danych, wydanie zapytań i otrzymanie wyników w postaci dokumentu
XML lub drzewa DOM.
-zdalne dane - niektóre z baz oferują włączanie odległych danych do dokumentów
składowanych w bazie. Najczęściej są to dane odzyskiwane z relacyjnych baz danych.
-indeksy - przyspieszają odzyskiwanie danych. Mogą być zakładane na elementach
i wartościach atrybutów
Przy projektowaniu biblioteki cyfrowej trzeba podjąć decyzję na która z baz
danych będzie dla nas odpowiedniejsza. Biorąc pod uwagę, że natywne bazy danych
są produktami stosunkowo nowymi, myślę, że oprogramowanie wykorzystujące parsery
xml'a i odpowiedni projekt relacyjnej bazy danych, będą wystarczająco wydajne.
Oddzielne zagadnienie, niemniej bardzo ważne, stanowi sposób zapisu dokumentów
XML w bazie danych. Zależeć będzie od tego szybkość pozyskiwania, aktualizacji
i usuwania danych. Ponieważ dokumenty przez nas przechowywane będzie charakteryzowała
różna struktura nie jest możliwe stworzenie jednej relacji, która by je przechowywała,
zatem mamy trzy możliwości :
-zapis w postaci zdekomponowanej
-zapis w postaci natywnej
-zapis w postaci mieszanej
Postać zdekomponowana polega na rozkładzie dokumentu na tabele bazy danych.
W przypadku prostych dokumentów nic nie stoi na przeszkodzie aby tak postąpić,
dane biblioteki cyfrowej, nie nadają się do składowania w ten sposób.
Zapis w postaci natywnej polega na umieszczeniu całości dokumentu XML w polach
LOB(Large Obiect Binary) bazy danych. Zapis taki nie narusza oryginalnego formatu
dokumentu, ale dostęp do zagnieżdżonych elementów jest utrudniony i może się
on odbywać tylko przy wykorzystaniu parsera.
Zapis w postaci mieszanej opiera się o dwie powyższe metody zapisu. Struktury
modelują częściową hierarchię elementów. To na ile głęboka jest ta hierarcha
zależy od potrzeb. Poniżej tej struktury dane zapisywane są w polach CLOB.
Nieodłącznym elementem każdego systemu udostępniającego informacje przez sieć
Internet, jest serwer WWW. Do wyboru mamy parę produktów, i tak : Apache Web
Serwer, iPlanet Web Server, Microsoft IIS i inne. Nie ulega wątpliwości, że
serwerem WWW, który obecnie dominuje na rynku jest Apache. Jest to produkt ciągle
rozwijany, dzięki temu wspiera większość najnowszych technologii pojawiających
się na rynku. Do najnowszej wersji 2.0.35 wprowadzono moduły MPM (Multi-Processing
Modules) co przyspieszy przetwarzanie zapytań. Moduł filtrów mod_ext_filter
pozwoli na wielokrotne przetwarzanie strony zanim wysłane zostanie ona w odpowiedzi
do klienta. Pojawiły się również moduły dodatkowe takie jak mod_ssl odpowiedzialny
za szyfrowanie połączeń, mod_deflate kompresujący strony "w locie".
Wybierając serwer WWW Apache i zakładając, że językiem którym się posłużymy
będzie java, pozostaje nam wybór serwera aplikacji. Do wyboru mamy systemy komercyjne
i open source. Zalety systemów komercyjnych takie jak wydajność, wsparcie techniczne
oraz pełna dokumentacja, nie podlegają dyskusji. Systemy open source mają niejednokrotnie
zbliżone możliwości do produktów komercyjnych, poprzez to że są darmowe wielu
użytkowników je wykorzystuje i chętnie służy pomocą w razie problemów, a ponad
to dostępne są kody źródłowe serwera. Produkty open source są bogate w nowinki
techniczne, a kod jest bardziej dopracowany. Dostępne systemy open source to
:
- Resin
- Enhydra
- Tomcat
- vgServer
- JBoss
- Jetty Java
- JOnAS
Dla dużych aplikacji, działających w środowiskach korporacyjnych należy wybrać
produkt zgodny z J2EE, czyli obsługujący przede wszystkim EJB. Produktem takim
jest tylko JBoss. Z uwagi na brak obsługi przez JBoss'a XML'a należy wybrać
instalację JBoss'a z osadzonym kontenerem servletów (Tomcat). Tomcat zawierający
servlet o nazwie Cocoon pozwala na wyraźną separację warstw zawartości i prezentacji.
