Spis treści
- ABSTRACT
- WSTĘP
- 1. UNIA EUROPEJSKA JAKO ORGANIZM WIELOJĘZYCZNY
- 1.1. Podstawy prawne wielojęzyczności Unii Europejskiej
- 1.2. Wielojęzyczność Unii Europejskiej
- 1.3. Języki Unii Europejskiej
- 1.4. Służby Tłumaczeniowe Komisji Europejskiej
- 1.5. Charakter i zakres tłumaczonych dokumentów
- 1.6. Nowe rozwiązania w pracy Służb Tłumaczeniowych w obliczu rozszerzenia Unii Europejskiej
- 2. NARZĘDZIA WSPOMAGAJĄCE PRACĘ TŁUMACZA W SŁUŻBACH TŁUMACZENIOWYCH KOMISJI EUROPEJSKIEJ
- 3. POLSKA W WIELOJĘZYCZNYCH STRUKTURACH UNII EUROPEJSKIEJ
- 4. Zastosowanie polskich systemów tłumaczących w tłumaczeniu tekstów z zakresu prawodawstwa unijnego - badania
- ZAŁĄCZNIK nr 1
- ZAŁĄCZNIK nr 2
- ZAKOŃCZENIE
- Literatura
Spis rysunków
- 1.1. Schemat organizacyjny struktury Służb Tłumaczeniowych Komisji Europejskiej .
- 2.1. Czynnik ludzki a technologia w narzędziach wspomagających pracę tłumacza.
- 2.2. Idealny dla przyszłości scenariusz przepływu dokumentu między poszczególnymi aplikacjami.
- 2.3. Okno aplikacji POETRY.
- 2.4. Przepływ zamówień na tłumaczenie pomiędzy poszczególnymi komórkami nadzorowany przez aplikację WinSuivi .
- 2.5. Okno aplikacji DossierManagement.
- 2.6. Interfejs Menu searching.
- 2.7. Interfejs Expert searching.
- 2.8. Okno bazy terminologicznej EURODICAUTOM.
- 2.9. Okno aplikacji MultiTerm.
- 2.10. Okno aplikacji One-stop Shop.
- 2.11. Okno aplikacji Translator's Workbench.
- 2.12. Widok okna systemu EC SYSTRAN - dostęp poprzez EURAMIS.
- 2.13. Architektura systemu EURAMIS.
- 2.14. Interfejs systemu EURAMIS -1.
- 2.15. Interfejs systemu EURAMIS -2.
- 2.16. Okno aplikacji Alignment Editor.
- 2.17. Okno aplikacji Translator's Workbench w systemie EURAMIS.
- 2.18. Okno aplikacji Microsoft Word w systemie EURAMIS.
- 3.1. Planowana struktura systemu POLENG.
- 3.2. Struktura systemu POLENG SHELL.
- 3.3. Okno edycyjne i edycja tekstu w POLENG SHELL.
- 3.4. Okno aplikacji LexiTools.
- 4.1. Wersja testowa systemu POLENG dostępna w internecie - wprowadzenie tekstu do analizy.
- 4.2. System POLENG po dokonanej analizie.
The European Union is unique among the world's international organizations in that the multilingualism has been an entrenched policy of the Union since the first day of its existence and is likely to remain so however many new Member States eventually join. The thesis presents the European Union as a multilingual body with 11 official languages and complex organization of the Translation Service of the European Commission (SdT). As we are facing the biggest enlargement in the EU's history in May 2004, the thesis additionally outlines changes in the way the SdT will function in the Europe expanded to 20 official languages.
Since the EU's legislation is binding on all citizens in Member States and any approach that failed to respect the languages of the people of the Union would betray its transparency and democracy, the law has to be expressed in all official languages which is put into practice by the SdT. To enhance the translation process translators are provided with a wide range of diverse and constantly improved computer aids, such as complex terminology and documentary databases, speech recognition systems, translation memories and machine translation systems or applications managing all stages of the process of translation. Thus, information technology plays an ever increasing role in the translator's daily work.
As Poland will also join the multilingual group of Member States of the European Union, it is essential to translate the whole immense Union's legislation into Polish, not only existing but future as well. Because of the fact that Polish is scarcely known beyond the borders of Poland and since Polish will become the official language of the Union, the development of tools facilitating the process of translation and understanding of texts written in Polish is now an undisputed priority in the hands of the accessing country.
Among the projects that are being developed in our country worth mentioning were machine translation systems: MATCHPAD, POLENG and LexiTools. Additionally, POLENG and LexiTools were tested according to their ability to translate the European Union legislation and the research proved that there is still a lot to be done in the field of machine translation in Poland.
There is no doubt that applying of translation aids visibly improved the translation work and process of translation itself. Like the European Union, the Translation Service is facing the biggest enlargement in its history. The question to be answered in the near future is how to make use of the experience gained so far and how to implement new solutions. The answer will determine the way of work in the enlarged Union.
W granicach wielojęzycznej Wspólnoty Europejskiej obowiązuje obecnie 11 języków oficjalnych, a niebawem, bo już w maju 2004 roku, liczba ta powiększy się do 20. Obowiązujące wszystkich obywateli Prawo Wspólnotowe wymaga wyrażenia w każdym z języków oficjalnych, tak aby każdemu obywatelowi zapewnić dostęp do dokumentów w jego własnym języku, co jest prawem demokracji, a także warunkiem zrozumienia i stosowania się do ustanowionego prawa. W praktyce realizacją obowiązującego reżimu językowego zajmują się Służby Tłumaczeniowe powołane przez Komisję Europejską. Aby usprawnić swoją pracę korzystają one z szeregu różnorodnych i stale doskonalonych narzędzi wspomagających, m.in.: aplikacji administrujących, technologii pamięci tłumaczeniowych, systemów tłumaczenia maszynowego, systemów rozpoznawania mowy, a także systematycznie uzupełnianych terminologicznych i dokumentacyjnych baz danych.
W gronie przyszłych państw-członków Unii Europejskiej znajduje się także Polska. Wstąpienie w wielojęzyczne struktury Wspólnoty wymaga i od nas tłumaczenia całości ogromnego dorobku prawa unijnego (obecnego i przyszłego) na język polski. W związku z planowanym przyjęciem języka polskiego do rodziny oficjalnych języków Wspólnoty, jak również faktem marginalnej znajomości naszego języka poza granicami Polski, rozwijanie narzędzi wspomagających przekład staje się sprawą priorytetową i leży w gestii kraju wstępującego.
Celem pracy jest przedstawienie Unii Europejskiej od strony powstania i pracy jej Służb Tłumaczeniowych, co w dalszej części pozwala na skoncentrowanie się na narzędziach wspomagających pracę tłumaczy zatrudnionych w Służbach. W związku z bliskim rozszerzeniem Wspólnoty praca została poszerzona o aspekt "polski" tj. rozwiązania organizacyjne i techniczne przyjęte w obliczu konieczności tłumaczenia m.in. całego dorobku prawnego Unii.
Praca podzielona jest na cztery rozdziały. Rozdział pierwszy wprowadza, a następnie rozszerza pojęcie Unii Europejskiej jako organizmu wielojęzycznego poprzez przedstawienie podstaw prawnych funkcjonowania tak dużej liczby języków oficjalnych w jej granicach. Następnie prezentuje strukturę, zakres i sposób działania Służb Tłumaczeniowych Komisji Europejskiej, charakter i zakres dokumentów tłumaczonych przez Służby, a także przewidywane drogi ich rozwoju w obliczu największego w dotychczasowej historii rozszerzenia Unii Europejskiej o nowe kraje członkowskie.
Ciągłe przesuwanie granic Wspólnoty oraz stale rosnące obciążenie tłumaczy pracą dało impuls do rozwoju narzędzi usprawniających pracę tłumaczeniową, dlatego rozdział drugi obejmuje przede wszystkim opis narzędzi wspomagających pracę tłumacza w Służbach Tłumaczeniowych Komisji Europejskiej: od narzędzi administrujących (zarządzających procesem tłumaczenia) i dokumentacyjnych (archiwizujących), przez narzędzia terminologiczne i technologie pamięci tłumaczeniowych aż do systemów tłumaczenia półautomatycznego i maszynowego. Rozdział kończy się opisem systemu Euramis, który łączy wszystkie dostępne narzędzia i zasoby w całość, eliminując tym samym konieczność osobnego korzystania z wszystkich dostępnych środków. Dodatkowo ta część opisuje organizację pracy w Służbach Tłumaczeniowych koncentrując się na próbie odpowiedzi na pytania jak stosowanie narzędzi wspomagających wpłynęło na pracę tłumacza, efekt jego pracy i sam proces tłumaczenia.
Rozdział trzeci przedstawia stopień przygotowania Polski do wejścia w wielojęzyczne struktury Unii, zwracając szczególną uwagę na organizację pracy odpowiednich jednostek zajmujących się tłumaczeniem oraz analizując drogę tłumaczonego dokumentu aż do chwili przekazania go do weryfikacji Komisji Europejskiej. Centralną częścią rozdziału jest opis polskich projektów z zakresu narzędzi wspomagających pracę tłumacza dokonujących przekładu z języka polskiego i/lub na język polski: MATCHPAD, POLENG i LexiTools.
Badania w rozdziale czwartym sprawdzają przydatność dwóch systemów - LexiTools i POLENG pod kątem tłumaczenia dokumentów powstających w Komisji Europejskiej. Porównanie nastąpiło w oparciu o oryginalne fragmenty tekstu Traktatu Akcesyjnego, Traktatu o Unii Europejskiej i Dyrektyw w językach polskim i angielskim.
W pracy oparłam się przede wszystkim na materiałach Komisji Europejskiej dostępnych na jej stronach internetowych (w języku angielskim) dotyczących narzędzi stosowanych w zakresie wspomagania przekładu, a także organizacji i pracy Służb Tłumaczeniowych.
W części dotyczącej Polski oparłam się na literaturze z dziedziny integracji europejskiej, a obejmującej Polskę i jej przygotowania do wstąpienia w wielojęzyczne struktury Unii Europejskiej, a także na dokumentacji projektów lub systemów mogących wspomóc pracę tłumaczeniową w zakresie języka polskiego.
Spis treści
- 1.1. Podstawy prawne wielojęzyczności Unii Europejskiej
- 1.2. Wielojęzyczność Unii Europejskiej
- 1.3. Języki Unii Europejskiej
- 1.4. Służby Tłumaczeniowe Komisji Europejskiej
- 1.5. Charakter i zakres tłumaczonych dokumentów
- 1.6. Nowe rozwiązania w pracy Służb Tłumaczeniowych w obliczu rozszerzenia Unii Europejskiej
Unia Europejska jest związkiem państw europejskich, utworzonym na mocy traktatu z Maastricht zawartym 7 lutego 1992 roku przez państwa-członków Wspólnot Europejskich: Europejskiej Wspólnoty Gospodarczej, Europejskiej Wspólnoty Węgla i Stali oraz Europejskiej Wspólnoty Energii Atomowej. Obecnie w jej skład wchodzi 15 państw, są to: Austria, Belgia, Dania, Francja, Finlandia, Grecja, Hiszpania, Holandia, Irlandia, Luksemburg, Niemcy, Portugalia, Szwecja, Wielka Brytania i Włochy.
Jednym z organów o największym znaczeniu w Unii Europejskiej jest Komisja Europejska. Wśród ogólnych kompetencji Komisji do najważniejszych należą: pełnienie funkcji organu stanowiącego prawo - inicjowanie i przygotowywanie większości uchwał Rady Unii Europejskiej, funkcji organu zarządzającego - administruje ona środkami pochodzącymi z funduszy Unii i wykonuje budżet oraz funkcji organu kontrolnego - stoi na straży przestrzegania prawa wspólnotowego, stąd jej przydomek "strażnika traktatów"[ 1]. Komisja Europejska ma charakter ponadnarodowy, są w niej reprezentowani przedstawiciele wszystkich państw członkowskich, ale nie są oni związani instrukcjami państw macierzystych. Komisja Europejska ma prawo do wydawania samodzielnych uchwał, pozbawionych jednak mocy wiążącej tj. zaleceń i opinii. W ramach funkcji zarządzającej Komisja wydaje tzw. uchwały nienazwane - jak np. rozporządzenia finansowe, oceny, raporty, komunikaty, powszechnie obowiązujące ustalenia, akceptacje. Do dziedzin najbardziej absorbujących Komisję należą: unia celna, wspólna polityka rolna, kwestie związane z konkurencją czy zarządzanie tzw. Funduszami Strukturalnymi. Komisja negocjuje również umowy międzynarodowe, utrzymuje stosunki z innymi organizacjami międzynarodowymi, realizuje bierne i czynne prawo legislacji.
Zasadniczym celem zjednoczonej Europy jest "tworzenie coraz ściślejszego związku między narodami Europy, w którym decyzje podejmowane są z możliwie najwyższym poszanowaniem zasady otwartości i jak najbliżej obywateli"[ 2]. Unia Europejska chce mieć nie tylko wspólny rynek, ale także prowadzić wspólną politykę zagraniczną i bezpieczeństwa. Jej przedstawiciele mają mówić jednym głosem. Ale nie jednym językiem.
Już na samym początku realizacji procesu integracji europejskiej, w latach pięćdziesiątych XX wieku, postanowiono, że językami oficjalnymi tworzonej Wspólnoty będą języki oficjalne krajów członkowskich. Podstawy prawne bezprecedensowego w skali świata pluralizmu językowego ówczesnej Europejskiej Wspólnoty Gospodarczej stworzyły postanowienia art. 290 Traktatu Rzymskiego o utworzeniu Europejskiej Wspólnoty Gospodarczej[ 3], który stwierdza, że "system językowy instytucji Wspólnoty ustala Rada Ministrów działając jednomyślnie, bez uszczerbku dla postanowienia Regulaminu Trybunału Sprawiedliwości"[ 4].
Wykonując nałożone na nią w tym zakresie obowiązki Rada Ministrów przedmiotem swego pierwszego aktu prawnego najwyższej rangi, jakim jest rozporządzenie, uczyniła właśnie kwestie językowe, co stanowiło podstawę prawną wielojęzyczności Wspólnoty. W wydanym zaraz na początku swojego funkcjonowania, bo 15 kwietnia 1958 roku Rozporządzeniu nr 1 postanowiła w art. 1, że: "Oficjalnymi oraz roboczymi językami instytucji Wspólnot Europejskich są francuski, holenderski, niemiecki i włoski"[ 5]. Pierwszymi krajami członkowskimi były wtedy Belgia, Francja, Holandia, Luksemburg, Niemcy i Włochy. Rozporządzenie to było kilkakrotnie nowelizowane w miarę sukcesywnego rozszerzania składu członkowskiego Wspólnot Europejskich, a potem Unii Europejskiej[ 6]. Decyzję, który język danego kraju zasili rodzinę języków Wspólnoty i będzie językiem oficjalnym do kontaktów z instytucjami Wspólnoty pozostawiono w gestii danego kraju wstępującego. Języki oficjalne nowo przyjętych państw członkowskich zyskiwały status języka oficjalnego i roboczego Wspólnoty Europejskiej czy późniejszej Unii Europejskiej.
Rozporządzenie nr 1 regulowało także rodzaj i charakter aktów prawnych i dokumentów, które muszą być sporządzone we wszystkich językach oficjalnych. Przede wszystkim legislacja stanowiona przez Unię musi być publikowana w każdym języku oficjalnym, a teksty traktatów czy ustawodawstwa wspólnotowego: rozporządzeń, zarządzeń, norm prawnych, dyrektyw, ustaw, regulacji itp., a także rozstrzygnięcia Trybunału Sprawiedliwości powinny być jednakowo autentyczne we wszystkich wersjach językowych, co oznacza, że mają tę samą moc wiążącą - z punktu widzenia prawa słowa w nich zawarte muszą być interpretowane w taki sam sposób każdym języku oficjalnym.
Wspomniane Rozporządzenie w art. 2 nakładało również na instytucje Wspólnot obowiązek przesyłania dokumentów do państwa członkowskiego w jego języku oficjalnym. Natomiast dokumenty wysyłane przez państwo członkowskie (lub obywatela państwa członkowskiego) do którejkolwiek z instytucji Wspólnot, mogą być sporządzone w którymkolwiek języku oficjalnym Wspólnoty i wówczas odpowiedź powinna być dana w tym samym języku (art. 3). Kolejne przepisy rozporządzenia określają reguły postępowania w zakresie języków, które obowiązują instytucje unijne przy zwracaniu się do państw członkowskich posiadających dwa języki oficjalne (np. Belgia). Na mocy art. 5 Dziennik Urzędowy Wspólnot Europejskich publikowany jest we wszystkich językach urzędowych Wspólnot.
Zgodnie z art. 6 Traktatu z Maastricht (zwanego także Traktatem o Unii Europejskiej), "Unia szanuje tożsamość narodową swoich Państw Członkowskich"[ 7], a więc także język danego państwa, ponieważ jest on elementem tożsamości narodowej. Zaznacza, że Komisja Europejska i inne instytucje Wspólnoty istnieją po to, aby służyć Unii i jej obywatelom - czyli wspólnocie ludzi mówiących różnymi językami.
Zasadę wielojęzyczności wzmocnił art. 21 Traktatu Amsterdamskiego[ 8], który wprowadził dla obywateli Unii możliwość używania ich własnego języka w ewentualnych kontaktach z instytucjami - podobną gwarancję możemy znaleźć już wcześniej w art. 2 Rozporządzenia nr 1 z 1958 roku. Traktat Amsterdamski w art. 255 postanawia także, iż "Każdy obywatel Unii Europejskiej ma prawo wglądu do dokumentów stanowionych przez Parlament Europejski, Radę Ministrów i Komisję Europejską"[ 9], tym samym akcentuje konieczność tłumaczenia unijnej legislacji, tak aby zapewnić wersję językową zrozumiałą dla każdego obywatela, ponieważ prawo wspólnotowe wymaga, aby ci, którzy je stosują, mogli je czytać w swoim języku.
W Karcie Praw Podstawowych Unii Europejskiej[ 10] w art. 18 (Prawo dostępu do informacji) kolejny raz czytamy, iż "Każdy obywatel Unii i każdy jej stały mieszkaniec ma prawo dostępu do dokumentów Parlamentu Europejskiego, Rady oraz Komisji." Art. 22 o Równości i niedyskryminacji zakazuje jakiejkolwiek dyskryminacji ze względu m.in. na język. W art. 27 (Stosunki z administracją) czytamy, że "Każda osoba ma prawo do załatwienia jej spraw w sposób bezstronny, rzetelny i w rozsądnym terminie przez instytucje i organy Unii", a prawo to obejmuje prawo każdej osoby do osobistego przedstawienia sprawy zanim zostanie wydana w stosunku do niej jakakolwiek negatywna decyzja, a także prawo każdej osoby do dostępu do jej akt sprawy, przy poszanowaniu uprawnionych interesów poufności i tajemnicy handlowej oraz obowiązek organu administracji uzasadnienia decyzji. Dlatego też "Każda osoba może przedstawić swoją sprawę instytucji Unii w jednym z jej oficjalnych języków oraz musi otrzymać odpowiedź w tym języku."
Dodatkowo, każda z instytucji Wspólnoty posiada własne reguły stosowania reżimu językowego. Również w stosunku do umów międzynarodowych stosuje się szczególne reguły, określane każdorazowo, w zależności od państwa lub organizacji będących stronami umowy.
Stosowana w Unii Europejskiej zasada wielojęzyczności polega na zapewnieniu obywatelom, administracjom narodowym, podmiotom gospodarczym oraz sądom Państw Członkowskich dostępu do przepisów prawnych w ich własnych językach i na zagwarantowaniu im, również w ich językach, dostępu do instytucji Unii. W ten sposób wszystkie Państwa Członkowskie i wszyscy obywatele Unii traktowani są w kontaktach z nią równorzędnie.
Z jednej strony możliwe jest stwierdzenie, że Unia Europejska "mówi jednym głosem" - prowadzi wspólną politykę m.in. w zakresie gospodarki, rolnictwa, ekologii, wspólną politykę zagraniczną, z drugiej strony jej obywatele nie posługują się jednym językiem.
Około 370 milionów ludzi zamieszkujących 15 państw członkowskich Unii Europejskiej posługuje się łącznie przyjętymi przez nią 11 językami oficjalnymi, z tego powodu o Unii mówimy, że jest wspólnotą wielojęzyczną, multilingualną.
Europa jest obszarem charakteryzującym się dużą różnorodnością kulturową, a więc również językową. Jednym z celów ojców założycieli Unii Europejskiej było zapewnienie poszanowania i ochrony tego bogactwa. Dlaczego jest to tak ważne?
Totalna językowa unifikacja Europy byłaby błędem. Języki Europy są częścią jej ogromnego i różnorodnego dziedzictwa kulturowego i jako takie powinny być pielęgnowane jako atrybut narodowej i osobistej tożsamości, część przebogatego i fascynującego w swej różnorodności dziedzictwa kulturowego państw członkowskich, wyznacznik odrębności kulturowej, etnicznej i terytorialnej. Każdy język ma swoje bogactwo, oddaje własną wizję świata, posiada niepowtarzalne walory, nie tylko komunikacyjne, ale i estetyczne czy ekspresyjne.