Ryc.3.4 przedstawia umiejscowienie serwera aplikacji w modelu warstwowym.
Rys. 3.4
3.3.3 sprzęt
Sprzęt, który obsługuje bibliotekę cyfrową może być zwykłym komputerem PC podłączonym
przez sieć Ethernet 10Mb/s. System taki, może być również bardzo wyrafinowanym
systemem na który składa się wiele serwerów i urządzeń wspierających, wszystko
zależy od skali przedsięwzięcia, możliwości i potrzeb. Jedną z najbardziej pożądanych
cech systemu, z punktu widzenia klienta, jest czas obsługi wystosowanego żądania.
Tworzony system musi zatem dostarczać informacji maksymalnie szybko. Istnieje
kilka kluczowych czynników, które mają na to wpływ. Poniższy rysunek (Rys. 3.5)
przedstawia przykłady możliwych połączeń klient-biblioteka cyfrowa z uwzględnieniem
prędkości transmisji.
Rys 3.5
Pierwszym elementem jest komputer klienta, im szybszy procesor, wydajniejsza
karta graficzna, bardziej pojemna pamięć tym szybciej niektóre z aplikacji mogą
działać (np. prezentacje multimedialne we flashu czy też applety). Niestety
często komputery wydajne obliczeniowo są źle skonfigurowane, otwierane jest
zbyt wiele aplikacji, dysk twardy jest zdefragmentowany, a stara przeglądarka
internetowa skutecznie spowalnia proces dostarczania zawartości. Cóż na prędkość
działania tego elementu nie mamy wpływu. Drugi z elementów to połączenie klienta
do Internetu, tu przepustowość zależna jest od jego możliwości. Trzeci z elementów
to sieć Internet i czwarty połączenie serwera i piąty to serwer biblioteki.
Wpływ mamy na połączenie serwera do sieci i sam serwer. Zakładamy, że dysponujemy
łączem o wystarczającej przepustowości. Dostarczanie materiałów możemy przyspieszać
korzystając z następujących technik :
-kształtowanie ruchu
-buforowanie
-rozkładanie obciążeń
Kształtowanie ruchu obsługuje urządzenie zwane regulatorem ruchu umieszczone
przed serwerem WWW. Zadaniem jego jest przechwytywanie i analizowanie potwierdzeń
TCP we wchodzących strumieniach danych. Analizowany jest typ aplikacji łączącej
się do serwera i adres IP. W zależności od tego ruch jest wstrzymywany lub nie.
Zabieg taki pozwala na faworyzowanie aplikacji wymagających pasma o dużej przepustowości
np. strumieni video.
Buforowanie polega składowaniu oryginalnej zawartości serwera na innej maszynie
i dostarczaniu jej kiedy klient się do niej odwoła. Wykorzystywany przy tym
jest fakt, że potrzebna informacja jest niezmienna w czasie i odwołuje się do
niej wielu klientów. W ogólności systemy buforujące można podzielić na dwa rodzaje
:
-bufory proxy - klient wysyła żądanie które trafia do bufora później jeśli
bufor nie zawiera informacji kierowane jest do serwera. Ten rodzaj bufora może
chronić sieć przed atakami z zewnątrz.
-bufory przezroczyste - przeglądają pakiety, jeśli celem odwołania jest jakiś
obiekt znajdujący się w buforze jest on z niego pobierany.