Europa przeszłości, przyszłości i teraźniejszości jest wielojęzyczna, bo wielojęzyczność jest podstawową siłą Europy. W kontekście pluralizmu językowego Unii Europejskiej znaczenie słowa "wielojęzyczny" wychodzi daleko poza swoją definicję słownikową "posługujący się kilkoma, wieloma językami; różnojęzyczny lub opublikowany, napisany, wygłaszany w wielu, kilku językach"[ 11]. W "słowniku" zjednoczonej Europy pojęcie to ma specjalne znaczenie: równych praw dla wszystkich języków oficjalnych, zostało więc rozszerzone, aby objąć fundamentalną zasadę, że wszystkie języki oficjalne, niezależnie od tego, w jakim stopniu znane są poza granicami danych krajów, cieszą się równymi prawami. Zasada ta ma wyraźny wymiar demokratyczny, stawiając znak równości między wszystkimi językami oficjalnymi państw członkowskich, a równocześnie między samymi państwami członkowskimi, niezależnie od znaczenia politycznego i gospodarczego, wielkości terytorium tych państw, ich położenia czy liczby ludności.
Jednakowy status formalny języków oficjalnych wszystkich państw członkowskich, stanowiących jednocześnie języki oficjalne Unii, jest jednym z podstawowych elementów jej filozofii politycznej, dlatego jakiekolwiek nastawienie, które nie respektowałoby języków, którymi posługują się mieszkańcy Unii, podkopałoby fundamenty unijnej filozofii. Pluralizm językowy obowiązujący w Unii Europejskiej to jej "kamień węgielny", jedna z jej fundamentalnych zasad przyjęta w imię demokracji i wynikająca ze specyfiki prawa wspólnotowego. Dlatego też zasada równości językowej znalazła się od samego początku w traktatach ustanawiających Wspólnoty Europejskie. W tym względzie Unia Europejska wyróżnia się spośród innych organizacji międzynarodowych.
Często pada pytanie czy należy utrzymywać aż tyle języków oficjalnych? Dlaczego nie można zmniejszyć tej liczby do kilku podstawowych, tak jak ma to miejsce w UN, NATO czy ONZ[ 12] i innych organizacjach międzynarodowych?
Odpowiedź na to pytanie jest prosta: w przeciwieństwie do innych międzynarodowych organizacji Unia Europejska stanowi prawo, które staje się prawem narodowym krajów członkowskich - bezpośrednio obowiązującym wszystkie kraje członkowskie oraz obywateli Wspólnoty. Prawodawstwo musi być wyrażone w oficjalnym języku danego kraju. Nie możemy oczekiwać, iż obywatele będą stosować się do prawa, jeśli nie będą w stanie go zrozumieć, a pełne zrozumienie jest możliwe tylko, jeśli czytają je w swoim własnym języku. Zasada wielojęzyczności gwarantuje bezpieczeństwo prawne, czyli równość wszystkich obywateli i państw członkowskich wobec prawa oraz gwarantuje dostęp na równych warunkach do aktów prawnych i instytucji Unii. Nieznajomość prawa nie chroni, ale nikt nie może podlegać prawu w niezrozumiałym dla niego języku.
Użycie języków oficjalnych gwarantuje jasne i wiarygodne teksty, więc każdy obywatel jest w stanie zrozumieć prawa, które go obowiązują, jest dobrze poinformowany i może zabierać głos w interesujących go sprawach, co stanowi zasadniczy warunek przejrzystej i demokratycznej Wspólnoty.
Słowo "Unia" oznacza głęboki poziom integracji, aspiruje do bycia "Unią mieszkańców". Komisja Europejska i inne instytucje Unii Europejskiej istnieją, aby służyć Unii i jej mieszkańcom - wspólnocie ludzi o różnorodnych zwyczajach, cechach, mówiących różnymi językami. Jest to wspólnota inna od tradycyjnych organizacji międzyrządowych. Instytucje Unii mają być tak dostępne i otwarte dla wszystkich, zarówno mieszkańców, jak i departamentów rządowych poszczególnych krajów, ale także różnych związków i stowarzyszeń działających w krajach członkowskich. Komisja Europejska za swój obowiązek uznaje kształtowanie demokracji, w której atrybuty i wartości jednostkowe, lokalne, regionalne czy narodowe są szanowane, chronione i zabezpieczone.
Poszanowanie zasady wielojęzyczności Europy ma podstawowe znaczenie dla funkcjonowania instytucji unijnych. Dotychczasowe próby podejmowane wyłącznie w trybie roboczym na posiedzeniach Komisji czy Parlamentu Europejskiego, zmierzające do ograniczenia liczby języków urzędowych, kończyły się niepowodzeniem i wywoływały wiele kontrowersji. Kwestie poruszane na posiedzeniach komisji czy sesjach plenarnych parlamentu są często niezwykle złożone, a skuteczne przekazanie poglądów danego kraju wymaga nie tylko rzeczowych argumentów, ale także zakłada konieczność swobodnego wypowiedzenia się i przekazania swoich racji, co możliwe jest prawie wyłącznie w języku ojczystym. Z drugiej strony pozwala zrozumieć stronę zabierającą głos w innym, nieznanym języku. Sytuacja, w której niektórzy wypowiadaliby się we własnym języku, a inni musieliby używać języka obcego, wskazywałaby wyraźnie na nierówność obywateli Unii, a także, paradoksalnie, stanowiłaby wyraźne utrudnienie dla sprawnego funkcjonowania instytucji unijnych. Co więcej, rządy krajów członkowskich w codziennej pracy posługują się swoim językiem ojczystym, więc gdyby nie m.in. Służby Tłumaczeniowe Komisji Europejskiej cały problem z tłumaczeniem i rozumieniem spoczywałby wtedy w rękach rządów krajów członkowskich.
Nie tylko kwestia zrozumienia prawodawstwa jest przyczyną utrzymywania wielojęzyczności Unii. Nie można zmniejszyć liczby języków oficjalnych także z powodu trudności w wyborze, który z języków ewentualnie wyłączyć z grona języków oficjalnych Wspólnoty. Każda próba ograniczenia liczby języków urzędowych była dotąd odrzucana, gdyż nieobecność języka narodowego we wspomnianej roli wiązana jest z obawami marginalizacji danej kultury i danego kraju na arenie międzynarodowej.
Często argumentem przemawiającym za ograniczeniem liczby języków są rzekome koszty tłumaczeń - jednak w obecnym systemie koszty te są relatywnie niskie i wynoszą około 2 euro rocznie w przeliczeniu na jednego mieszkańca[ 13].
Zapewnienie obywatelom państw członkowskich wszystkich wersji językowych dokumentów wychodzących z Komisji Europejskiej jest jej prawnym obowiązkiem i stanowi poszanowanie zasady demokracji, gwarantuje równość wszystkich wobec prawa, które nie może zostać nałożone na obywatela w języku, którego nie rozumie lub może nie zrozumieć w pełni.
W Unii Europejskiej języki mogą mieć trojaki status: języków autentycznych traktatów założycielskich, języków urzędowych oraz języków roboczych[ 14]. Językiem autentycznym umowy (w szczególności ma to zastosowanie do traktatów) jest język, w którym dokument ten został sporządzony i wówczas jedynie ta konkretna wersja językowa może stanowić podstawę do interpretacji jego zapisów.
Podstawowy przepis w zakresie wielojęzyczności niesie art. 290 Traktatu Rzymskiego, na mocy którego przyjęto Rozporządzenie nr 1 Rady Ministrów z dnia 15 kwietnia 1958 roku, które - czterem wówczas językom - nadało równy status języków urzędowych i języków roboczych. Na mocy wspomnianego Rozporządzenia z późniejszymi zmianami każdorazowo, gdy do grona państw członkowskich zostają przyjęte nowe kraje, status języka urzędowego uzyskiwały języki oficjalne wskazane przez nowe państwa członkowskie w ich traktatach akcesyjnych. I tak od 1958 roku do Wspólnot należą Belgia, Francja, Holandia, Luksemburg, Niemcy i Włochy, a pierwszymi oficjalnymi językami są cztery: francuski, holenderski, niemiecki i włoski. W 1973 roku do Wspólnot przyjęto Wielką Brytanię, Danię i Irlandię, a do listy języków oficjalnych dodano dwa nowe - angielski i duński. Kolejnym przyjętym w 1981 roku krajem była Grecja i język grecki, następnie w 1986 roku do grona krajów członkowskich dołączyły Hiszpania i Portugalia, a do rodziny języków - hiszpański oraz portugalski, a ostatnimi dodanymi 1 stycznia 1995 roku były języki skandynawskie - szwedzki i fiński, kiedy do Unii Europejskiej dołączyły Szwecja i Finlandia, a także Austria z językiem niemieckim, który jednak już wcześniej funkcjonował jako język urzędowy. Status języków oficjalnych Unii Europejskiej ma obecnie 11 języków piętnastu państw członkowskich (wszystkie języki państw członkowskich z wyjątkiem irlandzkiego, który ma nieco ograniczony status - na ten język tłumaczone są tylko niektóre dokumenty, m.in. traktaty).
Status języków roboczych nie został nigdzie formalnie ujęty, jednakże są nimi aktualnie francuski i angielski. Są to języki, którymi w codziennej pracy posługują się pracownicy instytucji wspólnotowych. Reguły dotyczące stosowania języków w postępowaniu sądowym określa Regulamin Trybunału Sprawiedliwości.
Istotną swobodę pozostawia poszczególnym instytucjom w zakresie języków art. 6 Rozporządzenia nr 1. I tak np. Parlament Europejski umożliwia deputowanym wypowiadanie się w każdym języku urzędowym, a wypowiedzi tłumaczone są na wszystkie pozostałe języki urzędowe. Można więc powiedzieć, że poza Komisją Europejską jedynie Parlament jest instytucją prawdziwie wielojęzyczną. W pozostałych instytucjach przeważa jeden język roboczy, tłumaczenia wykonywane są jedynie w przypadku dokumentów większej wagi.
Rosnąca liczba języków oficjalnych Wspólnoty przekłada się na wzrost teoretycznej liczby par językowych, na które muszą być dokonywane tłumaczenia. I tak liczba możliwych par językowych zwiększyła się od początkowych 12 w 1958 roku do 110 w chwili obecnej (ponieważ każdy z 11 języków może zostać przetłumaczony na 10 innych języków) i zmierza do 380 po przyjęciu do UE 10 nowych państw w 2004 roku[ 15].
W chwili obecnej jest mniej języków oficjalnych niż krajów członkowskich Unii Europejskiej, ponieważ w kilku krajach obowiązują te same języki (np. język niemiecki w Austrii i Niemczech, czy język francuski we Francji, Belgii i Luksemburgu). W przypadku krajów, które oczekują na wejście do Unii sytuacja nie jest tak prosta, ponieważ każdy z krajów Europy Środkowej i Wschodniej, który znajdzie się w Unii, posiada swój własny charakterystyczny język.
Dodanie nowych języków do oficjalnej grupy w maju 2004 roku, kiedy to Wspólnota rozszerzy się o 10 nowych państw, zwiększy liczbę możliwych kombinacji językowych, ponieważ nie planuje się zmiany polityki w zakresie wielojęzyczności. W Traktacie Akcesyjnym każdy kraj zastrzegł sobie - zgodnie z obowiązującym prawem, wprowadzenie do Wspólnoty swojego narodowego języka, więc sytuacja stanie się jeszcze bardziej złożona - dojdzie przynajmniej 9 nowych języków - estoński, litewski, łotewski, polski, czeski, słowacki, węgierki, słoweński i maltański. Liczba języków oficjalnych dojdzie do 20, co da teoretyczną liczbę 380 kombinacji językowych.
Specjalnymi przypadkami z punktu widzenia rozszerzenia Unii były Cypr i Malta. Cypr jest krajem dwujęzycznym z dwoma obowiązującymi językami oficjalnymi - greckim i tureckim. Za sprawą Grecji język grecki jest już w rodzinie języków Wspólnoty od 1981 roku, ale konstytucja Cypru gwarantuje także językowi tureckiemu status języka oficjalnego tego kraju, a ponieważ kwestię wyboru języka zostawia się w gestii kraju wstępującego, Cypr miał prawo zaproponować do kontaktów z Unią i jej instytucjami język turecki, ostatecznie jednak wybrał język grecki. Drugim specjalnym przypadkiem była Malta. Rząd tego kraju mógł podążyć za przykładem Irlandii, która nie upierała się, aby język irlandzki dołączył do grona języków oficjalnych Wspólnoty, a był używany jako język oficjalny w zakresie prawa pierwotnego (to znaczy traktatów), akceptując w pozostałych przypadkach język angielski. W przypadku Malty wybór pomiędzy językiem angielskim i maltańskim długo był sprawą otwartą. Na podstawie prawa Wspólnotowego rząd Malty miał pełne prawo wskazać język maltański (szerzej rozumiany w tym kraju niż język angielski) jako narodowy język swojego kraju w kontaktach z Unią Europejską i tak też ostatecznie zrobił. W dłuższym okresie potrzebne są także przygotowania do przyjęcia trzech kolejnych języków - bułgarskiego, rumuńskiego i tureckiego, w związku z planowanym przystąpieniem do Wspólnoty Bułgarii, Rumunii i Turcji w 2007 roku. Tak więc w niedalekiej perspektywie dojdzie do podwojenia liczby języków oficjalnych, a liczba możliwych par językowych może dojść do 506. Chociaż rozszerzenie rodziny języków dla Służb Tłumaczeniowych Komisji Europejskiej nie jest nowością, jednak nigdy w dotychczasowej historii Wspólnoty nie odbywało się to na taką skalę, a nowe języki są stosunkowo słabo znane w obecnych krajach członkowskich.
W kontaktach pomiędzy Komisją Europejską a krajami Europy Środkowej i Wschodniej rozpatruje się dwie sytuacje[ 16]. W pierwszym przypadku osoby w tych krajach stykając się z dokumentami napisanymi w jednym z głównych języków (angielskim, niemieckim lub francuskim) mają elementarną wiedzę o danym języku. Im pomocny będzie np. słownik (drukowany lub on-line) czy baza terminologiczna, które pozwolą im sprawdzić znaczenie nieznanych słów - przez co osoby te będą w stanie zrozumieć resztę tekstu. W drugiej sytuacji osoby mówiące językami Unii Europejskiej mając przed sobą dokumenty napisane w jednym z nowoprzyjętych języków często nie będą miały pojęcia o języku danego dokumentu - większość języków krajów Europy Środkowej i Wschodniej należy do różnych rodzin językowych, a osoba która chce zapoznać się z dokumentem nie jest w stanie nawet odgadnąć przybliżonego znaczenia zdań na podstawie podobieństwa wyrazów w obu językach. W tym przypadku uzasadniona wydaje się potrzeba rozwijania systemów tłumaczeniowych, które zapewniają przybliżoną, nieoszlifowaną wersję, która w pewnym stopniu pozwoli zrozumieć treść danego dokumentu.
Trudność we wzajemnym zrozumieniu "nowej" i "starej" grupy języków Europy wynika przede wszystkim z większej znajomości języków zachodnioeuropejskich wśród ludności Europy Środkowej i Wschodniej - dzięki upowszechnieniu nauki języków obcych (szczególnie zachodnioeuropejskich), a trudno w ogóle mówić o sytuacji odwrotnej, bo niewielu mieszkańców Unii może pochwalić się znajomością któregokolwiek z przyszłych języków Wspólnoty. Drugim czynnikiem utrudniającym zrozumienie jest pochodzenie poszczególnych języków z uwzględnieniem podziału na rodziny językowe. Łatwiejsza jest komunikacja w obrębie tej samej grupy językowej, ze względu na zbieżności występujące między poszczególnymi językami. Język polski, obok czeskiego, słowackiego i słoweńskiego, należy do grupy trudnych języków słowiańskich.
Rozkład ilościowy i procentowy ludności obecnej Wspólnoty Europejskiej, dla której dane języki są językami ojczystymi przedstawia się następująco: najwięcej ludzi posługuje się na co dzień językiem niemieckim - 90,5 milionów (Niemcy - 82 mln, Austria - 8 mln i Luksemburg - 0,5 mln), co stanowi 24,5% ludności Unii. Drugim najczęściej używanym językiem język francuski - posługuje się nim 60,8 miliona ludzi (około 4,1 mln w Belgii i 56,7 mln we Francji), co stanowi 16,4%. Na trzecim miejscu plasuje się język angielski - 60 milionów ludzi (56,5 mln w Wielkiej Brytanii i 3,5 mln w Irlandii), co daje 16,2% ogółu mieszkańców Wspólnoty. Język włoski jest pierwszym językiem dla 57,5 miliona mieszkańców Unii (15,5%), a hiszpański dla 39,3 miliona (10,6%). Następny w kolejności jest język holenderski, którym posługuje się 21,8 miliona mieszkańców Unii (15,6 mln w Holandii i 6,2 mln w Belgii), co stanowi 5,9% ogółu mieszkańców Wspólnoty. Kolejnymi językami są portugalski, którym posługuje się 10,6 miliona Europejczyków (2,9%), greckim mówi 10,5 miliona osób (2,8%), szwedzkim 8,85 miliona (2,4%), duńskim 5,3 miliony (1,4%) i fińskim 5,1 miliona osób (1,35%)[ 17].
Wśród obywateli przyszłych krajów członkowskich najwięcej osób jako pierwszym językiem posługuje się językiem polskim - 38,5 mln, czeskim 10,3 mln, węgierskim 10,1 mln, słowackim 5,4 mln, litewskim 3,7 mln, łotewskim 2,5 mln, słoweńskim 2 mln, estońskim 1,5 mln, greckim 760 tyś. (Cypr), a maltańskim 370 tyś.[ 18]
Po rozszerzeniu liczba mieszkańców Unii Europejskiej przekroczy 445 milionów, w tym układzie językiem polskim, jako pierwszym językiem, będzie się posługiwać 8,6% ogółu mieszkańców Wspólnoty.
Naturalną konsekwencją przyjętej w Unii Europejskiej zasady równości wszystkich języków oficjalnych było stworzenie bardzo rozbudowanych służb lingwistycznych - zatrudniających tłumaczy tekstu i tłumaczy konferencyjnych, które w praktyce muszą realizować obowiązujący reżim językowy.
Ciałem o kluczowym znaczeniu ze względu na inicjowanie i wprowadzanie w życie polityki Wspólnoty jest Komisja Europejska i to ona powołała do życia struktury potrzebne do realizowania tych funkcji: Służby Tłumaczeniowe Komisji Europejskiej, nazywane w skrócie od inicjałów francuskiego Service de Traduction jako SdT.
Do czerwca 1989 roku tłumacze pisemni w Komisji Europejskiej stanowili część personelu Dyrekcji Generalnej IX (Personel i Administracja). Po wejściu w życie w 1987 roku Jednolitego Aktu Europejskiego[ 19], konsekwencją czego było zwiększenie obowiązków tłumaczy pisemnych, Komisja utworzyła odrębną, niezależną jednostkę na prawach Dyrekcji Generalnej: Służbę Tłumaczeń Pisemnych Komisji Europejskiej (The European Commission's Translation Service). Jej pracą kieruje Dyrektor Generalny. Ze względu na liczbę zatrudnionych oraz ilość i zakres tłumaczonych dokumentów służba ta stanowi największą organizację tłumaczy pisemnych na świecie.
Struktura Służby Tłumaczeń Pisemnych składa się z dwóch dyrekcji, z których jedna zajmuje się właściwą pracą tłumaczeniową, druga obejmuje jednostki o charakterze wspierającym proces tłumaczenia. Dyrekcja wspierająca obejmuje sześć tzw. jednostek horyzontalnych. Dyrekcja tłumaczeniowa podzielona jest na siedem departamentów (dyrekcji) tematycznych (tzw. departments), oznaczonych literami od A do G[ 20]. Dyrekcje A-E znajdują się w Brukseli, natomiast pozostałe dwie w Luksemburgu, przy czym każda z dyrekcji ma swoją siedzibę w obu miastach.