Bufory przechowujące zmieniającą się w czasie zawartość odświeżają ją zgodnie
z określonymi algorytmami. Dodatkowo szybkość ściągania obiektów składających
się na stronę WWW może przyspieszyć zastosowanie protokołu HTTP 1.1 w którym
to obiekty przekazywane są grupami i mogą być kompresowane przy pomocy algorytmu
GZIP.
Rozkładanie obciążeń jest techniką w której wykorzystuje się dwa lub więcej
serwerów web, które zawierają tę samą lub częściowo pokrywającą się zawartość.
Wykorzystuje się tutaj urządzenia zwane rozdzielaczami obciążeń. Zadaniem ich
jest przekierowywanie ruchu HTTP, FTP lub innego do serwera, który w danym momencie
jest najmniej obciążony. Wyżej wymienione techniki najlepiej stosować jednocześnie.
Kolejną z metod przyspieszania jest rozbudowa serwera/serwerów. Wydajność możemy
zwiększyć poprzez zastosowanie szybkich dysków twardych, większą ilość pamięci
operacyjnej, szybsze procesory, ale także rozbudowę infrastruktury o kolejne
urządzenia np. :
-serwery baz danych
-systemy pamięci masowej
-urządzania obsługujące wirtualne sieci prywatne
-akceleratory szyfrowania
-akceleratory klasyfikujące i przetwarzające transakcje XML
-urządzenia odpowiedzialne za pozycjonowanie stron WEB
Szybsze dostarczanie zawartości można osiągnąć poprzez dystrybucję materiałów
na szereg rozproszonych geograficznie serwerów i zastosowanie urządzeń do globalnego
równoważenia obciążeń. Dzięki temu użytkownik żądający danego zasobu otrzymuje
go z serwera, który w danym momencie może dostarczyć go najszybciej. Podobnym
rozwiązaniem jest CDN (Content Delivery Network), polega to na przesyłaniu zawartości
statycznej serwera Web (pliki PDF, obrazy) do buforów umieszczonych "bliżej
użytkownika".
Niebagatelny wpływ na czas dostarczania ma objętość dostarczanych materiałów.
Popularnie stosowane techniki optymalizacji polegają na : redukcji kolorów w
obrazach GIF, adjustacji plików JPEG, do bardzo dużych plików stosuje się formaty
MrSid i DjVU. Pliki HTML i JavaScript można zmniejszać redukując liczbę elementów
składniowo i treściowo neutralnych takich jak np. białe spacje, można również
skrócić nazwy zmiennych.
Z uwagi na sposób przeglądania stron WWW przez klientów polegający na ściąganiu
stron, czytaniu i ponownym ściąganiu można poprzez analizę zachowania klienta
przewidzieć jaki materiał będzie następnym materiałem, który będzie chciał przejrzeć.
I ściągać takowy z pewnym wyprzedzeniem.
Przy założeniu, że dostęp do biblioteki cyfrowej będą mieli użytkownicy urządzeń
PDA (Personal Digital Assistant) należy, w celu przyspieszenia transmisji i
dostosowania zawartości, skorzystać z urządzeń zwanych proxy odciążające - PEP
(Performance Enhancing Proxies). Urządzenia te mogą rozszerzyć istniejącą infrastrukturę.
Działanie urządzeń tego typu, w ogólności, polega na :
-dostosowaniu prezentowanych danych do urządzenia, które je odbiera
-kompresji danych
-wykorzystywaniu momentów w których użytkownik jest nieaktywny
-optymalizacji komunikacji
Z uwagi na to, iż część systemów PDA korzysta z ekranów monochromatycznych
lub z ekranów o ograniczonej liczbie kolorów, zadaniem systemów PEP jest konwersja
pobieranych z serwera obrazów do odpowiedniej dla danego urządzenia postaci.
Zmniejsza to ilość transmitowanych informacji. Dodatkowo ilość transmitowanych
informacji jest zmniejszana poprzez kompresję zawartości, która to jest rozpakowywana
przez przeglądarkę użytkownika. Systemy PEP poprzez analizę klientów odwołujących
się do serwera tworzą tzw. "wzorce zachowań" pozwala to na przewidywanie,
w jakiej kolejności są przeglądane materiały. Na tej podstawie można ściągnąć
informację zanim użytkownik będzie faktycznie jej potrzebował i wyświetlić ją
natychmiast gdy tylko się do niej odwoła. Optymalizacja komunikacji polega na
redukcji liczby zleceń, które musi obsłużyć serwer WWW. W standardowym HTTP
jedno odwołanie np. do strony głównej serwera, powoduje zestawianie połączeń
TCP dla każdego z elementów strony, przy czym, może to być zwielokrotnione tyle
razy ilu użytkowników w danym momencie zaczyna przeglądać ową stronę (zakładamy
że buforowanie jest wyłączone). Redukcję otwieranych i zamykanych połączeń można
uzyskać poprzez ustalenie stałego połączenia z serwerem i współdzieleniem tego
połączenia pomiędzy wielu użytkowników. Tym wszystkim zajmuje się PEP.
Aby możliwe było szybkie i na dużą skalę korzystanie z zawartości archiwum,
udostępnianie danych edukacyjnych w tym również multimedialnych oraz zapewniony
był wysoki poziom ochrony konieczne są systemy pamięci masowych.
Dla ogromnych ilości danych archiwalnych, składowanych na płytach CD, idealnym
rozwiązaniem są systemy jukebox. Są to szafy w których umieszcza się płyty CD/DVD,
a wbudowane szybkie czytniki CD/DVD poprzez sieć dostarczają ich zawartość użytkownikom.
Dla przykładu firma SCSI Express oferuje urządzenia o pojemnościach odpowiednio
240 i 480 płyt CD/DVD. Każde z nich dysponuje 6 czytnikami CD/DVD. Maksymalne
pojemności dla płyt CD to odpowiednio 156GB i 312GB. Nie są to zbyt duże pojemności
biorąc pod uwagę pojemności dostępnych w sprzedaży dysków twardych (około 80GB).
Jeśli jednak zamiast płyt CD umieścimy płyty DVD pojemność jukebox'ów wzrasta
odpowiednio do 1128GB i 2256GB. Maksymalne transfery dla wbudowanych CD-ROM'ów
to 6MB/s, a dla DVD-ROM'ów to 22.1 MB/s. Produkowane są również modele z wbudowanymi
czytnikami SCSI, oparte o technologię transmisji FiberChannel, posiadające również
możliwość zapisu płyt CD.
Aby zapewnić dostęp o odpowiednio szerokim paśmie dla danych multimedialnych
należy skorzystać ze specjalizowanych architektur dedykowanych pamięciom masowym
:
- SAS (Server Atached Storage)
- NAS (Network Attached Storage)
- SAN (Storage Area Network)
- iSCSI
Niestety, szczegóły techniczne dotyczące tych technologii leżą poza zakresem
tej pracy. Z punktu widzenia skalowalności i wydajności oraz łatwości w zarządzaniu
systemy SAN wydają się być najbliższe ideałowi.
Kolejnym elementem pamięci masowych są macierze dyskowe RAID (Redundant Array
of Inexpensive Discs). Istnieje kilka poziomów ochrony macierzy RAID od 0 do
7. Najistotniejsze cechy macierzy RAID to możliwość wymiany uszkodzonych dysków
podczas pracy (hot swap) i w zależności od poziomu RAID duże prędkości odczytu/zapisu
danych i/lub podwyższone bezpieczeństwo danych. Większość serwerów dostępna
na rynku krajowym obsługuje RAID 4 lub 5. RAID 5 pozwala na szybszy odczyt/zapis
danych, przy równoczesnym zapewnieniu podwyższonego bezpieczeństwa, niż niższe
poziomy. Wymaga minimum trzech dysków twardych. Nadaje się on doskonale do ochrony
danych systemów wielozadaniowych.