Strukturę Służby Tłumaczeń Komisji Europejskiej przedstawia schemat:
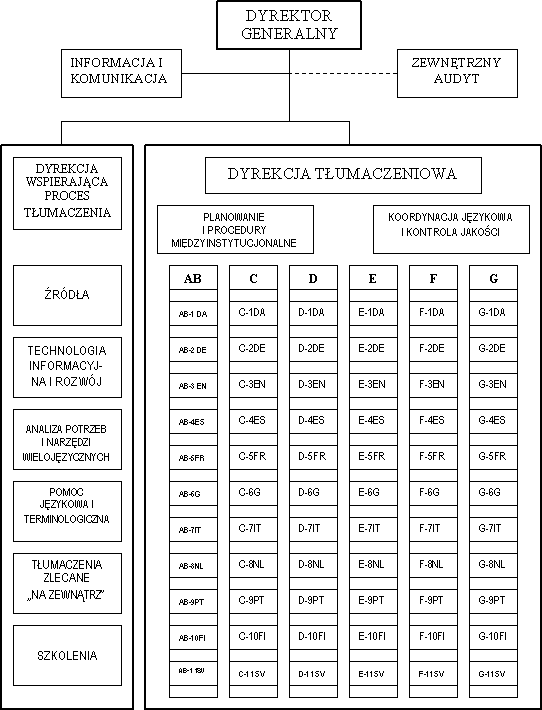
Zakres tematyczny przekładów dokonywanych przez tłumaczy pisemnych zgrupowanych w poszczególnych dyrekcjach przedstawia się następująco:
A - sprawy ogólne, administracyjne, prawne, budżet i kontrola finansowa;
B - gospodarka i finanse, rynek wewnętrzny i konkurencja;
C - rolnictwo, rybołówstwo, polityka regionalna i strukturalna;
D - stosunki międzynarodowe, unia celna, rozwój, rozszerzenie UE;
E - badania, energetyka, przemysł, środowisko, transport, telekomunikacja oraz pomoc dla hutnictwa;
F - sprawy socjalne, ochrona konsumenta, zasoby ludzkie;
G - statystyka (Eurostat), polityka wobec przedsiębiorstwa, kredyty, inwestycje, rynek i innowacje, publikacje.
Pracą tych tematycznych dyrekcji kierują dyrektorzy lub częściej kierownicy wydziałów zwani także doradcami tematycznymi (w pragmatyce służbowej w randze LA3). Personel Służby Tłumaczeń Pisemnych podzielony jest na 5 kategorii:
LA - tłumacze i specjaliści od terminologii;
A - pracownicy administracji, informatycy i pracownicy ds. zarządzania;
B - dokumentaliści, asystenci administracyjni i komputerowi;
C - sekretarki i personel biurowy;
D - gońcy, kurierzy itd.
LA3 - kierownik wydziału lub innej jednostki ds. tłumaczeń;
LA4 i LA5 - główny tłumacz tekstu lub konferencyjny, kontroler;
LA6 i LA7 - tłumacz tekstu, tłumacz konferencyjny;
LA8 - asystent tłumacza.
Każda z wymienionych wyżej dyrekcji tematycznych składa się z 11 zespołów (wydziałów, sekcji) językowych (tzw. language units), co odpowiada liczbie języków oficjalnych i roboczych Unii Europejskiej - po jednym zespole na każdy język. W sumie obecnie w Komisji są 66 sekcje językowe. Liczebność wspomnianych sekcji jest zróżnicowana w zależności od tego, czy dany język jest językiem roboczym (proceduralnym) czy nie. Jednostki języków roboczych (angielski, francuski i niemiecki, przy czym większość tekstów powstaje w językach angielskim i francuskim[ 22]) liczą po 21 dyplomowanych tłumaczy stopnia LA, zaś jednostki pozostałych języków tylko po 16 tłumaczy, a każda jednostka wspomagana jest dodatkowo przez personel pomocniczy. Po rozszerzeniu, przy założeniu, że dojdzie 9 nowych języków, przy zachowaniu obecnego systemu będzie łącznie 120 sekcji tłumaczeniowych[ 23].
Poza przedstawionymi siedmioma dyrekcjami tematycznymi stały element struktury Służby Tłumaczeń Pisemnych Komisji Europejskiej stanowi osiem zespołów (wydziałów) pomocniczych (tzw. support units). Prawie wszystkie mają swoje biura i personel w Brukseli i Luksemburgu. Trzy zespoły pomocnicze podlegają bezpośrednio Dyrektorowi Generalnemu Służby Tłumaczeń, pięć pozostałych natomiast mieści się w Dyrekcji ds. Ogólnych i Językowych. Personel tych zespołów składa się w części z tłumaczy koordynujących pracę każdego z jedenastu zespołów językowych (kategoria LA) oraz osób pełniących funkcje administracyjne i organizacyjne (personel kategorii A, B, C i D). Lingwistyczni koordynatorzy każdego z oficjalnych języków są odpowiedzialni za zapewnienie we wszystkich siedmiu dyrekcjach tematycznych odpowiedniej jakości przekładów w swoim języku tj. dokładność, prawidłowość, logika, stosowanie właściwej terminologii, poprawność językowa, styl czy poziom językowy dostosowany do danego tekstu. Koordynatorzy lingwistyczni są również odpowiedzialni za: utrzymywanie kontaktów z i między tłumaczami w swoim języku, rekrutację personelu do tłumaczenia na ten język, szkolenie tych tłumaczy, oferowanie pomocy lingwistycznej oraz kierowanie tekstów do tłumaczenia na zewnątrz (freelance translation).
Tematyczna struktura Służby Tłumaczeń odzwierciedla sposób organizacji samej Komisji i umożliwia skuteczną współpracę z poszczególnymi jej wydziałami, a także określony stopień specjalizacji. Tłumacze pracują w sekcjach językowych, które specjalizują się w określonych dziedzinach. Etatowi tłumacze to eksperci językoznawcy, ale także specjaliści - prawnicy, ekonomiści, inżynierowie, księgowi, informatycy, a od czasu do czasu także historycy czy lekarze. Zakres słownictwa, jakim posługują się tłumacze, jest bardzo szeroki, są to dokumenty z dziedziny m.in. finansów, ekonomii, prawa, kultury, rolnictwa, nauki czy techniki. Ponieważ na wynik tłumaczenia nie składa się tylko doskonała znajomość danego języka, niezwykle istotne jest samo zrozumienie często skomplikowanego zagadnienia w jednym języku i dokładne oddanie go w terminologii języka docelowego. Aby sprostać ogromnym, tak pod względem ilościowym jak i jakościowym, zadaniom wymagającym najwyższych kwalifikacji zawodowych Służba Tłumaczeń Pisemnych musi zatrudniać lingwistów o ponadprzeciętnych umiejętnościach, wspomaganych w swej pracy przez najnowsze rozwiązania organizacyjne i pomoce naukowo-techniczne. Nacisk kładzie się na "kompletność". Tłumacz pracuje tylko ze słowem pisanym i musi nie tylko odtworzyć najważniejsze punkty wyrażone w oryginalnym tekście, ale oddać precyzyjnie ogół słownictwa dokumentu źródłowego w języku docelowym. Zadanie to pochłania więcej czasu niż tłumaczenie słowne (interpretacja) i angażuje więcej osób. Dlatego liczba osób zatrudnionych w UE przy tłumaczeniach pisemnych przewyższa liczbę tłumaczy ustnych w stosunku 3:1[ 24].
Wymagania co do kwalifikacji tłumaczy są bardzo rygorystyczne. Wymagane jest wykształcenie wyższe (uniwersyteckie lub równorzędne) lingwistyczne lub inne (ekonomia, prawo, nauki ścisłe). Warunkiem zatrudnienia jest znajomość języków - perfekcyjna języka ojczystego, będącego jednym z języków oficjalnych i roboczych UE oraz doskonała, co najmniej dwóch innych języków oficjalnych i roboczych UE. Od kandydatów na tłumaczy wymaga się przynajmniej 2 lat pracy w danym języku lub w odpowiedniej innej, przynajmniej jednej dziedzinie działalności UE (ekonomia, prawo, finanse, administracja itd.)[ 25].
W Służbie Tłumaczeń Pisemnych obowiązuje zasada tłumaczenia tylko w jednym kierunku - z języka obcego na język ojczysty, zwany językiem docelowym (target language). Tak więc tłumacz Hiszpan przekłada tekst wyłącznie z języka obcego na język hiszpański, Grek na grecki itd. Przestrzeganie tej reguły ma zapewnić odpowiednią adekwatność, jakość tłumaczenia i zrozumienie tekstu przez jak najszerszy krąg obywateli, posługujących się danym językiem. Jest ona czasem, chociaż bardzo rzadko, łamana ze względu na wyjątkowe obciążenie tłumaczy pilną pracą.
Na początku lat pięćdziesiątych, gdy posługiwano się czterema językami, zatrudnionych tłumaczy było kilkudziesięciu. Przy jedenastu językach na potrzeby Komisji Europejskiej pracuje około 1500 tłumaczy pisemnych plus około 600 osób personelu pomocniczego[ 26]. Wszystkie osoby zatrudnione w służbach lingwistycznych Komisji to mniej więcej 8% wszystkich zatrudnionych w niej urzędników (całość zatrudnienia Komisji wynosi około 24 600 urzędników[ 27]). Dodatkowo obecnie około 20% pracy wykonywana jest przez tłumaczy i agencje zewnętrzne[ 28].
Dokładną liczbę tłumaczy zatrudnionych do obsługi poszczególnych języków w 2002 roku przedstawia tab. 1.
Tabela 1.
Liczba tłumaczy zatrudnionych w Służbach Tłumaczeniowych w 2002 roku[ 29].

Roczne koszty obsługi tłumaczeń 11 języków dla wszystkich instytucji Wspólnoty to ok. 800 milionów euro[ 30] (0,8% całego budżetu Unii) - co przekłada się na około 2 euro na rok na obywatela Unii Europejskiej. Po przyjęciu nowych krajów koszty tłumaczeń nie powinny wzrosnąć znacząco, ponieważ równocześnie wzrośnie liczba obywateli, a co za tym idzie osób płacących podatki. Mając powyższe na uwadze, nie sposób oprzeć się wrażeniu, że debata na temat drastycznych kosztów utrzymywania wielojęzyczności wydaje się nieuzasadniona, a wszelkie działania zmierzające do ograniczenia liczby języków urzędowych wydają się mieć podłoże zgoła polityczne. Tak też zostanie dopóki używanie danego języka w Unii będzie wiązało się z pojęciem suwerenności narodowej oraz będzie rozpatrywane w kategorii bardziej lub mniej ważnego języka, czyli kraju.
Obciążenie tłumaczy tekstu jest bardzo duże. Służby tłumaczą około 1 300 000 stron rocznie. Dla przykładu w 2000 roku przetłumaczyły one około 1 400 000 stron[ 31] (włączając około 2000 stron w językach nie należących do języków oficjalnych UE). W latach poprzednich dane te były podobne. Prognozuje się, że w 2006 roku przy 9 nowych językach zapotrzebowanie na tłumaczenie osiągnie 2 400 000 stron rocznie[ 32].
W Służbie Tłumaczeń Pisemnych głównymi językami docelowymi są niemiecki, angielski i francuski. Natomiast wśród języków źródłowych, z których się tłumaczy zdecydowanie dominują angielski i francuski, co potwierdzają dane liczbowe zawarte w tab. 2.
Tabela 2.
Liczba stron i zestawienie procentowe stron przetłumaczonych przez Służby Tłumaczeniowe w 2001 roku (z języka źródłowego i na język docelowy)[ 33].

Służby Tłumaczeniowe czeka reforma wewnętrzna. Prognozuje się, że w momencie rozszerzenia rzesza tłumaczy powiększy się o około półtora tysiąca osób - około 110 osób dla każdego nowego języka[ 34]. Znalezienie odpowiedniej liczby tłumaczy angielsko, francusko i niemieckojęzycznych znających w wystarczającym stopniu języki przyszłych krajów członkowskich jest bardzo trudnym zadaniem, z jakim zmagają się Służby Tłumaczeniowe. Trwają dyskusje nad możliwymi do przyjęcia rozwiązaniami, tak aby w momencie rozszerzenia być przygotowanym do przyjęcia grupy nowych języków oficjalnych. Ponieważ biegłe opanowanie danego języka trwa kilka lat, dlatego już od 1996 roku 150 tłumaczy zatrudnionych w Służbie Tłumaczeniowej Komisji uczestniczy w kursach języka polskiego, węgierskiego, czeskiego, a także estońskiego i słoweńskiego[ 35]. I tu należy zwrócić uwagę na fakt, że nowe kraje członkowskie wzbogacą Unię nie tylko swoim językiem, ale także odmienną kulturą i historią, a które mają zupełnie inny system prawa, edukacji, opieki społecznej itd. Wszystkie te zagadnienia będą musiały zostać zrozumiane tak poprawnie jak sam język. Jest to jednak naturalnym procesem w jednoczącej się Europie. Od samego początku procesu integracji europejskiej tłumacze stopniowo zmuszeni byli pokrywać coraz to nowe dziedziny tworzonej Wspólnoty. Traktaty, które ustanowiły Wspólnotę Europejską, postawiły tłumaczy starego kontynentu wobec wyzwania bez sobie równych: w niewielkim czasie zostali oni zmuszeni do pracy w domenach, jakie dotąd były ograniczone do wnętrza ich narodowych granic językowych. Na pierwszym miejscu był węgiel i stal, potem nowe dziedziny takie jak atomistyka, rozwój regionalny czy wspólna polityka rolna. Zakres i rodzaj tłumaczonych dokumentów rozszerzał się wraz z rozwojem technicznym, politycznym i terytorialnym.
Służby Lingwistyczne Unii Europejskiej usytuowane są przede wszystkim w strukturze Komisji Europejskiej. Jednak większość instytucji wspólnotowych także posiada własne służby tłumaczeniowe, dokonujące przekładu na ich potrzeby. W skład struktury tłumaczeniowej Komisji Europejskiej oprócz Służby Tłumaczeń wchodzi druga jednostka - Wspólna Służba Tłumaczeń Ustnych i Konferencji, własne struktury tłumaczeniowe posiada Parlament Europejski, Rada, Komitet Regionów oraz Trybunał Sprawiedliwości Wspólnot Europejskich. Rodzaj tłumaczonych dokumentów oraz liczba języków, na jakie jest dokonywany przekład są ściśle związane z zadaniami instytucji. Można to z łatwością prześledzić przyglądając się procesowi powstawania aktów prawnych - ciężar stworzenia projektu już we wszystkich wersjach językowych przypada w udziale Komisji Europejskiej (jako inicjatorowi procesu legislacyjnego), nad kolejnymi uzgadnianymi wersjami dokumentu pracuje Rada i to ona nadaje im ostateczny kształt. Za korektę redakcyjną dokumentów odpowiada Urząd Publikacji Wspólnoty Europejskiej. Każda służba tłumaczeń obsługuje pod względem tłumaczeń instytucję, przy której działa. Wyjątkiem od tej zasady jest Wspólna Służba Tłumaczeń Ustnych i Konferencji Komisji Europejskiej, która świadczy usługi także dla innych organów wspólnotowych i tym samym ma charakter międzyinstytucjonalny.
Ze względu na duże, ciągłe rosnące obciążenie pracą będące odbiciem niezwykle szerokiej i różnorodnej działalności Unii Europejskiej, a potęgujące się jeszcze dodatkowo w pewnych okresach, Służba Tłumaczeń Pisemnych korzysta z pomocy tłumaczy niezatrudnionych w jej strukturze, zlecając przekłady dobieranym w wyniku otwartych konkursów agencjom tłumaczy oraz samodzielnym tłumaczom zewnętrznym. Pracując na rzecz Unii mają oni zapewniony dostęp do źródeł informacji i narzędzi, z których korzystają tłumacze zatrudnieni w Służbie.
Wszystkie najważniejsze dokumenty, w tym zwłaszcza te o charakterze legislacyjnym, wymagające określonej formy i ścisłego współdziałania SdT z ich autorami (jak np. projekty dyrektyw przedkładane przez Komisję Radzie, a także dokumenty pilne czy tajne), muszą być tłumaczone na miejscu przez etatowych tłumaczy unijnych. Przekład innych może być dokonany "na zewnątrz". Tłumaczom spoza Służby Tłumaczeń Pisemnych zleca się tłumaczenia tekstów niewymagających dokładnej znajomości "eurożargonu". Dotyczą one np. bieżących spraw związanych z funkcjonowaniem jednolitego rynku, jak ogłoszenia przetargów, normy techniczne, sprawozdania itp. Mieszczą się tu również przekłady z języków państw, które nie są członkami Unii (w tym z polskiego).
Tłumaczenia wykonywane "na zewnątrz" stanowią dość znaczny procent ogólnej ilości przekładów SdT. W latach dziewięćdziesiątych udział ten wynosił około 10-15% ogólnej ilości tłumaczeń pisemnych, a w 1999 roku wskaźnik ten stanowił 18,7%.[ 36]. Dla przykładu w 2001 roku przetłumaczono w ten sposób 244 102 strony[ 37]. Prognozuje się, że udział tłumaczy "zewnętrznych" będzie nadal rósł i prawdopodobnie osiągnie 30% w najbliższych latach[ 38].
Zgodnie z artykułami 4 i 5 Rozporządzenia nr 1 we wszystkich jedenastu językach oficjalnych UE muszą być sporządzone wspólnotowe akty prawne o najwyższej randze, takie jak: rozporządzenia i dyrektywy oraz inne teksty o zasięgu ogólnym np. "Dziennik Urzędowy Wspólnot Europejskich". Interpretacja terminu "zasięg ogólny" leży w gestii poszczególnych instytucji unijnych, które zgodnie z art. 6 Rozporządzenia, mogą określić w swoich regulaminach wewnętrznych stosowany przez nie reżim językowy i tym samym charakter dokumentów o zasięgu ogólnym, pod warunkiem poszanowanie Rozporządzenia Rady Ministrów. Inne wspólnotowe akty prawne i dokumenty nie podlegają obligatoryjnemu tłumaczeniu na wszystkie języki oficjalne Unii Europejskiej.
Na wszystkie języki oficjalne przekładane są także teksty stanowiące materiał wyjściowy dla przyjmowanych później aktów prawnych, mających moc wiążącą. I tak na przykład w przypadku dyrektywy tłumaczona jest ostateczna wersja jej projektu przedłożona przez Komisję Radzie UE i Parlamentowi Europejskiemu; komunikat prasowy obwieszczający o takim przedłożeniu; włączenie do projektu poprawek zgłoszonych przez Parlament, interpelacje jego deputowanych na temat stosowania dyrektywy w państwach członkowskich oraz okresowe raporty Komisji przedkładane Radzie Europejskiej i Parlamentowi Europejskiemu o stanie wprowadzania dyrektyw w krajach członkowskich. Pozostałe teksty prawne, stanowiące poszczególne stadia tworzenia dyrektywy są tłumaczone zazwyczaj na dwa, trzy języki najczęściej używane (angielski, francuski, hiszpański lub niemiecki). Jako reguła tłumaczenie na wszystkie języki oficjalne i urzędowe UE obowiązuje w przypadku opracowywanych przez Komisję Zielonych i Białych Ksiąg, przeznaczonych do szeroko dostępnej konsultacji. Podstawę prawną obligatoryjnego tłumaczenia stanowi tutaj nie Rozporządzenie nr 1, ale regulamin wewnętrzny Komisji Europejskiej lub innej instytucji wspólnotowej.
Tłumaczenia dokonywane przez personel lingwistyczny Służby Tłumaczeń Pisemnych nie ograniczają się jednak tylko do dokumentów o charakterze legislacyjnym. Zakres tłumaczonych materiałów jest znacznie szerszy i obejmuje[ 39]:
przemówienia i notatki z przemówień,
komunikaty prasowe,
umowy międzynarodowe,
deklaracje polityczne,
odpowiedzi innych instytucji unijnych na pisemne lub ustne interpelacje posłów Parlamentu Europejskiego,
badania techniczne,
sprawozdania finansowe,
notatki z obrad,
wewnętrzne sprawy administracyjne i kadrowe,
materiały promocyjne (np. scenopisy i scenariusze filmowe),
korespondencję instytucji UE z ministerstwami, firmami, grupami nacisku oraz obywatelami,
wszelkiego rodzaju publikacje dotyczące opinii publicznej na temat spraw mających charakter publiczny.
Podstawowe kryteria obowiązujące w jego pracy zostały sprecyzowane w rezolucji Rady UE z 8 czerwca 1993 roku dotyczącej jakości tłumaczenia i redakcji tekstów prawnych Unii[ 40]. Stanowi ona m.in., że akt prawny powinien być sformułowany w sposób jasny, prosty, zwięzły i jednoznaczny, zrozumiały dla wszystkich adresatów i obywateli Unii. Należy unikać nadużywania skrótów, formułowania zbyt długich zdań oraz tzw. żargonu wspólnotowego. Te same pojęcia powinny być określane jednakowym terminem. Sprawa jakości prawnej i redakcyjnej tłumaczonych tekstów była również przedmiotem utrzymanej w podobnym duchu "Deklaracji dotyczącej jakości redakcyjnej prawodawstwa wspólnotowego" dołączonej do Aktu Końcowego Traktatu Amsterdamskiego. Na jej podstawie Rada UE, Komisja i Parlament zawarły międzyinstytucjonalne porozumienie, w którym określiły główne wytyczne mające na celu poprawę jakości redakcyjnej prawodawstwa wspólnotowego[ 41]. Przewidują one m.in. opracowanie przewodnika wspólnego dla tłumaczy wszystkich instytucji, wzmocnienie roli komórek redakcyjnych w Służbie Tłumaczeń i bardziej ścisłą współpracę pomiędzy różnymi jednostkami tych Służb. Opracowano specjalne wskazówki dla tłumaczy odnośnie dbałości o jakość, przejrzystość i styl tworzonych tekstów, czy zwalczanie zbyt zawiłych zdań o niskim stopniu nasycenia informacją, propagowane później w kampanii zwanej pod angielską nazwą jako "Fight the Fog"[ 42]. W swej codziennej pracy tłumacze kierują się sformułowaną nieco ironicznie, trudną do przetłumaczenia dewizą: KISS - "keep it short and simple"[ 43], w wolnym przekładzie: "tłumacz krótko i prosto".
Zapotrzebowanie na tłumaczenia rośnie równomiernie z zakresem działań Wspólnoty Europejskiej i przesuwaniem jej granic. Kolejne rozszerzenie w 2004 roku jeszcze bardziej wzmocni ten trend. Będzie to największe rozszerzenie w dotychczasowej historii Wspólnoty, bo jeszcze nigdy rozszerzenie nie wiązało się z tak znaczącym zwiększeniem liczby języków urzędowych. W obliczu bliskiego rozszerzenia podejmowane są działania, które mają na celu przygotowanie unijnych struktur odpowiedzialnych za przekład, tak aby zapewnienie tłumaczeń na nowe języki przebiegało sprawnie już od pierwszego dnia członkostwa nowych krajów w UE. Dlatego istnieje wyraźna potrzeba zwiększenia wydajności Służb Tłumaczeniowych, przy jednoczesnym monitorowaniu ilości i jakości wykonywanej pracy. Pod względem finansowym, w przypadku niewprowadzenia zmian organizacyjnych, dołączenie każdego nowego języka spowoduje wzrost kosztów o ok. 10%[ 44]. Taki drastyczny wzrost wydatków wydaje się trudny do przyjęcia i z tego też powodu trwają poszukiwania innych rozwiązań.
Wśród wielu proponowanych możliwości sprawą nadrzędną, dzięki której w dłuższym okresie możliwe będą oszczędności w czasie pracy i jej kosztach, staje się inwestycja w systemy komputerowe i oprogramowanie, czyli rozwój narzędzi technicznych usprawniających proces tłumaczenia. Jest to szczególnie ważne w obliczu faktu, iż większość z nowych języków oficjalnych jest rozumiana słabo lub nierozumiana wcale szczególnie w krajach należących obecnie do Wspólnoty, a prawie wszystkie z nowych języków oficjalnych różnią się znacząco od dotychczasowych języków obowiązujących w Unii. Trwają prace nad rozwijaniem podstawowych technicznych narzędzi (programów i systemów) wspomagających, takich jak: systemy tłumaczenia maszynowego, bazy danych terminologicznych, glosariusze, systemy archiwizacyjne, banki pamięci tłumaczeniowych i elektronicznych archiwów tekstów.
Budowa rozbudowanych i wiarygodnych baz terminologicznych możliwa jest tylko przy ścisłej współpracy od najwcześniejszego stopnia z odpowiednimi jednostkami zajmującymi się tłumaczeniami w każdym z nowych państw-członków.W ubiegłych latach Komisja udostępniła komórkom tłumaczeniowym krajów kandydujących program do zarządzania terminologią (MultiTerm), program wspomagający tłumaczenie (Translator's Workbench), a także system archiwizacyjny w postaci bazy tekstów tłumaczeń prawa wspólnotowego (CCVista).
Zasadnicze znaczenie dla dalszego korzystania z tych narzędzi miał fakt przekazania obowiązujących wzorów formatu gromadzonych danych terminologicznych i "pustej" bazy pamięci tłumaczeniowych. W założeniu zgodność szablonów używanych w krajach kandydujących i w Komisji ma na celu umożliwienie bezproblemowego importu danych do narzędzi i baz istniejących w Komisji.
Jednym z kolejnych kroków, które należy podjąć jest dostosowanie sprzętu komputerowego, przykładowo klawiatura komputera będzie musiała obsłużyć charakterystyczny dla języków słowiańskich alfabet czy też charakterystyczne dla niektórych języków akcentowanie liter. Ale na obecnym etapie rozwoju technologii te problemy wydają się drugorzędne w porównaniu z wyzwaniem roku 1981, kiedy razem z językiem greckim wprowadzano grecki alfabet i to w sytuacji, gdy systemy komputerowe nie były tak rozbudowane jak są w obecnie.
Stopniowo na szeroką skalę wdrażane są technologie rozpoznawania i zastępowania tekstu, które pozwolą oszczędzić czas tłumacza pozwalając mu na znalezienie i zastąpienie wyrażeń, zdań, czy nawet całych paragrafów, które były już tłumaczone kiedykolwiek wcześniej. Testuje się także systemy rozpoznawania mowy, tak aby bez konieczności wpisywania ręcznego, dany tekst mógł zostać podyktowany przez tłumacza i w ten sposób zostać wprowadzony do komputera.
Tak znaczący wzrost liczby języków oficjalnych nie musi oznaczać równie znacznego wzrostu zatrudnienia w strukturach tłumaczeniowych, szacuje się, że każdy nowy język wymaga zatrudnienia 110 tłumaczy pisemnych i dodatkowego personelu pomocniczego.
Szukanie rozwiązań technicznych w środowisku komputerowym jest niezwykle ważne, po to żeby osiągnąć równowagę pomiędzy gwałtownym wzrostem liczby par językowych, a ograniczoną możliwością przyjęcia tłumaczy nowych języków, sam proporcjonalny wzrost liczby zatrudnionych osób nie jest dobrym rozwiązaniem. Jednak bez wątpienia poza odpowiednią organizacją pracy, przy maksymalnym wykorzystaniu dostępnych narzędzi wspomagających pracę tłumacza, zmaganie się z powiększoną językowo Unią ma ułatwić także grupa doskonale przygotowanych tłumaczy. W niektórych z nowych krajów członkowskich, znalezienie odpowiedniej liczby dobrze przygotowanej kadry, czyli przede wszystkim osób o doskonałej znajomości języka ojczystego oraz jednego z oficjalnych krajów członkowskich (ze wskazaniem na język angielski i francuski, ponieważ z tych języków najczęściej dokonuje się przekładu) może okazać się zadaniem trudnym - łatwiej przeprowadzić rekrutację w kraju, np. takim jak Polska, o większych możliwościach wykształcenia i przygotowania odpowiedniej liczby tłumaczy.
Wracając do zmian w obrębie SdT, zupełnie nowym elementem, o zastosowaniu którego już zadecydowano, jest wprowadzenie zasady tłumaczenia "w obie strony" wraz z powiększeniem się grupy języków w wyniku rozszerzenia. Dotychczas tłumacze w Komisji dokonywali przekładu wyłącznie na swoje języki ojczyste. Tłumaczenie "w obie strony", czyli zarówno na język ojczysty, jaki i z języka ojczystego, pozwoli do pewnego stopnia ograniczyć zatrudnienie nowych tłumaczy w każdej z sekcji językowych. Tłumaczenie tego typu nie będzie nowością dla profesjonalnie przygotowanych tłumaczy z większości krajów Europy Środkowej i Wschodniej, gdzie nauka przekładu w obie strony znajduje się w programie każdych studiów z zakresu tłumaczenia. Natomiast będzie to nowością dla tłumaczy obecnie zatrudnionych w strukturach tłumaczeniowych instytucji unijnych. Od 1996 roku 150 tłumaczy Komisji Europejskiej intensywnie uczy się języków przyszłych państw członkowskich, tak aby móc zapewnić tłumaczenie z tych języków. Tłumacze mają także możliwość wyjazdów na intensywne kursy w krajach przyszłych członków Wspólnoty.
Rozwiązaniem, które miałoby zmniejszyć wydatki związane z utrzymaniem wielojęzyczności, jest zmniejszenie liczby tłumaczeń dokonywanych przez tłumaczy etatowych SdT na rzecz rynku zewnętrznego. Wynika to przede wszystkim z faktu, że całkowity koszt jednej strony tłumaczenia w SdT mniej więcej dwa razy przewyższa koszt tłumaczenia zleconego na zewnątrz[ 45]. Można przypuszczać, że w konsekwencji wykonywania większej niż dotychczas liczby tłumaczeń przez tłumaczy zewnętrznych, konieczne będzie zwiększenie nakładu pracy związanej z kontrolą jakości otrzymywanych tłumaczeń. Nie będzie już także wyboru współpracowników w wyniku przetargu, ale z wybranymi tłumaczami lub agencjami nawiązana zostanie ścisła, długoterminowa współpraca, ze zwiększonym wsparciem i nadzorem ze strony Służb.
Istotnym warunkiem dokonania dobrego przekładu jest odpowiednio napisany oryginalny tekst. Jasne i zwięzłe dokumenty powinny być wyróżnikiem organizacji wielojęzycznych, w których większość pracujących obraca się w środowisku innego języka niż swój własny. Aby to urzeczywistnić Służby powołały do życia serwis wydawniczy, którego zadaniem jest korekta i redakcja języka oryginalnego dokumentu. Służby Tłumaczeniowe zorganizowały także kilka kampanii, które miały na celu promocję przejrzystego i zwięzłego stylu pisania w Komisji, m.in. "Fight the Fog" i "KISS", o czym wspomniałam już wcześniej.
Należy także zweryfikować typy dokumentów, które będą podlegać tłumaczeniu na wszystkie języki oficjalne. Oszczędność kosztów i siły roboczej może być osiągnięta między innymi przez klasyfikowanie dokumentów według ich rodzaju, szczególnie separowanie dokumentów, które wystarczy streścić zamiast tłumaczyć całą ich treść.
Problemy z nietypowymi parami językowymi (np. estońsko-grecką) mogą być rozwiązywane poprzez języki pośrednie (np. przez bardziej popularny język angielski lub francuski). Posunięcie to niesie ze sobą pewne ryzyko zniekształcenia pierwotnego znaczenia oryginalnego tekstu, ale warto podjąć to ryzyko w sytuacji gdy istnieje zagrożenie, że z powodu braku tłumacza takiej pary językowej dokument mógłby nie zostać przetłumaczony wcale.
Kolejną próbą obejmującą zmianę metod pracy jest projekt telepracy, który wprowadzony jako projekt pilotażowy w 2002 roku. Planowo miał objąć 10% pracowników. Przydatność tego trybu pracy w dziedzinie tłumaczenia jako źródło zmniejszenia kosztów stałych zostanie sprawdzona po wdrożeniu wspomnianego projektu[ 46].
[ 1] Por. Traktat o Wspólnocie Europejskiej (Traktat Rzymski) z 25 marca 1957 r., Art. 155; http://www2.ukie.gov.pl/dokumenty/I.zip (24.05.03).
[ 2] Traktat o Unii Europejskiej z 7 lutego 1992 r., Art. 1; http://www2.ukie.gov.pl/dokumenty/XVI.zip (24.05.03).
[ 3] Traktat o utworzeniu Europejskiej Wspólnoty Gospodarczej oraz Europejskiej Wspólnoty Energii Atomowej podpisany został 25 marca 1957 roku w Rzymie przez sześć państw Europejskiej Wspólnoty Węgla i Stali. Traktat o EWG wszedł w życie 1 stycznia 1958 roku, po ratyfikacji przez parlamenty państw-sygnatariuszy.
[ 4] Traktat o Wspólnocie Europejskiej (Traktat Rzymski) z 25 marca 1957 r., Art. 290, http://www2.ukie.gov.pl/dokumenty/I.zip (24.05.03).
[ 5] Inciarte M. M., Translating for a multilingual community, SdT, Bruksela 2002; str. 19.
[ 6] Stało się to na mocy Traktatu z Maastricht, nazywanego także Traktatem o Unii Europejskiej, który ustanowił Unię Europejską opartą na Wspólnotach Europejskich. Został podpisany w Maastricht 7 lutego 1992 roku, wszedł w życie 1 listopada 1993 roku.
[ 7] Traktat o Unii Europejskiej z 7 lutego 1992 r., Art. 6; http://www2.ukie.gov.pl/dokumenty/XVI.zip (24.05.03).
[ 8] Traktat Amsterdamski został podpisany 2 października 1997 roku. Wprowadził i znowelizował przepisy prawa Wspólnoty w wielu kwestiach.
[ 9] Traktat Amsterdamski z 2 października 1997, Art. 21; http://www2.ukie.gov.pl/dokumenty/XVII.zip (24.05.03).
[ 10] Karta Praw Podstawowych to przepisy przyjęte w czasie posiedzeń Konwentu w Brukseli w dniach 5 i 16 maja 2000 roku. Karta w 54 artykułach określa prawa (społeczne, polityczne, ekonomiczne) przysługujące wszystkim obywatelom państw Unii.
[ 11] Słownik współczesnego języka polskiego, Wydawnictwo Przegląd Reader's Digest, Warszawa 1998; tom 2., str. 516.
[ 12] W NATO obowiązują 2 języki oficjalne, a w ONZ, który liczy 189 krajów jest 6 języków oficjalnych.
[ 13] Rzewuska M., Tłumaczenie acquis communautaire, Biuletyn Analiz UKIE nr 6, Urząd Komitetu Integracji Europejskiej, Warszawa 2001; str. 69.
[ 14] Por. Pieńkos J., Podstawy juryslingwistyki, Oficyna Prawnicza Muza, Warszawa 1999; str. 193.
[ 15] W maju 2004 roku do Unii przystąpi 10 państw, ale liczba języków oficjalnych powiększy się o 9.
[ 16] Por. Andersen P., Translation Tools for the CEEC Candidates for EU Membership - an Overview, SdT, Luksemburg 1998; str. 2.
[ 17] Wszystkie dane liczbowe: Ilustrowany Atlas Świata, Przegląd Reader's Digest, Warszawa 1999; str. 208-211.
[ 18] Wszystkie dane liczbowe: Ilustrowany Atlas Świata, Przegląd Reader's Digest, Warszawa 1999; str. 212-214.
[ 19] Jednolity Akt Europejski - nowelizacja Traktatu Rzymskiego, uchwalona podczas konferencji rządowej w Luksemburgu i w Brukseli (9 IX 1985 - 27 I 1986) o zmianie i uzupełnieniu trzech Traktatów założycielskich: EWWIS (1951), EWG (1957) i Euratomu (1957). Układ wszedł w życie 1 lipca 1987 roku.
[ 20] W zależności od opracowania można spotykać podział na sześć lub siedem departamentów tematycznych, w przypadku sześciu Dyrekcje A i B traktuje się jako jedną - AB.
[ 21] Inciarte M. M., Translating for a multilingual community, SdT, Bruksela 2002; str. 21.
[ 22] Proporcje tłumaczonych tekstów z odpowiednich języków: angielski 56,8%, francuski 29,8%, niemiecki 4,3%, źródło: Inciarte M. M., Translating for a multilingual community, SdT, Bruksela 2002; str. 8.
[ 23] Wówczas nadal mielibyśmy do czynienia z 6 departamentami tematycznymi, tyle że w każdym z nich byłoby po 20 sekcji językowych (przy założeniu włączenia 9 nowych języków), co razem daje 120 sekcji językowych.
[ 24] Rzewuska M., Przygotowania służb tłumaczeniowych instytucji UE do rozszerzenia, Biuletyn Analiz UKIE nr 8, Urząd Komitetu Integracji Europejskiej, Warszawa 2002; str. 192.
[ 25] Por. Michałowska-Gorywoda K., Służby lingwistyczne Unii Europejskiej, Kwartalnik Studia Europejskie nr 03/2001, Centrum Europejskie Uniwersytetu Warszawskiego, Warszawa 2001; str. 85.
[26] Tamże, str. 83.
[ 27] Rzewuska M., Przygotowania służb tłumaczeniowych instytucji UE do rozszerzenia, Biuletyn Analiz UKIE nr 8, Urząd Komitetu Integracji Europejskiej, Warszawa 2002; str. 196.
[ 28] Cunningham K., Translating for a larger Union - can we cope with more than 11 languages?, SdT, Bruksela 2001; str. 5.
[ 29] Inciarte M. M., Translating for a multilingual community, SdT, Bruksela 2002; str. 5.
[ 30] Rzewuska M., Przygotowania służb tłumaczeniowych instytucji UE do rozszerzenia, Biuletyn Analiz UKIE nr 8, Urząd Komitetu Integracji Europejskiej, Warszawa 2002; str. 196.
[31] Tamże, str. 196.
[ 32] Multilingualism in the European Commission: A long-standing tradition and an asset to the European Union, (Memorandum) MEMO/03/37, Bruksela 2003; str. 2.
[ 33] Inciarte M. M., Translating for a multilingual community, SdT, Bruksela 2002; str. 8.
[ 34] Rzewuska M., Przygotowania służb tłumaczeniowych instytucji UE do rozszerzenia, Biuletyn Analiz UKIE nr 8, Urząd Komitetu Integracji Europejskiej, Warszawa 2002; str. 195.
[35] Tamże, str. 191.
[ 36] Michałowska-Gorywoda K., Służby lingwistyczne Unii Europejskiej, Kwartalnik Studia Europejskie nr 03/2001, Centrum Europejskie Uniwersytetu Warszawskiego, Warszawa 2001; str. 11.
[ 37] Inciarte M. M., Translating for a multilingual community, SdT, Bruksela 2002; str. 8.
[ 38] Rzewuska M., Przygotowania służb tłumaczeniowych instytucji UE do rozszerzenia, Biuletyn Analiz UKIE nr 8, Urząd Komitetu Integracji Europejskiej, Warszawa 2002; str. 190.
[ 39] Por. Michałowska-Gorywoda K., Służby lingwistyczne Unii Europejskiej, Kwartalnik Studia Europejskie nr 03/2001, Centrum Europejskie Uniwersytetu Warszawskiego, Warszawa 2001; str. 88.
[ 40] Por. Dziennik Urzędowy Wspólnot Europejskich, C 166/1993.
[ 41] Por. Dziennik Urzędowy Wspólnot Europejskich, C 73/01/1999.
[ 42] Por. Cunningham K., Translating for a larger Union - can we cope with more than 11 languages?, SdT, Bruksela 2001; str. 11.
[43] Por. Tamże, str. 11.
[ 44] O mniej więcej 10% wzrosły koszty po przystąpieniu Finlandii i Szwecji dla tych języków, ale ich wprowadzenie nie wymagało większych zmian w strukturze SdT.
[ 45] Rzewuska M., Przygotowania służb tłumaczeniowych instytucji UE do rozszerzenia, Biuletyn Analiz UKIE nr 8, Urząd Komitetu Integracji Europejskiej, Warszawa 2002; str. 190.
[ 46] Por. Rzewuska M., Przygotowania służb tłumaczeniowych instytucji UE do rozszerzenia, Biuletyn Analiz UKIE nr 8, Urząd Komitetu Integracji Europejskiej, Warszawa 2002; str. 191.
Spis treści
Służby Tłumaczeniowe Komisji Europejskiej zostały wyposażone w szereg narzędzi wspomagających ich pracę, tak aby jak najlepiej wypełnić zadania do jakich zostały powołane. Obecnie proces tłumaczenia nie sprowadza się tylko do znalezienia odpowiednich słów, ale także użycia odpowiedniej technologii, która gra coraz większą rolę w codziennej pracy tłumacza. Niezależnie od przyjętej metody pracy podstawowe potrzeby tłumacza pracującego w Komisji możemy sklasyfikować następująco[ 47]:
Konieczność doboru odpowiedniej terminologii, co ułatwiają rozbudowane słowniki, glosariusze, terminologiczne bazy danych, wielojęzyczne biblioteki, itp. dostępne na serwerach Komisji Europejskiej, poprzez Internet lub na przenośnych nośnikach danych.
Możliwość dostępu do innych tekstów związanych z danym dokumentem, co umożliwiają archiwa dokumentów - w wersji elektronicznej i tradycyjne.
Możliwość odnalezienia i edycji dokumentów tłumaczonych w Służbach kiedykolwiek wcześniej, możliwość przeszukiwania tekstu tych dokumentów, przenoszenie fragmentów zdań lub paragrafów z innych aplikacji czy zastępowanie fragmentów tekstu i ich przetwarzanie, co umożliwiają elektroniczne archiwa danych i pamięci tłumaczeniowe.
Wsparcie personelu pomocniczego - tzw. asystentów językowych. Tłumacz i asystent językowy ściśle współpracują ze sobą. Asystent językowy odpowiedzialny jest za przetwarzanie wstępne i końcowe dokumentu, a dzięki takiemu podziałowi obowiązków tłumacze mogą skoncentrować się na istocie swojej pracy.