Bardzo istotną czynnością, którą należy regularnie wykonywać, są kopie bezpieczeństwa.
Najlepiej do tego celu wykorzystać technologię pamięci taśmowych np. DAT lub
Travan.
Wykorzystując inteligentne przełączniki pamięci masowych np. SilkWorm 2800 firmy
Brocade, można w prosty sposób połączyć macierze siecią SAN z Jukebox'ami i
pamięcią taśmową. Zaletami inteligentnych przełączników pamięci masowych są
:
- budowa modularna umożliwiająca rozbudowę przełącznika w miarę pojawiających
się nowych technologii
- obsługa wielu protokołów transmisji, w zależności od zastosowań należy stworzyć
odpowiednią architekturę. Dla aplikacji bazodanowych najbardziej polecana jest
architektura SAN dla aplikacji działających na poziomie plików NAS, z kolei
dla aplikacji odzyskujących dane iSCSI.
- wirtualizacja - wszystkie dyski "widziane są" jako jedno urządzenie
- bardzo wydajne funkcje równoważenia obciążeń
4. Opis zaimplementowanego zoom'u cyfrowego
Poniżej przedstawiono opis oprogramowania pełniącego funkcję "elektronicznej
lupy". Projekt został zaprojektowany, zaimplementowany i przetestowany
przez autora, w ramach niniejszej pracy dyplomowej. Źródło programu dostępne
jest na płycie CD załączonej do pracy.
- opis funkcjonalny
Aplikacja zaimplementowana w Javie w formie appletu, umożliwia oglądanie kolejnych
stron dokumentu i "zbliżanie" jego wybranych fragmentów. Dokumentem
jest tutaj zbiór obrazów przedstawiających np. kolejne strony książki.
- opis działania
Dane wejściowe to pliki dwóch rodzajów : miniatura obrazu (rozdzielczość 400x300
punktów) i obraz właściwy o rozdzielczości 2048x1536 punktów, oby dwa pliki
powinny być w formacie JPG lub GIF.
Poruszając myszką w lewym oknie aplikacji, przesuwamy "ramkę", której
"zawartość" w momencie kliknięcia myszką jest "powiększana"
i ukazuje się w prawym oknie aplikacji. Pod lewym oknem znajdują się przyciski
"poprzednie", "następne" umożliwiające przechodzenie pomiędzy
stronami książki. Algorytm "powiększenia" polega na skopiowaniu do
prawego okna odpowiedniego fragmentu dużego obrazu, w zależności od tego w którym
miejscu nastąpiło kliknięcie na mniejszym obrazku.
W aplikacji wykorzystano, techniki wstępnego ładowania obrazów, wielowątkowość
i wymuszane "oczyszczanie" pamięci. Wstępne ładowanie uruchamiane
jest podczas startu aplikacji lub kliknięciu przycisku "poprzednie/następne",
dzięki niemu, miniatura i obraz właściwy ściągane są z sieci równolegle. Zapewnia
to natychmiastowe wykreślanie "powiększenia" w momencie wyboru obszaru
"do powiększenia". Wykorzystanie wielowątkowości pozwoliło na nieblokujące
wykreślanie "powiększonego obrazu". Pierwotna wersja programu w momencie
kliknięcia na "miniaturze" uruchamiała procedurę wykreślającą, ale
blokującą ramkę, przy pomocy której w lewym oknie wybieramy obszar do powiększenia.
Rozdzielenie aplikacji na dwa wątki pozwoliło na wyeliminowanie tej niedogodności.
Wymuszane "oczyszczanie" pamięci okazało się koniecznością ze względu
na to, że standardowe automatyczne narzędzie użyte w Javie jest mało wydajne.