Jak stosowanie narzędzi wspomagających wpłynęło na pracę tłumacza i efekt jego pracy? Przede wszystkim poprawiła się jakość tłumaczonych dokumentów dzięki większej spójności terminologicznej i frazeologicznej. Szybkość i łatwość znalezienia odpowiedniego terminu, zdania, fragmentu tekstu, czy całego dokumentu skróciło czas pracy z tekstem. Dzięki pamięciom tłumaczeniowym zminimalizowano ryzyko tłumaczenia tekstu, który był już przekładany, a szacuje się, że w Komisji Europejskiej 25% nowopowstających tekstów powtarza się, czyli powstaje na bazie już istniejących[ 48]. Trudno dokładnie oszacować wzrost wydajności tłumaczenia, ponieważ niektóre narzędzia wciąż są w fazie rozwoju, ale ocenia się, że jest to około 60%[ 49], czyli dzięki narzędziom wspomagającym przetłumaczenie 16 stron jest możliwe w czasie, w którym tradycyjnie tłumaczyłoby się tylko 10. Fakt dostępności wszystkich wersji wcześniejszych tłumaczeń bez wątpienia daje tłumaczowi dodatkową pewność i komfort psychiczny, co z kolei także przyczynia się do zwiększenia wydajności pracy. Ważnym zagadnieniem jest także ergonomia pracy. Wprowadzenie nowych technologii spowodowało to, że cała praca wykonywana jest przy pomocy komputera, dlatego istotne stało się zapewnienie odpowiednich warunków pracy dla osób, które spędzają kilka godzin dziennie intensywnie pracując z komputerem, czyli odpowiednio przygotowanego, przestronnego stanowiska pracy lub monitorów o dużej przekątnej, czego wymaga praca z wieloma oknami poszczególnych aplikacji. Natomiast jest jeszcze zbyt wcześnie, aby w dłuższym okresie analizować efekty izolacji, w jakiej pracują tłumacze, w tej chwili możliwe jest wykonanie całej pracy tłumaczeniowej bez opuszczania stanowiska komputerowego, osobistych konsultacji z innymi tłumaczami czy wizyt w centrach archiwizacyjnych. Kolejną zmianą jest wprowadzenie do procesu tłumaczenia asystentów językowych, którzy przejęli przygotowanie wstępne i końcowe tłumaczonego dokumentu. Wprowadzanie nowych technologii zmusza tłumaczy do ciągłego poszerzania swojej wiedzy i umiejętności wykorzystania nowych narzędzi w swojej pracy, m.in. w zakresie zdolności obsługi nowych programów komputerowych, nowych formatów zapisywania dokumentów itp.
Przed okresem rozwoju technologii ułatwiających pracę tłumacza proces tłumaczenia przedstawiał się prosto: dokument, który miał zostać przetłumaczony był dostarczany do Służb Tłumaczeniowych, a następnie przekazywany tłumaczowi, który zmuszony był samodzielnie przeprowadzić cały proces tłumaczenia, czyli poza samym tłumaczeniem także wstępnie przygotować dokument, zgromadzić odpowiednią dokumentację, dokonać przekładu oraz weryfikacji tłumaczenia i ostatecznej korekty[ 50].
Obecnie jakość i opłacalność tłumaczenia jest wynikiem decyzji wyboru odpowiedniego "złotego" środka między wkładem pracy człowieka, a zastosowaniem odpowiedniej technologii.
To kontinuum dostępnych dla tłumacza narzędzi przedstawia poniższy rysunek:

Nowe technologie wymusiły zmiany w procesie tłumaczenia. Dzięki zestawowi narzędzi wdrożonych w Komisji Europejskiej i jej Służbach Tłumaczeniowych możliwe jest niezwykle efektywne zarządzanie procesem tłumaczenia na każdym etapie i śledzenie przepływu dokumentów od momentu zgłoszenia zapotrzebowania na tłumaczenie do uzyskania końcowego wyniku tłumaczenia. Proces tłumaczenia dzieli się na kilka stałych etapów, a jego inicjatorem jest Komisja Europejska. Komisja może skierować do Służb Tłumaczeniowych polecenie tłumaczenia dokumentów, które sama tworzy, ale także materiałów napływających do niej z innych źródeł (np. artykułów prasowych, czy korespondencji instytucji Unii z firmami z zewnątrz). Poszczególne jednostki Komisji Europejskiej decydują o tym, które dokumenty mają zostać przetłumaczone, na jaki język lub języki docelowe i na jakim etapie powstawania dany dokumentu musi zostać przetłumaczony. Jednocześnie ocenia się, jakiego rodzaju tłumaczenia wymaga ten dokument. Jeśli wystarczy sam szkic do dyskusji i oddanie ogólnego sensu, Komisja kieruje zapytanie pocztą elektroniczną bezpośrednio do tłumaczenia maszynowego wykonywanego przez EC SYSTRAN[ 52], o ile język źródłowy i docelowy dokumentu należy do grupy par językowych obsługiwanych przez EC Systran. W przypadku nietypowej pary językowej lub jeżeli dokument wymaga dalszej obróbki po tłumaczeniu maszynowym, czy też jeśli dokument wymaga przekładu wysokiej jakości dana jednostka Komisji, korzystając z programu administrującego POETRY[ 53], przygotowuje zamówienie na tłumaczenie. Zamówienie wraz z załączonym dokumentem i ewentualnie dodatkowymi załącznikami do niego (wszystko w wersji elektronicznej), przekazywane jest do działu planowania Służb Tłumaczeniowych. Po akceptacji zadania w dziale planowania zamówienie jest rejestrowane w WinSuivi[ 54], a dokument źródłowy i ewentualne załączniki do zlecenia umieszczane są na serwerze archiwizującym (SdTVista[ 55]). Zlecenie kierowane jest do odpowiedniej sekcji tematycznej i sekcji językowej SdT. Na tym etapie wykonywana jest pewna część prac przygotowawczych - odbywa się wstępne przetwarzanie dokumentu, np. wyszukiwanie potrzebnej terminologii czy innych dokumentów odnoszących się do danego, sprawdza się możliwość przekazania dokumentu do aplikacji Translator's Workbench[56], a korzystając z DossierManagement[ 57] przygotowuje się dossier tego zlecenia. Na tym etapie dużą rolę odgrywają asystenci językowi, którzy wykonując prace wstępne oszczędzają rzeczywisty czas pracy tłumacza z dokumentem. Następnie kierujący jednostką tematyczną przydziela zlecenie na poziomie danej jednostki i jeden z tłumaczy w danej sekcji rozpoczyna pracę nad dokumentem. Postępy w tłumaczeniu rejestrowane są w WinSuivi. Jeśli kierujący sekcją zadecyduje o zleceniu tłumaczenia danego materiału tłumaczom zewnętrznym, tłumaczenie to rejestrowane jest w systemie TREFLE. Tłumacze pracują z danym tekstem wykorzystując szereg narzędzi ułatwiających i wspomagających proces tłumaczenia, m.in. Translator's Workbench, Eurodicautom, MultiTerm, Celex, Euramis, dodatkowe słowniki na nośnikach przenośnych, a także programy takie jak Microsoft Word i Excel. Większość dokumentów jest tłumaczona i weryfikowana w tej samej sekcji, ale korektą i weryfikacją zajmuje się drugi tłumacz. Gotowy, przetłumaczony dokument jest archiwizowany (SdTVista), wylogowywany z WinSuivi i przesyłany z powrotem do zamawiającego drogą elektroniczną. Tłumaczenie przychodzące z zewnątrz jest wylogowywane z systemu TREFLE. Nowe dane językowe (np. nowe terminy) mogą zostać przekazane do centralnej pamięci systemu Euramis. Jeśli jednostka, która zleciła tłumaczenie wprowadzi jakiekolwiek zmiany do gotowego już dokumentu, który otrzymała, wymaga się aby poprzez Poetry przesłać kopię ostatecznej wersji dokumentu do Służb Tłumaczeniowych, tak aby wersja ta mogła zostać wprowadzona do archiwum SdTVista i systemu Euramis.
Obecnie to wciąż przede wszystkim od tłumacza zależy dobór narzędzi wspomagających jego pracę. Po otrzymaniu dokumentu to on decyduje o kolejności podejmowanych czynności i doborze środków do realizacji zadania.
Nowy scenariusz, który zacznie obowiązywać w niedalekiej przyszłości, przewiduje, że dany dokument trafi do tłumacza w możliwie już idealnie przygotowanej do przetłumaczenia formie[ 58]. Schemat analizy, jakiej poddany będzie dokument trafiający do SdT, przedstawia poniższy rysunek:
Rysunek 2.2. Idealny dla przyszłości scenariusz przepływu dokumentu między poszczególnymi aplikacjami[ 59].

W pierwszym etapie zamówienie na tłumaczenie zostaje przekazane drogą elektroniczną do działu planowania odpowiedniej jednostki tematycznej Służb Tłumaczeniowych poprzez aplikację Poetry, która z kolei przekaże dokument do bazy Euramis. Tam system doradczy (tzw. expert system) rozpozna dokument i określi sposób jego najbardziej efektywnej obróbki przez dostępne narzędzia. Na tej podstawie tworzone jest archiwum zip, zawierające plik z dokumentem w wersji wyjściowej razem z propozycjami optymalnego przekładu poszczególnych zdań i projektem obróbki przez dostępne narzędzia oraz wszystkimi załącznikami wyłonionymi podczas przeprowadzania analizy. Tłumacz ma dostęp do zlecenia oraz archiwum zip poprzez DossierManagement. Jeśli nie jest on usatysfakcjonowany otrzymanymi rezultatami, ma możliwość przeprowadzenia dodatkowej analizy odpowiadającej jego potrzebom i według swoich własnych kryteriów.
Prawie każda z technologii wdrożonych w Służbach Tłumaczeniowych wymaga od użytkownika posiadania dokumentu w wersji elektronicznej, a najprostszą drogą przesyłania dokumentu jest poczta elektroniczna. Zapis dokumentu w wersji elektronicznej usprawnia proces przekazywania go pomiędzy poszczególnymi departamentami, ponieważ jest to metoda szybka, tania i minimalizująca ryzyko wprowadzenia błędu do tekstu. Aby usprawnić proces transmisji zgłaszanych zleceń tłumaczenia między różnymi departamentami Komisji Europejskiej a Służbami Tłumaczeniowymi, wprowadzono program administrujący POETRY[ 60]. Aplikacja ta charakteryzuje się łatwością obsługi i prostym interfejsem użytkownika. POETRY umożliwia przygotowanie i przesłanie zlecenia wraz z załączonym dokumentem, który ma zostać przetłumaczony, a także dołączenie innych materiałów odnoszących się do przesyłanego dokumentu.
Widok tej aplikacji przedstawia się następująco:
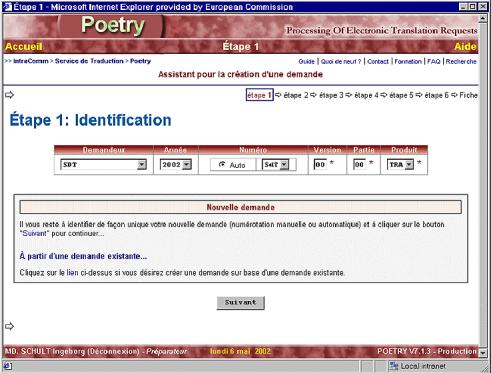
Dla każdego nowego zlecenia tworzony jest elektroniczny folder zawierający oryginalny dokument, a także wszystkie inne potrzebne lub wymagane materiały. Dzięki temu dokument i wszystkie odnośniki przesyłane są razem do Służb Tłumaczeniowych.
Do korzyści z użytkowania aplikacji POETRY możemy zaliczyć: szybszą i efektywniejszą transmisję danych, integrację z elektronicznymi systemami archiwizacyjnym, bezpośredni dostęp do oryginalnego dokumentu i wszystkich odnośników do tego dokumentu w wersji elektronicznej.
W dalszej kolejności zlecenie tłumaczenia przekazywane jest do odpowiedniej jednostki tematycznej, sekcji językowej i tłumacza zajmującego się danym językiem, na który tłumaczenie zostało zlecone. Odbywa się to poprzez aplikację zarządzającą WinSuivi, która przydziela zlecenia do poszczególnych zespołów językowych.
WinSuivi jest oprogramowaniem używanym do elektronicznego zarządzania zamówieniami na tłumaczenie. Jest to program trzypoziomowy, który monitoruje postęp przekazywania dokumentu między poszczególnymi szczeblami i kieruje gotowy, przetłumaczony dokument z powrotem do zamawiającego.
WinSuivi umożliwia śledzenie i zarządzanie przepływem wszystkich zamówień na tłumaczenie, a także umożliwia generowanie informacji statystycznych. Obejmuje wszystkie zlecenia tłumaczeń i aktualny stan pracy nad nimi. Zawiera szczegółowe dane dotyczące każdego zamówienia, takie jak nazwa jednostki, z której wyszło zamówienie, data, numer zlecenia, język źródłowy dokumentu i docelowy tłumaczenia, tytuł dokumentu źródłowego i jego autora itp.
Rys. 5 przedstawia drogę przepływu zleceń pomiędzy poszczególnymi komórkami - od złożenia zamówienia do odesłania tłumaczenia do nadawcy.
Rysunek 2.4. Przepływ zamówień na tłumaczenie pomiędzy poszczególnymi komórkami nadzorowany przez aplikację WinSuivi [ 62].

Każde zlecenie tłumaczenia posiada swój własny numer identyfikacyjny nadany przez aplikację POETRY. Po wprowadzeniu danego numeru do programu DossierManagement, tłumacz pracujący nad zleceniem uzyskuje dostęp do oryginalnego dokumentu i wszystkich plików pomocniczych i niezbędnych do przetłumaczenia tego dokumentu, są to m.in. odnośniki do innych dokumentów związanych z tłumaczonym, dokumenty wstępnie przetworzone, porównawcze, inne dokumenty będące w trakcie tłumaczenia, czy dokumenty już przetłumaczone.
DossierManagement umożliwia także utworzenie "szkieletu" tłumaczenia oraz stworzenie kanału komunikacyjnego między tłumaczami pracującymi nad tym samym zadaniem, dzięki czemu tłumacze nie dublują swojej pracy. Okno tej aplikacji wygląda następująco:
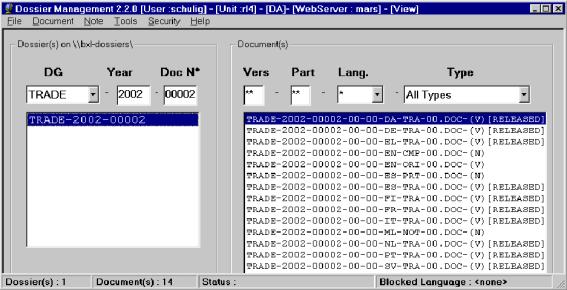
SdTVista jest elektronicznym systemem archiwizującym Służb Tłumaczeniowych. Zawiera prawie wszystkie dokumenty (pełne teksty w wersji oryginalnej) przychodzące jako zamówienia z poszczególnych jednostek (komórek) Komisji Europejskiej od 1994 roku,jak również gotowe, przetłumaczone dokumenty, które odsyłane są do zamawiającego. Baza nie obejmuje dokumentów poufnych, natomiast zawiera dodatkowo szereg dokumentów źródłowych i odnośników, co pozwala użytkownikowi sprawdzić, czy dany dokument lub jego część nie została już kiedyś przetłumaczona, a także wyszukać odpowiednie dokumenty źródłowe, jak i ich tłumaczenia.
Interfejs klient-serwer oferuje użytkownikowi liczne kryteria (filtry) wyszukiwania według numeru dokumentu, nazwiska autora, zamawiającego, roku powstania, tytułu dokumentu, czy zawartości jego tekstu, przez co istnieje możliwość odnalezienia faktycznie każdego dokumentu w ciągu kilku sekund. Wyszukiwanie jest możliwe dzięki temu, że każdy dokument zarchiwizowany w systemie SdTVista posiada tzw. "notice", co jest rodzajem karty identyfikującej, która zawiera wszystkie kluczowe dla danego dokumentu informacje takie jak jego tytuł, szczegóły tłumaczenia (kto zamawiał, data, numer, wersja, język źródłowy i docelowy), a także dane o jego autorze, tłumaczu, nagłówek, zawartość, co umożliwia dokładne przeszukanie go.
Pomimo tego, że SdTVista została zaprojektowana jako elektroniczny system archiwizujący, jej szczególne cechy takie jak krótki czas odpowiedzi, równoległe przesuwanie dokumentu w obu wersjach językowych (w języku źródłowym i docelowym), możliwość podejrzenia wybranego dokumentu lub otwarcia go bezpośrednio w edytorze tekstu tłumacza, czy możliwość przeszukiwania całego tekstu dokumentu - dzięki czemu możliwa jest także konsultacja terminologiczna, uczyniło z niej program wspomagający tłumaczenie.
Celex[ 64] jest obszerną składnicą ustawodawstwa Unii Europejskiej. Baza CELEX zaczęła być tworzona we wczesnych latach siedemdziesiątych dla wewnętrznych celów archiwizacyjnych Komisji Europejskiej. Stopniowo przekształcała się w międzyinstytucjonalne źródło informacji, a także narzędzie wspomagające pracę tłumacza. Dostępne w bazie dokumenty podzielone są na 4 grupy[ 65]:
Ustawodawstwo, a wśród nich traktaty (m.in. założycielskie, o rozszerzeniu, poprawki np. Jednolity Akt Europejski), dyrektywy, rozporządzenia, umowy międzynarodowe zawierane w wyniku praw i zobowiązań Wspólnoty na arenie międzynarodowej, ustawodawstwo wtórne (opinie, zalecenia, rezolucje) oraz prawo uzupełniające (legislacja wynikająca z umów zawieranych między krajami członkowskimi).
Prawo zwyczajowe, czyli decyzje, wyroki, orzeczenia wydane przez Trybunał Sprawiedliwości Wspólnot Europejskich.
Dokumenty przygotowawcze, czyli dokumenty powstające w różnych stadiach procesów legislacyjnych, rezolucje Parlamentu Europejskiego, projekty traktatów, dyrektyw, rozporządzeń publikowane w Oficjalnym Dzienniku Urzędowym Wspólnot Europejskich[ 66] serii C.
Pytania parlamentarne (interpelacje) stawiane przez członków Parlamentu w formie ustnej lub pisemnej w Oficjalnym Dzienniku Urzędowym wraz z odpowiedziami.
W bazie zgromadzonych jest około 220 000 dokumentów we wszystkich 11 językach oficjalnych Unii. Baza aktualizowana jest raz w tygodniu. Dokumenty zarchiwizowane są w formacie HTML. Pełne teksty niektórych dokumentów są także dostępne w formatach PDF i/lub TIFF. Służby Tłumaczeniowe mają stały bezpośredni dostęp do bazy Celex poprzez sieć internet[ 67] lub pośrednio poprzez system Euramis.
Zawartość bazy Celex nie ogranicza się tylko do samych aktów prawnych, obejmuje także dokumenty zawierające dodatkowe informacje, które mogą okazać się istotne dla zrozumienia prawodawstwa Unii Europejskiej. Baza Celex może być także wykorzystana do znalezienia wszystkich dokumentów, które cytują pewien akt prawny, ponieważ zapewnia wiele kryteriów wyszukiwania.
W bazie CELEX wszystkie dokumenty opatrzone są odpowiednim numerem. Numeracja ta jest wykorzystywana w innych bazach dokumentów europejskich, również w bazie EUR-Lex czy bazie tłumaczeń Urzędu Komitetu Integracji Europejskiej. Jej znajomość pozwala na szybkie wyszukiwanie odpowiedniego dokumentu. Numer Celex składa się z dziesięciu znaków[ 68]. Pierwszy znak oznacza rodzaj aktu prawnego (np. 1 dla traktatów, 3 dla aktów prawnie wiążących, 5 dla dokumentów przygotowawczych, 6 dla orzeczeń), po nim następuje oznaczenie roku wydania (dwie cyfry jeśli dokument powstał przed rokiem 2000 lub cztery cyfry jeśli po roku 2000), następnie litera przyporządkowana typowi aktu prawnego, np. L dla dyrektyw, R dla rozporządzeń, D dla decyzji, a dalej czterocyfrowy numer dokumentu przeważnie odpowiadający numerowi porządkowemu danego aktu lub numerowi artykułu traktatu. Przykładowo dyrektywa numer 378 z 1988 roku, dotycząca bezpieczeństwa zabawek[ 69] będzie oznaczona numerem Celex 31988L0378.
Baza Celex umożliwia wyszukiwanie dokumentów z użyciem wielu kryteriów, m.in. poszczególnych słów, tytułów, daty wydania dokumentu itp. Dostępne są dwa rodzaje wyszukiwania, pierwsze - główne, tzw. Menu searching to wyszukiwanie proste. Dokumenty pogrupowane są w czterech zbiorach: według tytułów, dat i terminologicznej zawartości tekstu, typów dokumentów, numerów (nadanych w procesie legislacji lub przydzielonych w bazie Celex) i miejsca publikacji. Menu searching pozwala na przeszukiwanie wybranej grupy dokumentów spośród czterech grup dostępnych według dalszych kryteriów. Rezultaty wyświetlane są w postaci listy. Następnie możliwe jest dalsze zawężone wyszukiwanie lub wyświetlenie znalezionego dokumentu (także w dwóch wersjach językowych obok siebie).
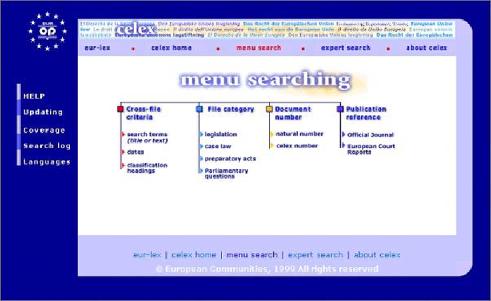
Drugi rodzaj wyszukiwania to tzw. Expert searching, typ wyszukiwania bardziej zaawansowanego, bezpośredniego, skutecznego i elastycznego, najczęściej wykorzystywany w Służbach Tłumaczeniowych. Cechy wyróżniające opcję Expert Searching to m.in. dostępność okien wyszukiwania, podglądu usystematyzowanych nagłówków dokumentów, możliwość formułowania zapytań, a także tworzenia i zapisywania profili wyszukiwania i wyświetlania wyników.
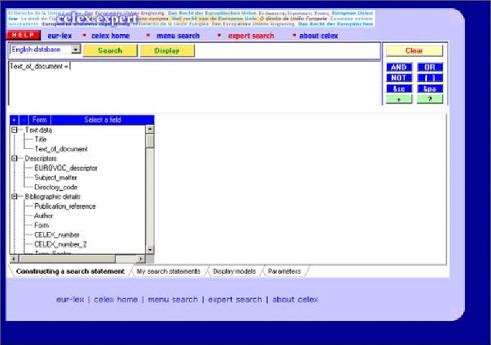
Przykładowe wyszukiwanie może odbyć się w następujący sposób: najpierw tłumacz zawęża pole wyszukiwania wybierając odpowiednią opcje wyszukiwania, zlecając przeszukanie bazy na przykład pod względem występowania w dokumentach problematyki z zakresu odpadów toksycznych i nuklearnych, wybiera opcję "tekst dokumentu =" ("Text_of_document ="). Następnie mając możliwość korzystania z operatorów logicznych w prawym górnym rogu okna aplikacji tłumacz wprowadza słowa kluczowe: "Text_of_document = (toxic OR nuclear) AND waste". Kiedy zapytanie zostało zdefiniowane tłumacz wybiera opcję "szukaj" i czeka na wyświetlenie liczby trafień przedstawionych w postaci listyrazem z linkami do wyszukanych dokumentów[ 72].
Warta wspomnienia są także inne bazy dostępne dla tłumaczy. Pierwszą z nich jest baza EUR-Lex. W bazie danych EUR-Lex dostępne są Dzienniki Urzędowe Wspólnot Europejskich serii C i L z ostatnich 45 dni, akty o charakterze prawnie wiążącym (dyrektywy, rozporządzenia, traktaty, decyzje) najnowsze orzeczenia Europejskiego Trybunału Sprawiedliwości oraz niektóre dokumenty o pozaprawnym charakterze. W porównaniu z bazą Celex baza EUR-Lex ma gorsze instrumenty wyszukiwania oraz uboższą zawartość. W bazie tej dokumenty zapisane są głównie w formacie HTML, bez tabel, wykresów, wzorów matematycznych i rysunków. Można skorzystać z kilku metod wyszukiwania: z użyciem numeru dokumentu, numeru Dziennika Urzędowego oraz słowa występującego w tytule.
Kolejną bazą dokumentów, znajdującą się na serwerze Komisji Europejskiej jest PreLex. Jest to baza zawierająca wszystkie projekty aktów, przygotowywane przez Komisję Europejską (aktów prawnych, umów zawieranych przez Wspólnotę oraz komunikatów) od chwili ich przygotowania, aż do przyjęcia lub odrzucenia. Wyszukiwanie w tej bazie obywa się za pomocą numeru dokumentu np. rozpoczynającego się od skrótu nazwy organu wydającego (przykładowo COM dla Komisji) lub numeru procedury zaczynającego się również od skrótu, np. COD dla procedury współdecydowania, SYN dla procedury współpracy CSN dla procedury konsultacji. Po wpisaniu numeru uzyskujemy pełną informację o procesie przyjmowania danego aktu i linki do dokumentów, które są związane z poszukiwanym dokumentem.
Podobną zawartość ma baza danych OEIL[ 73] (Legislative Observatory) przygotowana na zlecenie Parlamentu Europejskiego. Baza OEIL zawiera informacje dotyczące procesu decyzyjnego związanego z przyjmowaniem aktów prawnych Wspólnot. W przeciwieństwie do innych baz znajdujących się na serwerze Komisji w OEIL znajdują się nie tylko informacje o poszczególnych etapach procedury ustawodawczej które już miały miejsce, ale również o tych które mają odbyć się w przyszłości. Podstawowym kryterium wyszukiwania w bazie jest numer dokumentu lub numer procedury. Można również wyszukiwać za pomocą słowa w tytule.
EURODICAUTOM[ 74] otwiera grupę narzędzi terminologicznych. Jest to największa wielojęzyczna baza terminologiczna na świecie, zawiera ponad 6 500 000 terminów i 300 000 skrótów w 11 językach oficjalnych Wspólnoty i dodatkowo w języku łacińskim[ 75]. Baza jest własnością Komisji Europejskiej.
Celem powstania terminologicznej bazy EURODICAUTOM było rejestrowanie specjalistycznej terminologii stosowanej w dokumentach powstających w Komisji Europejskiej, a co za tym idzie ujednolicenie słownictwa stosowanego przez tłumaczy. Baza ta powstała w 1973 roku dzięki wykorzystaniu wiedzy i leksykografii z dwóch innych narzędzi dostępnych ówcześnie dla tłumaczy w Komisji - powstałego w 1964 roku słownika idiomatycznego Dicautom i powstającego w latach 1962-68słownika Euroterm. W pierwszych latach baza zawierała terminy w pierwszych językach oficjalnych - holenderskim, francuskim, niemieckim i włoskim. Terminy w kolejnych językach były dodawane systematycznie po przystąpieniu nowych krajów.
Hasła podzielone są na 48 grup tematycznych i obejmują wszystkie dziedziny działalności Unii Europejskiej, w bazie znajduje się wiele terminów technicznych i specjalistycznych związanych z polityką Unii w dziedzinie rolnictwa, telekomunikacji, transportu, ustawodawstwa, administracji publicznej, rybołówstwa, medycyny, finansów i inne.
Każde hasło zawiera następujące dane: termin i jego definicję, numer danego hasła i informacje administracyjne (kto i kiedy utworzył hasło lub kto i kiedy wprowadził ewentualne zmiany do hasła), odpowiedniki i synonimy danego terminu w innych językach, odnośniki do haseł pokrewnych i inne przypisy.
Nad nowymi hasłami pracuje stale grupa terminologów, wspierana przez personel techniczny, która korzystając ze specjalnego programu Edictor przetwarza hasła terminologiczne dostarczane przez osoby pracujące w Komisji i innych międzynarodowych instytucjach, przede wszystkim tłumaczy i językoznawców, ale także m.in. przez zatrudnionych na przykład w centrach badawczych, czy wydawnictwach. Nowe hasła są także wyszukiwane w publikacjach Unii takich jak np. Oficjalny Dziennik, ale również w popularnej prasie codziennej i specjalistycznej.
Korzystający z bazy Eurodicautom mogą określić i zachować tzw. profil użytkownika, czyli swoje własne parametry wyszukiwania.
Początkowo baza była wykorzystywana dla wewnętrznych potrzeb Służb Tłumaczeniowych i innych osób zatrudnionych w strukturach Unii Europejskiej, obecnie Baza Eurodicautom jest dostępna dla wszystkich zainteresowanych pod adresem internetowym: http://europa.eu.int/eurodicautom/ i notuje średnio około 120 000 zapytań każdego dnia[76].
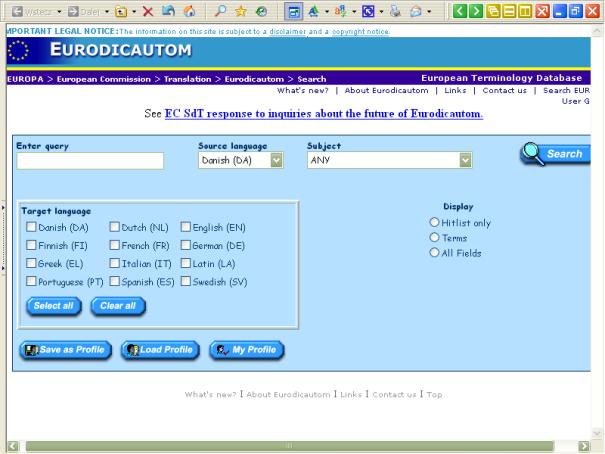
W związku z rozszerzeniem Unii Europejskiej planuje się integrację bazy Eurodicautom i baz danych istniejących w różnych instytucjach przyszłych krajów Wspólnoty w nową międzyinstytucjonalną bazę, a rezultat będzie odzwierciedlał różnorodność i bogactwo językowe krajów członkowskich.
MultiTerm umożliwia tłumaczom dodawanie, zarządzanie i wyszukiwanie haseł (terminów, wyrażeń, skrótów itp.) na poziomie lokalnym. Nowe hasła dodawane są do lokalnej bazy danych aplikacji MultiTerm, po kontroli poprawności i zaakceptowaniu nowego wpisu, hasło jest włączane do bazy Eurodicautom. MultiTerm umożliwia stworzenie swojego własnego glosariusza, do którego dostęp mogą mieć także inni tłumacze.
Baza MultiTerm jest w pełni zintegrowana z aplikacją Translator's Workbench. Co więcej przy korzystaniu z interfejsu systemu Euramis, hasła z bazy Eurodicautom mogą być wyświetlane w formacie aplikacji MultiTerm.
Wygląd aplikacji MultiTerm przedstawiony jest poniżej:
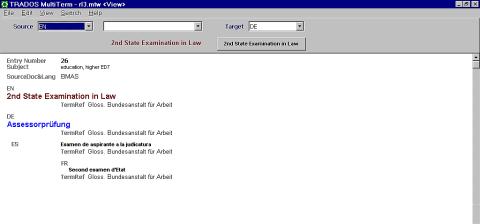
One-stop Shop nie jest terminologiczną bazą danych, ale aplikacją umożliwiającą tłumaczowi jednoczesne przeszukanie kilku innych baz. Działanie One-stop Shop jest oparte o łącza internetowe. Aplikacja ta została opracowana w Służbach Tłumaczeniowych w celu uproszczenia, przyspieszenia i scentralizowania realizacji zapytań terminologicznych. Tłumacz ma możliwość wyboru, które z baz danych wyszczególnionych w oknie aplikacji chce przeszukać. Poza samymi bazami terminologicznymi One-stop Shop może również przeszukać dostępne na serwerach Komisji Europejskiej słowniki, bazy danych, internet itd.
Centralna pamięć tłumaczeniowa powstała jako część projektu Euramis, celem jej powstania było zapewnienie i ułatwienie wszystkim pracującym w SdT równego dostępu do danych. Centralna pamięć tłumaczeniowa nie jest wykorzystywana bezpośrednio w procesie tłumaczenia, jest to baza danych, której zadaniem jest przechowywanie i udostępnianie danych przetwarzanych np. przez Translator's Workbench.
Obecnie centralna pamięć systemu Euramis zawiera ponad 50 milionów jednostek danych we wszystkich 11 językach oficjalnych[ 80]. Najczęściej spotykanymi językami źródłowymi danych są angielski i francuski i w mniejszym stopniu niemiecki, co odzwierciedla fakt, iż prawie wszystkie dokumenty źródłowe powstają w jednym z wymienionych języków. Podział zapytań według języków docelowych jest rozłożony równomiernie.
Translator's Workbench (w skrócie TWB) to lokalna pamięć tłumaczeniowa wspomagająca pracę tłumaczy od 1997 roku. Aplikacja ta umożliwia przeszukiwanie tekstu dokumentów tłumaczonych kiedykolwiek wcześniej przez Służby Tłumaczeniowe pod względem podobieństwa czy nawet identyczności wydzielonych segmentów tych tekstów z fragmentami aktualnie tłumaczonego dokumentu.
Tłumacze, którzy korzystają z TWB, uważają go za niezwykle cenne narzędzie, ponieważ w pewnych rodzajach tekstów powtarzają się te same sformułowania, przykładem są tu charakterystyczne dla Komisji Europejskiej dokumenty o charakterze prawnym, które w dużym stopniu opierają się na dokumentach wydanych wcześniej i już istniejących - w tekstach tego typu frazy i całe zdania powtarzają się z dużym prawdopodobieństwem. Dokumenty prawne wymagają także częstych uaktualnień. Narzędzia pamięci tłumaczeniowych są w stanie szybko pomóc przetłumaczyć wszystkie fragmenty tekstu, które pozostały niezmienione, pozwalając skoncentrować się na nowych elementach i oszczędzić czas pracy poświęcony tłumaczeniu nowego dokumentu.
Zadaniem TWB jest przyspieszenie procesu tłumaczenia poprzez zastępowanie powtarzających się w dokumentach zdań i wyrażeń, co pozwala także zwiększyć dokładność i spójność terminologii czy stylu, choć może się zdarzyć, że praca z segmentami zakłóca płynność tłumaczenia i powoduje przywiązanie do struktury tekstu źródłowego, jednak większość użytkowników po zakończeniu pracy przegląda i poprawia wynikowy tekst. Istotną korzyścią pamięci tłumaczeniowej TWB jest obsługa dokumentów we wszystkich językach oficjalnych oraz współpraca z edytorem tekstu, w którym pracują tłumacze.
Do podstawowych składników systemu pamięci tłumaczeniowej zaliczamy program dopasowujący, program terminologiczny oraz program do redakcji dokumentów.
Program dopasowujący (alignment program) pozwala na utworzenie baz danych pamięci tłumaczenia na podstawie istniejących, zgromadzonych plików z tekstami źródłowymi i z przekładami. Tworzy bazę danych kojarzącą frazy, zdania lub nawet całe paragrafy w języku źródłowym z ich odpowiednikami w języku docelowym, pozwala na dowolne dzielenie i łączenie segmentów. Baza składa się ze zbioru dwujęzycznych segmentów tekstu w języku źródłowym i docelowym.
Program terminologiczny (terminology program) to bardziej wyszukana wersja różnego rodzaju słowników elektronicznych. Niektóre z nich są bardzo skomplikowane i wykorzystują algorytmy "przybliżonej przystawalności" (fuzzy matching algorithms), umożliwiające wyszukanie wszystkich słów o podobnym rdzeniu: znajdą na przykład słowo "logic", kiedy szukanego wyrazu "logical" nie ma w słowniku. Pozwalają także na wyszukanie słowa bezpośrednio w pamięci tłumaczenia, wyświetlając je następnie wraz z kontekstem, co jest o wiele bardziej użyteczne.
Program do redakcji dokumentów (document editor). Jest to główny program, w którym ma miejsce właściwy proces tłumaczenia tekstu. Wyświetla dwa okna, z tekstem źródłowym i docelowym. Wyświetlone segmenty albo dokładnie pasują do fragmentów tekstu źródłowego, gdy program odnalazł w bazie danych fragment identyczny z aktualnie tłumaczonym, albo są wynikami przybliżonej przystawalności (fuzzy matching) i różnią się nieco od oryginału. Translator's Workbench współpracuje z popularnymi edytorami tekstu, zamiast uczyć się obsługi nowego interfejsu podczas pracy nad tekstem tłumacze korzystają z oprogramowania Microsoft Word, co ułatwia także redakcję tekstu.
Aby skorzystać z pamięci tłumaczenia, najpierw trzeba ją utworzyć przy pomocy programu dopasowującego. Jego zadanie polega na podziale tekstu źródłowego i wynikowego na segmenty. Wzajemne ich dopasowanie należy już do użytkownika, może on przy tym łączyć ze sobą mniejsze segmenty, co jest przydatne przy tłumaczeniu na języki, w których zdania są zwykle dłuższe i mają bardziej złożoną strukturę niż zdania w języku źródłowym. Nie można dzielić segmentów na jednostki mniejsze od zdania. Proces dopasowywania jest częściowo zautomatyzowany - program analizuje kolejne pary segmentów i zatrzymuje się, gdy napotka problemy wymagające decyzji użytkownika, np. gdy fragment tekstu źródłowego jest o wiele dłuższy od odpowiedniego fragmentu tłumaczenia. Translator's Workbench dokonuje dopasowania automatycznie, analizując długość segmentów tekstu, ich formatowanie, występowanie cyfr i specjalnych znaków, następnie wyświetla schemat dopasowania w postaci graficznej.
Po utworzeniu bazy danych (w postaci pliku lub sieci skojarzeń) można przystąpić do właściwego tłumaczenia. Na ekranie pojawiają się okna z tekstem źródłowym i przekładem, okno pamięci tłumaczenia i zwykle także okno słownika. Translator's Workbench otwiera do pracy pojedyncze okno programu MS Word, osobno wyświetlany jest aktualny segment w obu wersjach językowych. Po wczytaniu dokumentu w akceptowanym przez edytor formacie, można przystąpić do tłumaczenia. Tekst źródłowy pojawia się podzielony na segmenty, umieszczenie kursora w jednym z nich powoduje jego uaktywnienie (zmiana koloru tekstu lub wyświetlenie go w osobnym oknie). Automatycznie lub po wybraniu odpowiedniej opcji następuje uruchomienie pamięci tłumaczenia. Znaleziony w niej dokładny odpowiednik segmentu źródłowego zostaje wstawiony do tekstu wynikowego. Jeśli dopasowanie nie jest dokładne, program może wstawić segment pasujący najlepiej (zgodność określana jest w procentach) lub wyświetlić kilka z nich do wyboru użytkownika. Translator's Workbench oferuje funkcję, która umożliwia automatyczne wstawienie wszystkich pasujących w 100% segmentów i zatrzymuje się tylko przy tych, dla których nie znaleziono odpowiednika, można także dowolnie łączyć i dzielić segmenty podczas tłumaczenia.
Po zakończeniu tłumaczenia segmentu można wysłać go do pamięci i uruchomić ponownie opcję wstępnego tłumaczenia. Translator's Workbench potrafi automatycznie dokonywać konwersji formatów zapisu dat i liczb (zamieniać kropki dziesiętne na przecinki), przeliczać metry na stopy a nawet tłumaczyć niektóre akronimy.
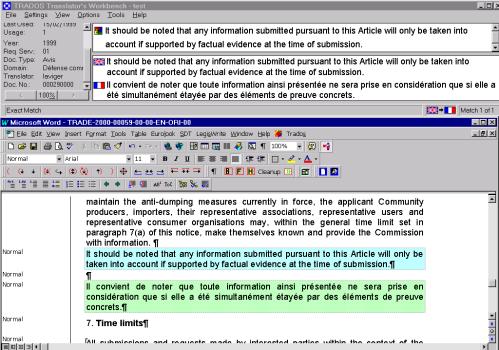
Podczas pracy nad tekstem można wyszukiwać pojedyncze wyrazy w słowniku, a często też frazy lub zdania w pamięci tłumaczenia. Jedna z funkcji TWB wyświetla wszystkie fragmenty tekstu zawierające dany wyraz - zarówno segmenty źródłowe, jak i wynikowe, a nawet fragmenty plików użytych do zbudowania sieci skojarzeń. Odnalezione segmenty mogą być następnie zmodyfikowane a wprowadzone zmiany - automatycznie uwzględnione w uprzednio przetłumaczonym tekście. TWB pozwala podczas pracy z dokumentem na usunięcie konkretnych segmentów z pamięci tłumaczenia lub ich modyfikację.
Aplikacja TWB może współpracować z bazą MultiTerm, pozwalając na automatyczne sprawdzanie terminologii, jeśli żaden pasujący segment nie został znaleziony w pamięci tłumaczeniowej.
W 1976 roku Komisja Europejska nabyła prawa do jednej z wersji rozwijającego się od końca lat pięćdziesiątych systemu tłumaczenia maszynowego SYSTRAN (skrót od System Translation). System został rozwinięty i przystosowany do wewnętrznych potrzeb administracji Komisji i Służb Tłumaczeniowych.
Najczęściej wykorzystywaną funkcją systemu EC Systran jest funkcja tłumaczenia maszynowego. Dostęp do niego mają tłumacze oraz pracownicy Komisji Europejskiej, stanowi istotne narzędzie wspomagające pracę tłumaczy i administracji Komisji Europejskiej.
Tłumaczenie maszynowe odbywa się na zasadzie przekładu z języka źródłowego na język docelowy przy pomocy systemu słowników i programów lingwistycznych. Obecnie system obsługuje 18 par językowych spośród 110 możliwych kombinacji, wśród których angielski i francuski występują w największej liczbie par. I tak możliwe jest tłumaczenie z języka angielskiego a języki: francuski, grecki, hiszpański, holenderski, niemiecki, portugalski i włoski. Tłumaczenie z języka francuskiego możliwe jest na angielski, holenderski, niemiecki, portugalski, hiszpański i włoski, a z języka niemieckiego na angielski i francuski. Możliwe jest także tłumaczenie z języka hiszpańskiego na angielski i francuski oraz z języka greckiego na francuski.
Jednym z kryteriów doboru par językowych były wewnętrzne potrzeby Komisji - język angielski i francuski są w niej głównymi językami roboczymi i językami źródłowymi znaczącej części powstających dokumentów. Ze względu na jakość wyniku tłumaczenia preferuje się rozwój par z jednej rodziny językowej, np. pary z rodziny języków romańskich (np. francuski-włoski), germańskich (angielski-niemiecki), szczególnie satysfakcjonującą jakość uzyskuje się w przypadku języków romańskich. Kolejnym kryterium doboru są ograniczenia budżetowe - nie jest możliwe opracowanie 110 idealnie działających par. Jeśli kraje członkowskie były lub są chętne współfinansować projekt, to wybrana para językowa ma pierwszeństwo w rozwoju. Tak było m.in. w przypadku ostatnio powstałych par: angielsko-greckiej i grecko-francuskiej.