Wymuszane oczyszczanie pamięci pozwoliło uniknąć błędów generowanych przez wirtualną
maszynę Javy, związanych z brakiem pamięci operacyjnej. Prędkość działania aplikacji
jest uzależniona od obciążenia sieci i procesora, przy czym prędkość sieci jest
ważna w momencie ładowania rysunków, a moc procesora w momencie wyświetlania
"powiększenia". Rys. 4.1 przedstawia wygląd aplikacji.
- wymagania systemowe
Komputer wyposażony w minimum 128MB pamięci RAM, z zainstalowaną wirtualną maszyną
Javy firmy SUN w wersji 1.3.1 lub wyższej, im szybszy procesor tym prędzej jest
wykreślane powiększenie obrazu.
- możliwe ulepszenia
Aby przyspieszyć proces wyświetlania należy zaimplementować, procedurę za to
odpowiedzialną w Javie 3d, wówczas różnicę w prędkościach dostrzegliby użytkownicy
posiadający akceleratory graficzne wspierające OpenGL i DirectX np. firmy Nvidia.
Funkcjonalność aplikacji mogłyby podnieść możliwości : szybkiego przechodzenia
do określonej strony, robienia notatek na marginesie, zaznaczania tekstu, wstawiania
zakładek, czy też możliwości przeszukiwania pod kątem występowania np. jakiejś
frazy. Ostatnia z cech wiąże się, niestety z przepisaniem prezentowanego tekstu
i oznaczeniem poszczególnych wyrazów, tak aby podczas wyszukiwania można było
je podświetlić. Przyszła wersja powinna uwzględnić możliwości nowego interfejsu
graficznego Javy, a mianowicie Swing'a. W nim też powinna zostać napisana, pozwoliłoby
to w przyszłości na bardziej elastyczne dodawanie nowych funkcji oraz szybsze
wyświetlanie interfejsu.
Rys. 4.1
5.0 Wnioski i uwagi końcowe
Zbliża się era bibliotek cyfrowych. Coraz liczniejsza grupa publikacji pojawiających
się w wersji papierowej ma również swoje sieciowe odpowiedniki, coraz powszechniejszym
zjawiskiem staje się udostępnianie i rozpowszechnianie materiałów naukowych
tylko i wyłącznie w postaci elektronicznej. Od systemów przechowujących informację
oczekuje się, że otrzymaną w wyniku wyszukiwania informację będzie cechowała
przede wszystkim wysoka jakość, a ona sama zostanie nam dostarczona w sposób
natychmiastowy. Obok funkcjonalności są to dwie najbardziej pożądane charakterystyki.
W pracy przedstawiłem bibliotekę cyfrową zarówno od strony jej użytkowników
jak i osób ją obsługujących. Omówiłem poszczególne funkcje tradycyjnej biblioteki
w odniesieniu do biblioteki cyfrowej oraz wytyczne dla oprogramowania wykorzystywanego
przy tworzeniu takowej. Zakres usług oferowanych przez bibliotekę cyfrową może
być dostosowywany do potrzeb jej użytkowników i w zależności od ich potrzeb
rozszerzany. Należy również zwrócić uwagę, że istnieją liczne możliwości ograniczania
praw użytkowników w odniesieniu do funkcjonalności przez nią oferowanych. Dla
przykładu autorzy mają możliwość tworzenia nowych oraz edycji wcześniej napisanych
publikacji.
Duży nacisk położyłem na język opisu danych (XML), standardy z nim związane,
narzędzia wspierające go oraz kwestie bezpieczeństwa.
Opracowałem program - "zoom cyfrowy" umożliwiający przeglądanie i
analizę materiałów piśmienniczych, które ze względu na swoją wartość oraz unikatowość
nie są udostępniane w tradycyjny sposób. Pozwoli to na zabezpieczenie ich przed
zniszczeniem, a z drugiej strony udostępnienie wszystkim zainteresowanym. Zakładam,
że program ten zostanie wykorzystany w konkretnym projekcie biblioteki cyfrowej
i będzie ewoluował wraz z jej rozwojem.