Jakość uzyskanego tłumaczenia zależy od kilku czynników, przede wszystkim wartość tłumaczenia wynikowego warunkowana jest stanem zaawansowania prac nad rozwojem danej wersji językowej, stopniem podobieństwa między językami, a także jakości samego dokumentu źródłowego - czy jest on czytelny, czy zawiera błędy literowe, czy jest poprawny syntaktycznie.
W ostatnich latach systematycznie rośnie wykorzystanie systemu EC Systran. W 1998 roku ponad 400 000 stron zostało przetworzonych przez EC Systran[ 82]. W 2000 roku było to 546 000 stron, z czego 185 000 czyli 34% całości zapotrzebowania pochodziło z SdT[ 83]. W 2001 roku - prawie 800 000 stron, z tego około 40% stanowiły zapytania SdT, reszta pochodziła od administracji[ 84].
EC Systran jest zdolny przetłumaczyć do 2000 stron na godzinę, tym samym zapewniając szybki dostęp do informacji także w języku, którego nie zna pytający.
Główną siłą systemu są jego słowniki, których zawartość została zaadaptowana na potrzeby działania Komisji. Słowniki systemu rozwijane od ponad 25 lat są wiarygodnym źródłem informacji. Początkowo były dwujęzyczne (język źródłowy-język docelowy), ale w miarę dodawania nowych języków oficjalnych ich struktura zmieniła się i wygląda następująco: jeden język źródłowy-wiele języków docelowych.
Proces tłumaczenia podzielony jest na 3 zasadnicze etapy: analiza tekstu w języku źródłowym, transfer dwujęzyczny oraz synteza w języku docelowym[ 85]. Proces tłumaczenia zaczyna się od złożenia zamówienia. Każdy urzędnik Komisji Europejskiej uzyskuje dostęp do systemu poprzez pocztę elektroniczną - wysyłając do serwera systemu EC Systran wiadomość e-mail z załączonym tekstem, którego tłumaczenie chce uzyskać. Po kilkunastu minutach tą samą drogą uzyskuje odpowiedź. Tłumacze mają dodatkową możliwość dostępu poprzez system Euramis (rys. 13).

Kiedy dokument trafia do systemu jest poddawany ustalonemu przetwarzaniu wstępnemu, rozpoznany zostaje format dokumentu, a także wyodrębnione zostają informacje dotyczące formatowania od rzeczywistego tekstu dokumentu. Wstępna analiza daje także podstawy do podzielenia tekstu na jednostki tłumaczeniowe, zazwyczaj są to zdania. Następnie rozpoczyna się faktyczna analiza językowa. Na początku jest to analiza poszczególnych słów dokumentu źródłowego dokonywana przy użyciu pierwszego ze słowników systemu EC Systran - Stem Dictionary. Każde hasło w tym słowniku zawiera tłumaczenie słowa na język docelowy oraz informacje syntaktyczne dotyczące danego słowa - kody syntaktyczne i semantyczne, takie jak przynależność do danej części mowy i inne informacje gramatyczne. Jeśli dane słowo zostało rozpoznane, zostają do niego dołączone określone informacje, dzięki którym możliwy jest następny krok, czyli sześcioetapowa analiza składni i rozbiór gramatyczny przeprowadzane na tekście w języku źródłowym. Analiza ta skupia się na uzyskaniu jak największej ilości informacji dotyczących strony syntaktycznej i semantycznej, aby ustalić wzajemne relacje pomiędzy wszystkimi wyrazami w zdaniach. Na tym etapie procesu tłumaczenia określane są ostateczne granice zdań, przeprowadzana jest analiza homograficzna, której zadaniem jest zakwalifikowanie wyrazów do części mowy, następnie ustalane są wzajemne zależności między jednostkami syntaktycznymi, identyfikowane są podmioty i orzeczenia w wydzielonych zdaniach.
W rezultacie tej analizy do każdego słowa dołączane jest tzw. "byte area", które zawiera wszystkie informacje, jakie udało się uzyskać, które wykorzystywane są w kolejnych etapach procesu tłumaczenia.
Następny etap rozpoczyna właściwy proces tłumaczenia, jest to tzw. transfer dwujęzyczny. Dla zidentyfikowanych wcześniej słów i związków wyrazowych wprowadzane są ich odpowiedniki w języku docelowym, jednak nie występują one jeszcze we właściwej formie, np. czasowniki występują w bezokoliczniku, rzeczowniki w mianowniku itd.
Finalnym etapem procesu tłumaczenia jest synteza tekstu w języku docelowym, polega on na uporządkowaniu elementów zdania według reguł rządzących danym językiem docelowym w zakresie morfologii, fleksji, składni, szyku wyrazów w zdaniu itp. Przed odesłaniem dokumentu następuje jeszcze przywrócenie wyjściowego formatu strony.
Na różnych etapach analizy i syntezy system sięga do zasobów drugiego ze słowników tj. IDLS Dictionary (Idiom/Limited Semantics). Jest to słownik idiomów i związków wyrazowych. Każde z haseł (słowa i wyrażenia) przetłumaczone są na język docelowy w ściśle określonym kontekście, a możliwość porównania tekstu z zasobami tego słownika zapobiega tłumaczeniu niektórych słów i wyrażeń dosłownie, przykładowo "agent pathogène" (czynnik chorobotwórczy) tłumaczony jako "krankheitserregender Beamter" (urzędnik chorobotwórczy), a "bunch of people" (grupa ludzi) jako "une botte de gens" (pęk ludzi)[ 87].
Aby eliminować problem wieloznaczności słów w zależności od kontekstu stworzono glosariusze tematyczne zwane "Topical Glossaries" (TGs). Zawierają one terminy wraz z odpowiednikami dotyczącymi jednej dziedziny, co umożliwia tłumaczenie zawężone do jednej dziedziny lub dokumentu pewnego rodzaju. Zlecenie tłumaczenia z określeniem konkretnego glosariusza przyczynia się do polepszenia jakości wyniku tłumaczenia.
W połowie lat dziewięćdziesiątych słowniki zostały wzbogacone o hasła z bazy Eurodicautom - jeśli Systran napotkał w analizowanym tekście wyraz lub wyrażenie, którego nie znalazł w swoich słownikach, to przeszukuje Eurodicautom.
TMan jest systemem do półautomatycznego tłumaczenia dokumentów o pewnym stopniu powtarzalności zachodzącej na poziomie wyrażeń. Zamienia on fragmenty tekstu - ciągi znaków w języku źródłowym (przede wszystkim słowa i wyrażenia) na odpowiednie fragmenty w języku docelowym. W wyniku takiej operacji powstaje tekst, w którym pewna część tekstu pozostała w języku źródłowym, a wybrane wyrażenia zostały przełożone na docelowy język tłumaczenia. Narzędzie to jest szczególnie przydatne w sytuacji, kiedy istnieje potrzeba przetłumaczenia większej ilości dokumentów o dużej powtarzalności, podobnej frazeologii i strukturze, w przypadku takich dokumentów otrzymuje się względnie dobre efekty.
Powtarzalność w dokumentach Komisji częściej występuje na poziomie standardowego słownictwa - słów i wyrażeń, niż całych zdań czy dłuższych fragmentów tekstu. Dokumentami zawierającymi dużą ilość powtarzających się elementów są np. regularnie wydawane publikacje wielojęzyczne takie jak comiesięczny Biuletyn działalności Komisji, w przypadku którego wiele tych samych wyrażeń można znaleźć w każdym wydaniu. Analiza wcześniejszych numerów pozwoliła na stworzenie bazy danych wyrażeń, którą można wykorzystać w kolejnych numerach.
System TMan działa w ten sposób, iż dla dokumentów spełniających kryterium wysokiej powtarzalności tworzy bazę ciągów wyrazowych. Dla każdej serii dokumentów powstaje osobna baza wyrażeń na podstawie jednego dokumentu z grupy. Następnie system dokonuje analizy pozostałych dokumentów pod względem łańcuchów wyrazowych mających swoje odpowiedniki w bazie i ich częściowego przekładu. Ciągi wyrazów zamieniane są w kolejności malejącej - od najdłuższego do najkrótszego, np. wyrażenie "proposition de directive" (z franc. propozycja dyrektywy) będzie zastąpione przed pojedynczym słowem "proposition". Dzięki temu zamiana krótszych i dłuższych segmentów nie koliduje ze sobą. Zamieniane segmenty mogą być bardzo małe - nawet pojedyncze litery lub akronimy. System zamienia tylko ciągi wyrazowe mające swoje dokładne odpowiedniki w bazie. Zasadę tę można pominąć jedynie w przypadku danych liczbowych, dat czy nazw własnych. W jednej sesji system może dokonać analizy i zamiany wyrażeń w 60 dokumentach tego samego typu. W przeciwieństwie do większości systemów pamięci tłumaczeniowych w jednej sesji możliwa jest zamiana z jednego języka źródłowego na wiele języków docelowych, ale podobnie jak w innych systemach po rozpoczęciu analizy nie jest potrzebny dalszy nadzór użytkownika. Kolejną cechą wyróżniającą jest przeprowadzanie operacji na dokumencie w formacie Word.
Dla przykładu można przedstawić fragment roboczej wersji kontraktu w języku francuskim[ 88]:
La Communauté européenne, représentée par la Commission des Communautés européennes, ici représentée par Monsieur..., Directeur général, d'une part et la firme "...", dont le siège social est à ... ci-après dénommée "le fournisseur", représentée par Monsieur... en vertu de la délégation lui conférée par ladite société (...)[ 89]
Fragment ten zostałby przetłumaczony w następujący sposób - językiem docelowym jest hiszpański, kursywą zaznaczono fragmenty wymagające tłumaczenia po analizie:
La Communauté européenne, représentée par la Commission de las Comunidades Europeas, ici représentée par Monsieur..., Director General, y, de otra, la firme "...", con domicilio social en... denominada en lo sucesivo "el proveedor", representada por el Sr..., según el poder otorgado por la citada sociedad (...)
Zastosowanie systemu TMan zwiększa jednorodność stylu tłumaczonych dokumentów, a także pomaga tłumaczowi nieznającemu określonej terminologii na pracę z dokumentami zawierającymi słownictwo z określonej dziedziny. Dlatego wstępne przetworzenie dokumentów przez system TMan stosowane jest często w przypadku tekstów zlecanych tłumaczom zewnętrznym.
Obecnie systemu TMan nie używa się tylko do tłumaczenia, ale także do przechowywania segmentów tekstu w formie bazy wyrażeń we wszystkich językach oficjalnych, które następnie są wykorzystywane w kolejnych opracowaniach danych typów tekstów - opracowana baza wyrażeń przekazywana jest tłumaczowi, który dokonuje przekładu w oparciu o dostarczony zbiór.
System TMan bywa używany także do opracowywania specjalistycznych słowników - glosariuszy, ponieważ potrafi automatycznie tworzyć indeksy z odsyłaczami.
Technologia komputerowego przetwarzania mowy wykorzystywana jest coraz częściej w pracy tłumacza. Liderem wśród producentów narzędzi tego typu jest amerykańska firma Dragon Systems. To właśnie ona jako pierwsza wprowadziła na rynek program do rozpoznawania mowy ciągłej NaturallySpeaking.
Aplikacji Dragon NaturallySpeaking używa prawie 300 tłumaczy pisemnych zatrudnionych w Komisji Europejskiej. Głównym zadaniem NaturallySpeaking jest umożliwienie użytkownikowi komputera PC dyktowania dowolnego tekstu w sposób ciągły (naturalny), a dyktowany tekst zamieniany jest automatycznie na postać znakową. Program osiąga wysoki poziom dokładności - do 98% i wydajności - zapisuje do 160 słów na minutę[ 90]. Dzięki NaturallySpeaking współpraca z komputerem możliwa jest już w siedmiu językach: niemieckim, hiszpańskim, angielskim, francuskim, włoskim i holenderskim. Podstawowy moduł pakietu to prosty edytor tekstu. Da się go także, przy użyciu komend głosowych, korygować i formatować. Można używać jednocześnie głosu i klawiatury - obie ręce są wolne, co znacznie podnosi efektywność pracy. Nieskomplikowany interfejs programu oraz zestaw dobrze przemyślanych klawiszy skrótów (np. do aktywacji i blokowania rozpoznawania) sprawiają, iż posługiwanie się programem jest wygodne i proste.
Program NaturallySpeaking oszczędza czas tłumacza, który nie musi już wpisywać ręcznie znacznej części swojej pracy. Dodatkowymi czynnikami przemawiającym za stosowaniem tej aplikacji są ergonomia i korzyści zdrowotne - używanie programu do rozpoznawania mowy minimalizuje ujemne skutki towarzyszące długotrwałej pracy z klawiaturą i myszką.
Jednak aby skutecznie posługiwać się NaturallySpeaking wymagana jest nienaganna znajomość danego języka i dobra dykcja, ale biorąc pod uwagę poziom przygotowania tłumaczy pracujących w SdT spełnienie tego warunku nie stanowi żadnego problemu.
Zanim powstał system Euramis wszystkie narzędzia wspomagające pracę tłumacza i zasoby terminologiczne dostępne były indywidualnie. Każde z nich rozwijało się, z czasem wciąż wzbogacając się o nowe funkcje (w przypadku aplikacji czy systemów) lub o nowe terminy czy dokumenty w przypadku różnego rodzaju baz danych. Euramis powstał w odpowiedzi na potrzebę stworzenia systemu, który połączyłby wszystkie dostępne narzędzia i zasoby w całość, eliminując tym samym konieczność osobnego korzystania z wszystkich dostępnych środków. Pierwszym krokiem do stworzenia systemu Euramis było przeniesienie zawartości terminologicznej bazy Eurodicautom do słowników systemu tłumaczeń maszynowych Systran. Decydującym krokiem było ogłoszenie przez XIII Dyrekcję Generalną Komisji Europejskiej[ 91] we współpracy z przedstawicielami Służb Tłumaczeniowych przetargu na opracowanie planu rozwoju narzędzi wielojęzycznych i ich integrację w systemy wielojęzyczne[ 92], co zaowocowało opracowaniem projektu nowego systemu, a następnie stopniową jego realizacją.
Architektura systemu Euramis przedstawia się następująco:
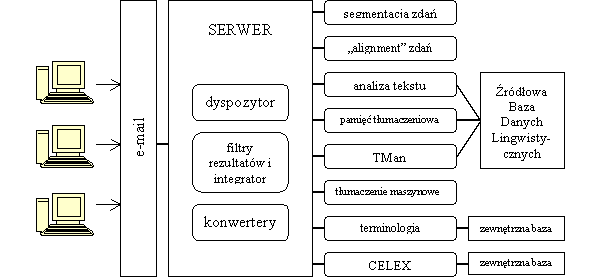
Użytkownik tworzy żądanie wykorzystując aplikację opartą o system Windows. Żądanie składa się z szeregu poleceń zebranych przez zamawiającego w specjalnym pliku zwanym "command file", dotyczących m.in. wybieranych opcji i parametrów oraz określenie pliku lub plików, których to żądanie dotyczy. Specjalny system kontroli uniemożliwia zlecającemu złożenie zamówienia, które nie może zostać zrealizowane, np. przy zleceniu maszynowego tłumaczenia pary językowej nie obsługiwanej przez Systran. Zamówienie wysyłane jest pocztą elektroniczną i trafia do serwera, gdzie program szeregujący zadania (dyspozytor) analizuje przekazane zamówienie (command file) i uruchamia kolejno odpowiednie aplikacje potrzebne do zrealizowania zadania. Aplikacje "znają" swoje zadania w tym procesie, więc mogą pracować niezależnie od siebie i niezależnie od kolejności w jakiej zostały uruchomione. Następnie kolejno odsyłają rezultaty wykonanych zadań do dyspozytora, który przekazuje otrzymane wyniki do następnej aplikacji - integratora, gdzie wszystkie wyniki zbierane są do jednej wiadomości e-mail, która następnie odsyłana jest do zlecającego.
Aby możliwe było łączenie wyników uzyskanych z różnych aplikacji w jedną odpowiedź, co jest bardziej przydatne niż przedstawianie poszczególnych rezultatów oddzielnie, stworzono format pośredni (pivot format), który służy do komunikacji pomiędzy poszczególnymi aplikacjami używającymi swoich własnych formatów zapisu danych. Wymiana danych między różnymi aplikacjami możliwa jest dzięki konwersji danych z jednego systemu do innego. Format pivot wykorzystuje dwubitowe kodowanie[ 94] Unicode (UCS-2), co umożliwia stosowanie innych znaków niż znaki alfabetu łacińskiego i zapis w prawie każdym znanym na świecie języku, a na potrzeby systemu Euramis przede wszystkim rozwiązuje problem z zapisem znaków języka greckiego. Językiem formatu pośredniego jest SGML[ 95], zbliżony do HTML, ale rozszerzony w stosunku do niego o nowe funkcje, takie jak obsługa ukrytego tekstu, czy tworzenie dokumentu składającego się z wielu plików (zachowując jego integrację). Poza opisem zawartości dokumentu (tekst, zdjęcia, animacje), SGML opisuje także jego strukturę logiczną - słowo, akapit, rozdział, sekcję.
Dokument w formacie pivot składa się z nagłówka i treści (tekstu). Najważniejszym elementem nagłówka jest historia, w której zawarta jest lista wszystkich aplikacji, które "pracowały" nad danym dokumentem. Tekst dokumentu w formacie pivot zawiera treść dokumentu źródłowego podzieloną na pojedyncze zdania. Każda aplikacja "pracująca" nad danym dokumentem zostawia "ślad" w historii i dodaje wynik swojej analizy do badanych zdań.
Stworzenie systemu Euramis umożliwiło zgromadzenie i przechowywanie danych lingwistycznych w jednym centralnym punkcie systemu - w bazie LRD[ 96] (Linguistic Resources Database). Dzięki wspólnej bazie LRD wszyscy użytkownicy zyskali dostęp na równych zasadach do informacji, której potrzebują. Wykorzystują to także poszczególne aplikacje współtworzące system Euramis, bo dzięki centralnemu zgromadzeniu możliwy jest podział danych, a nie ich dublowanie - baza eliminuje ponowne tłumaczenie tego samego fragmentu tekstu (frazy, zdania, paragrafu itp.). Zasoby wprowadzone i przechowywane przez jeden z systemów stały się dostępne także dla innych, eliminując konieczność wielokrotnego wprowadzania danych do każdego z systemów osobno. Dzięki dyspozytorowi funkcje poszczególnych aplikacji mogą być integrowane tworząc zestaw zupełnie nowych usług, których rozwinięcie w normalnych warunkach byłoby drogie i czasochłonne.
Dalej przedstawiony jest interfejs systemu Euramis, który w prosty sposób umożliwia korzystanie z szeregu możliwości oferowanych przez niego:
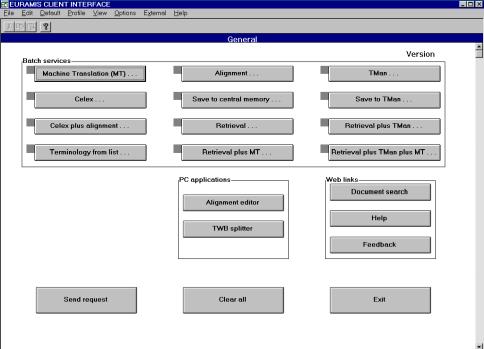
Podstawową rolą systemu Euramis jest integracja usług oferowanych przez dostępne dla tłumaczy wspomagające ich pracę aplikacje. System Euramis oferuje pewien zestaw "usług łączonych". Przykładowo, poza bezpośrednim dostępem do systemu tłumaczenia maszynowego, Euramis gwarantuje również dodatkową opcję w postaci możliwości połączenia zapytania kierowanego do systemu tłumaczenia maszynowego z przeszukaniem centralnej pamięci systemu Euramis i/lub bazy TMan.
Dzięki wybraniu opcji przeszukiwania bazy Celex i podaniu odpowiednich odnośników użytkownik może otrzymać pocztą elektroniczną pełne tytuły lub teksty (do 20 dokumentów) odpowiednich aktów prawnych w jednym lub więcej językach oficjalnych.
Euramis umożliwia wyszukanie określonych terminów w bazie Eurodicautom, a także pośredni dostęp do baz TIS[98] i EUTERPE[ 99]. Użytkownik dostaje plik wynikowy w formacie MultiTerm.
Wyszukiwanie w bazie TMan może być łączone z przeszukiwaniem centralnej pamięci systemu Euramis i/lub skierowaniem zapytania do systemu Systran.