W pracy poruszyłem wiele aspektów dotyczących bibliotek cyfrowych, jednak ze
względu na obszerność tematu, należałoby jeszcze skoncentrować się na następujących
problemach :
- zwiększaniem bezpieczeństwa prezentowanych materiałów, które są objęte prawem
autorskim,
- dynamicznym konwertowaniem między sobą różnego rodzaju dokumentów tekstowych
z uwzględnieniem rodzaju i parametrów urządzenia wykorzystywanego jako urządzenie
dostępowe,
- badaniami nad "obciążalnością" systemu,
- udostępnianiem materiałów dla urządzeń nie będących komputerami klasy PC
- "elektronicznym wypożyczaniem" polegającym na udostępnianiu materiałów,
tak aby mogły być one składowane na komputerze użytkownika i dostępne lokalnie
przez określony czas
- zastosowaniu nowych formatów graficznych
BIBLIOGRAFIA
[1] Nahotko Marek, "Metadane", EBIB nr 6 (14), czerwiec 2000, http://www.oss.wroc.pl/biuletyn/ebib14/nahotko.html
[2] Lane E., "Add XML to your J2EE applications", http://www.javaworld.com/javaworld/jw-02-2001/jw-0209-xmlj2ee_p.html
[3] Making of America II, http://sunsite.berkeley.edu/MOA2
[4] "Serwery aplikacji open source", Pckurier 23/2001, http://www.pckurier.pl/archiwum/art0.asp?ID=5158
[5] Praca Zbiorowa, "Vademecum teleinformatyka", Warszawa, IDG S.A.
1999
[6] Tomasz Boczyński, Tomasz Janoś, Stefan Kaczmarek (red.) , "Vademecum
teleinformatyka II", Warszawa, IDG S.A. 2002
[7] Oaks Scott "Java a bezpieczeństwo", Warszawa, RM, 2002
[8] Rusty Harold E.,"Java Programowanie sieciowe", Warszawa, RM, 2001
[9] Bergsten Hans, "Java Server Pages", Warszawa, RM, 2001
[10] Bezpieczeństwo danych w Internecie. Bezpieczeństwo WWW. http://www.cc.com.pl/security/bezpwwws.html
[11] Technical Recommendations for Digital Imaging Projects http://www.columbia.edu/acis/dl/imagespec.html
[12]Key Concepts in the Architecture of the Digital Library http://www.dlib.org/dlib/July95/07arms.html
[13] Shawn Ryder: "Flash 5" http://www.wdvl.com/Reviews/Graphics/Flash5/
[14] Jarosław Rafa "Dźwięk i obraz na stronach WWW" http://www.wsp.krakow.pl/papers/av_mi.html
[15] Błażewicz A., "Technologie i aspekty dostępu do informacji elektronicznej
w środowisku akademickim", praca magisterska, Politechnika Poznańska, Poznań,
2000
[16] Networld http://www.networld.pl/leksykon/nw_term_info.asp?termin_nazwa=QoS
[17] DigiTool http://www.aleph.co.il/DTL/index.html
[18] Remote User Authentication in Libraries http://library.smc.edu/rpa.htm#user%20authentication%20in%20libraries
[19] Lemay L., Perkins Ch.L., "Java 1.1" Gliwice, HELION 1998.
[20] Software 2.0, Warszawa, Software-Wydawnictwo, nr 6(78), czerwiec 2001
[21] Software 2.0, Warszawa, Software-Wydawnictwo, nr 12(72), grudzień 2000
[22] Web File Protection http://webdesign.about.com/library/weekly/aa062701a.htm
[23] WebCrypt Pro http://www.moonlight-software.com/webcrypt.htm
[24] WebExe 1.4 http://www.aw-soft.com/webexe.html
[25] JBoss http://www.jboss.org
[26] Tamino http://www.softwareag.com/tamino/