Wsystemie Euramis możliwa jest także operacja tzw. alignment, jest to zabiegpolegający na podziale na pojedyncze zdania dwóch tekstów o tej samej zawartości wyrażonej w języku źródłowym i docelowym, a następnie rozmieszczenie tych zdań równolegle w celach porównawczych. Wynikiem takiej operacji jest uzyskanie pojedynczego pliku zawierającego pary zdaniowe w obu językach, które po sprawdzeniu przekazywane są do centralnej lub lokalnej pamięci tłumaczeniowej. Korzystanie z operacji alignment możliwe jest poprzez pokazany poniżej interfejs systemu Euramis. Zadaniem użytkownika jest wybór odpowiednich wartości spośród dostępnych opcji, m.in. określenie typu dokumentu, formatu wyjściowego, języka źródłowego i docelowego.
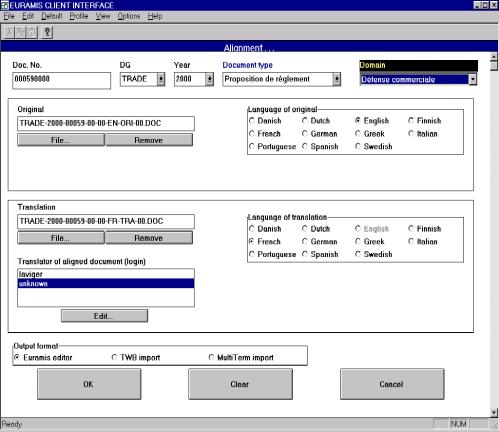
Na potrzeby systemu Euramis rozwinięto specjalną aplikację Alignment Editor, która umożliwia wyświetlenie tekstu źródłowego i docelowego w dwóch równoległych kolumnach. Alignment Editor umożliwia pracę z podzielonym tekstem. Poszczególne komórki mogą być usuwane, scalane lub dzielone. Na podzielonych fragmentach tekstu możliwe są operacje wycinania, kopiowania i wklejania.
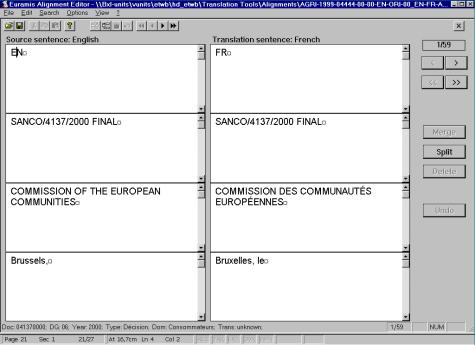
Zastosowanie systemu Euramis można pokazać na przykładzie połączenia działania dwóch aplikacji - pamięci tłumaczeniowych z tłumaczeniem maszynowym, dzięki czemu tłumacz nie musi już dokonywać często trudnego wyboru między tymi dwoma narzędziami. Ta możliwość integracji łączy korzyści wynikające z użycia pamięci tłumaczeniowych (np. lepsza jakość oparta na tłumaczeniu człowieka) z korzyściami, jakie daje tłumaczenie maszynowe (np. oszczędność czasu pracy).
Obecnie Euramis oferuje dwie możliwości przedstawiania wyników tej analizy, w zależności od preferencji użytkownika i typu dokumentu. Użytkownik może wybrać interfejs aplikacji Translator's Workbench lub bezpośrednią edycję gotowego dokumentu w formacie programu Word.
Tekst wyświetlany za pomocą interfejsu TWB składa się z fragmentów podzielonych na zdania. Podczas procesu tłumaczenia kolejnym zdaniom nadawane są specjalne atrybuty - kolory, aby zorientować użytkownika co do możliwości wystąpienia błędów w poszczególnych zdaniach. Kolor zielony oznacza znalezienie dokładnego odpowiednika tego fragmentu, żółty częściowe odpowiedniki, a szary charakteryzuje fragmenty wyodrębnione z pamięci tłumaczeniowych. Tekst oryginalny i tekst po analizie mogą być wyświetlone jeden pod drugim. Do fragmentów przetłumaczonych maszynowo dołączane są (w postaci ukrytego tekstu dającego możliwość porównania) ich odpowiedniki znalezione w pamięciach maszynowych.
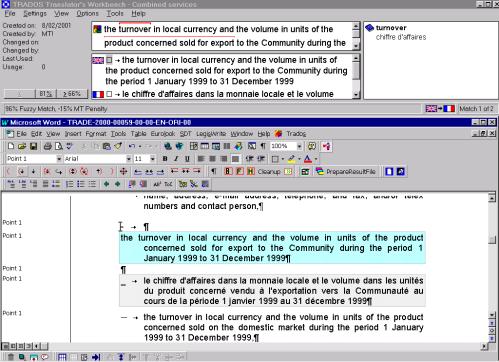
Jeśli dane zostają wyświetlone w formacie Word, prawie bez zmian zostaje zachowane formatowanie tekstu źródłowego (np. pogrubienie, kursywa), fragmenty oznaczone kolorem niebieskim to dokładne odpowiedniki znalezione w zasobach pamięci tłumaczeniowych, częściowe odpowiedniki mają kolor czerwony, karmazynowy zarezerwowany jest dla rezultatów tłumaczenia maszynowego. Użytkownik określa wcześniej stopień akceptowalnej niedokładności tłumaczenia zdań przez pamięci tłumaczeniowe. Wyświetlając rezultaty analizy w formacie Word użytkownik otrzymuje tylko jedną wersję każdego z wydzielonych fragmentów. Poniżej tego poziomu pod uwagę brane są rezultaty tłumaczenia maszynowego.
Poniższy rysunek pokazuje integrację rezultatów obu systemów w formacie Word:
Służby Tłumaczeniowe Komisji Europejskiej mogą korzystać z szeregu narzędzi stworzonych specjalnie na ich potrzeby lub będących częścią systemów informacyjnych instytucji Wspólnoty Europejskiej. Rozwój narzędzi wspomagających tłumaczenie jest procesem ciągłym. Perspektywy dalszego rozwoju ukierunkowane są na dalsze automatyzowanie procesu tłumaczenia oraz dalszą integrację aplikacji i usług. W obliczu rozszerzenia Unii Europejskiej w gestii przyszłych krajów członkowskich, a więc i Polski, jest włączenie się w ten proces.
[ 47] Por. Lavigne E., Tools and Workflow at the Translation Service of the European Commission, SdT, Bruksela 2002; str. 5.
[ 48] Theologitis D., ...and the Profession? (The Impact of New Technology on the Translator), SdT, Bruksela 1998; str. 2.
[49] Tamże, str. 2.
[ 50] Por. Tamże, str. 4.
[ 51] Theologitis D., ...and the Profession? (The Impact of New Technology on the Translator), SdT, Bruksela 1998; str. 10.
[ 52] Około 60% zapytań kierowanych do EC Systran pochodzi od pracowników administracji Komisji Europejskiej.
[ 53] Oprogramowanie służące do elektronicznej transmisji zamówień na tłumaczenie od "klienta" do SdT.
[ 54] Oprogramowanie do wspomagania zarządzania zamówieniami w SdT.
[ 55] Elektroniczny system archiwizujący.
[56] Lokalna pamięć tłumaczeniowa.
[ 57] Oprogramowanie służące do zarządzania procesem tłumaczenia.
[ 58] Por. Theologitis D., ...and the Profession? (The Impact of New Technology on the Translator), SdT, Bruksela 1998; str. 6.
[ 59] Lavigne E., Tools and Workflow at the Translation Service of the European Commission, SdT, Bruksela 2002; str. 29.
[ 60] Skrót od Processing of Electronic Translation Requests.
[ 61] Lavigne E., Tools and Workflow at the Translation Service of the European Commission, SdT, Bruksela 2002; str. 7.
[ 62] Lavigne E., Tools and Workflow at the Translation Service of the European Commission, SdT, Bruksela 2002; str. 9.
[ 63] Lavigne E., Tools and Workflow at the Translation Service of the European Commission, SdT, Bruksela 2002; str. 10.
[ 64] Skrót od Communitatis Europeae Lex.
[ 65] Por. Dell P., Celex reference manual, Biuro Publikacji Wspólnot Europejskich, Bruksela 2002; str. 6.
[ 66] Official Journal of the European Communities.
[ 67] Dostęp poprzez internet: http://europa.eu.int/Celex/
[ 68] Celex Expert Search Service, Visual Quickstart Guide, Biuro Publikacji Wspólnot Europejskich, Bruksela 2001, str. 13.
[ 69] Council Directive 88/378/EEC of 3 May 1988 on the approximation of the laws of the Member States concerning the safety of toys.
[ 70] Dell P., Celex reference manual, Biuro Publikacji Wspólnot Europejskich, Bruksela 2002; str. 128.
[ 71] Dell P., Celex reference manual, Biuro Publikacji Wspólnot Europejskich, Bruksela 2002; str. 129.
[72] Por. Tamże, str. 128
[ 73] Dostęp poprzez internet: http://www.europarl.eu.int/dors/oeil/
[ 74] Skrót od Europe dictionnaire automatisé.
[ 75] Lavigne E., Tools and Workflow at the Translation Service of the European Commission, SdT, Bruksela 2002; str. 14.
[ 76] http://europa.eu.int/eurodicautom/Controller?ACTION=about/ (24.04.03) About Eurodicautom...
[ 77] http://europa.eu.int/eurodicautom/ (15.04.03).
[ 78] Lavigne E., Tools and Workflow at the Translation Service of the European Commission, SdT, Bruksela 2002; str. 18.
[ 79] Lavigne E., Tools and Workflow at the Translation Service of the European Commission, SdT, Bruksela 2002; str. 18.
[80] Tamże, str. 19.
[ 81] Lavigne E., Tools and Workflow at the Translation Service of the European Commission, SdT, Bruksela 2002; str. 19.
[ 82] Guide for freelance translators and typists, SdT, Bruksela 1999; str. 8.
[ 83] Inciarte M. M., Translating for a multilingual community, SdT, Bruksela 2002; str. 14.
[ 84] Lavigne E., Tools and Workflow at the Translation Service of the European Commission, SdT, Bruksela 2002; str. 20.
[ 85] Por. Petrits A., EC SYSTRAN: The Commision's Machine Translation System, SdT, Bruksela 2001; str. 15.
[ 86] Lavigne E., Tools and Workflow at the Translation Service of the European Commission, SdT, Bruksela 2002; str. 21.
[ 87] Por. Sauer-Stipperger R., SYSTRAN Funnies, SdT, Bruksela 1998; str. 2.
[ 88] Blatt A., Translation Technology at the European Commission: Description of a Workflow, SdT, Luksemburg 1998; str. 4.
[ 89] Wspólnota Europejska, reprezentowana przez Komisję Wspólnot Europejskich, reprezentowana tu przez Pana..., dyrektora generalnego, z jednej strony i firmę "...", której siedziba społeczna znajduje się... nazywana następnie "dostarczycielem", reprezentowana przez Pana... w związku z mandatem mu powierzonym przez wspomniane stowarzyszenie (...)
[ 90] Według danych producenta na stronie internetowej: http://www.dragonsys.com/ (17.05.03); ScanSoft, Inc. is the leading supplier of imaging, speech and language solutions...
[ 91] Komisja do spraw telekomunikacji, rynku informatycznego oraz wykorzystania wyników badań naukowych.
[ 92] Przetarg pod nazwą "Development of multilingual tools and their integration into multilingual services".
[ 93] Blatt A., EURAMIS: Added Value by Integration, SdT, Luksemburg 1998; str. 3.
[ 94] 2 bity służą do zapisywania jednego znaku diakrytycznego.
[ 95] Standard Generalised Markup Language.
[96] Baza Danych Lingwistycznych.
[ 97] Lavigne E., Tools and Workflow at the Translation Service of the European Commission, SdT, Bruksela 2002; str. 23.
[ 98] Terminologiczna baza danych Europejskiej Rady Ministrów.
[ 99] Terminologiczna baza danych Parlamentu Europejskiego.
[ 100] Lavigne E., Tools and Workflow at the Translation Service of the European Commission, SdT, Bruksela 2002; str. 24.
[ 101] Lavigne E., Tools and Workflow at the Translation Service of the European Commission, SdT, Bruksela 2002; str. 25.
[ 102] Lavigne E., Tools and Workflow at the Translation Service of the European Commission, SdT, Bruksela 2002; str. 28.
[ 103] Blatt A., EURAMIS: Added Value by Integration, SdT, Luksemburg 1998; str. 10.
Spis treści
W kontekście zarysowanych w pierwszym rozdziale źródeł wielojęzyczności Wspólnoty Europejskiej, uzasadnione są wysiłki krajów wstępujących do Unii, a więc i Polski, w zakresie przetłumaczenia na swój narodowy język unijnego dorobku prawnego. Całość wspólnotowego dorobku prawnego szacuje się na ok. 80 tysięcy Stron Dziennika Urzędowego Wspólnot Europejskich[ 104], przy czym wartość ta jest przybliżeniem, jako że stale przyjmowane są nowe akty prawne, a stare lub ich części, zostają uchylone.
Przyszłe państwa członkowskie zobowiązane są do przetłumaczenia do dnia przystąpienia do Unii prawa pierwotnego (najważniejszego prawa obowiązującego w Unii), czyli wszystkich orzeczeń przekazanych przez Trybunał Sprawiedliwości oraz prawa pochodnego, w tym przypadku priorytetowe jest przetłumaczenie wszystkich rozporządzeń, które stają się bezpośrednio częścią dorobku prawnego nowego państwa członkowskiego. Kolejne dokumenty, które powinny zostać przetłumaczone, to dyrektywy, decyzje oraz akty znajdujące się na liście screeningowej A[ 105]. Dokumenty ujęte na liście B są ostatnimi priorytetami tłumaczenia.
Zadanie przekładu prawa wspólnotowego jest identyczne dla wszystkich przyszłych krajów członkowskich, podobne też są problemy, z którymi się borykają. Dokumenty podlegające tłumaczeniu pełne są specyficznej unijnej terminologii i pojęć, których przełożenie na nowy język może być szczególnie trudne, ponieważ w nowych krajach członkowskich jeszcze do niedawna obowiązywał zupełnie inny system polityczny, prawny, gospodarczy i społeczny niż ten obowiązujący w krajach członkowskich.
Przygotowanie tłumaczeń polskiej wersji Dziennika Urzędowego Wspólnot Europejskich zakłada pracę nad tłumaczeniami na wielu etapach, począwszy od określenia priorytetów tłumaczeń, a następnie wykonania go z zachowaniem wszelkich zasad sztuki przekładu prawnego, przez redakcję stylistyczną do nadania mu formy ostatecznej. Praca nad tekstem tłumaczenia obejmuje następujące etapy: przekład tekstu w formie, w której był opublikowany w serii L Dziennika Urzędowego Wspólnot Europejskich, weryfikacja merytoryczna, weryfikacja językowa, ujednolicenie pod względem terminologicznym, ujednolicenie formalne, weryfikacja prawna i redakcja stylistyczna[ 106].
Do wykonania trudnego zadania, jakim jest przygotowanie tłumaczeń w każdym z krajów kandydujących do członkostwa powołano odpowiednie struktury. Komórki, zwane ogólnie jednostkami koordynacji tłumaczeń (ang. translation coordination units), działają na różnych zasadach w poszczególnych państwach. W Polsce rolę koordynatora tłumaczeń oraz strażnika jakości przekładów pełni Departament Tłumaczeń Urzędu Komitetu Integracji Europejskiej powołany w drodze rozporządzenia Prezesa Rady Ministrów z 24 lipca 2000 roku. Pracownicy departamentu to w przeważającej liczbie językoznawcy i filolodzy, na co dzień weryfikatorzy i terminolodzy.
W tym złożonym zadaniu departament ściśle współpracuje z Komisją Europejską, a w szczególności z jej Służbą Tłumaczeń. Przy powoływaniu struktury tłumaczeniowej Polska otrzymała wsparcie techniczne ze strony Biura TAIEX (Technical Assistance Information Exchange Office), także w formie szkoleń i wizyt studyjnych dla pracowników tej komórki. Ponadto, Departament Tłumaczeń ściśle współpracuje na co dzień z Służbami Tłumaczeń Komisji Europejskiej, ponieważ pomimo różnic w strukturach tych jednostek, problemy z którymi tłumacze borykają się przy przekładaniu acquis communautaire, są często bardzo zbliżone. Dotyczy to przede wszystkim wsparcia technicznego przy opracowywaniu terminologii.
Praca terminologiczna jest niezwykle ważnym elementem procesu przygotowania tłumaczeń. Wątpliwości językowe rozstrzygane są w trakcie weryfikacji, a po licznych konsultacjach ustalone poprawne wersje wprowadzane do bazy danych terminologicznych, gdzie stanowią punkt odniesienia i źródło poprawnej terminologii dla wszystkich.
Baza danych terminologicznych prowadzona jest w Departamencie Tłumaczeń i stanowi przede wszystkim pomoc dla weryfikatorów, jak również dla tłumaczy i osób poszukujących odpowiedzi na kwestie lingwistyczne[ 107]. Pamiętając o tym, że znacznie trudniejsze jest opanowanie słownictwa pomocniczego niż technicznego, baza danych skupia terminologię o charakterze ogólnym, elementy dyskursu prawniczego, oraz podstawowe terminy właściwe dla realiów unijnych. Planowane jest poszerzenie bazy szczególnie o metajęzyk unijny (tzw. eurożargon), ponieważ określenia "nieostre" są często stosowane w dokumentach unijnych stwarzając wiele kłopotów tłumaczom i urzędnikom. Przyjęty w Polsce model bazy zakłada prowadzenie rekordów czterojęzycznych, mając na uwadze wielojęzyczność weryfikatorów oraz możliwość dokonywania przekładu także z innych języków. Często kolekcje terminów w trzech językach (angielski, francuski, niemiecki) departament otrzymuje z Komisji, ich wersja polska opracowywana jest w Departamencie Tłumaczeń. Terminologia opracowywana w Departamencie Tłumaczeń wraz z otrzymanymi z Komisji zbiorami terminologicznymi ukazuje się nakładem UKIE wraz z polskimi terminami w postaci glosariuszy. Glosariusze mają status dokumentów roboczych Komisji i ich rozpowszechnianie może objąć wyłącznie - podobnie jak w Unii - pracowników administracji publicznej oraz ośrodki oświatowe.
Teksty tłumaczeń przed przekazaniem Komisji Europejskiej rozsyłane są do ministerstw i urzędów centralnych celem zaznajomienia ich z brzmieniem przetłumaczonych aktów prawnych. Przekazanie Komisji odbywa się bezpośrednio poprzez umieszczanie plików w bazie Komisji - CCVista[ 108]. Baza CCVista, nazwana tak na kształt istniejącej w Służbie Tłumaczeń bazy SdTVista, powstała w grudniu 2001 roku z inicjatywy Komisji. W założeniu miała ona być narzędziem pracy, służącym zarówno do przekazywania tekstów tłumaczeń, jak i informowania o postępie autoryzacji. Baza ta jest przede wszystkim zbiorem tekstów tłumaczeń wszystkich krajów kandydujących i udostępnia zweryfikowane teksty prawnikom lingwistom Rady i Komisji. Pomimo licznych mankamentów, takich jak ograniczone wyszukiwanie i nikłe możliwości raportowania, korzystanie z tej bazy umożliwia również monitorowanie postępów innych krajów kandydujących. A możliwość sprawdzenia brzmienia tłumaczenia w zbliżonym języku może okazać się pomocna w kwestii terminologicznej.
Baza CCVista, w której przechowywane są zweryfikowane tłumaczenia, umożliwia prawnikom lingwistom pobranie tekstu do weryfikacji i oznakowanie go jako obecnie poddawanego weryfikacji, co zapobiega umieszczeniu przez krajowe komórki koordynacji tłumaczeń nowszej wersji tego tekstu w bazie. Teksty, nad którymi praca została zakończona, oznaczane są jako zweryfikowane. Jednocześnie po uzyskaniu autoryzacji mają one być umieszczane w odrębnej bazie przygotowanej przez Urząd Publikacji Wspólnot Europejskich. Aplikacja ta ma pozwolić prawnikom lingwistom na pełnotekstowe wyszukiwanie oraz oferować możliwości, których nie zapewnia obecna baza. Urząd Publikacji będzie także czerpał z tych zasobów do redakcji i przygotowania tych tekstów do druku. Publikacja acquis communautaire m.in. w polskiej wersji językowej ma stanowić wydanie specjalne Dziennika Urzędowego WE[ 109].
Prace nad rozwojem projektów systemów tłumaczenia maszynowego, półautomatycznego, czy słowników prowadzone są w kilku ośrodkach na terenie naszego kraju i we współpracy z ośrodkami z zagranicy. Zagrożeniami dla rozwoju tego typu projektów i systemów jest brak środków pieniężnych na dofinansowanie badań i ośrodków naukowych, a także wolne i opóźnione wprowadzanie w życie założeń idei społeczeństwa informacyjnego. W tej chwili spośród systemów rozwijanych na potrzeby wspomagania procesu tłumaczenia na uwagę zasługują trzy projekty MATCHPAD, POLENG i LexiTools.
System tłumaczenia maszynowego EC SYSTRAN obejmuje większość języków oficjalnych w tłumaczeniach z języka angielskiego i francuskiego i na te języki. W obliczu rozszerzenia Unii ważne jest zintegrowanie nowych języków do obecnego już istniejącego systemu, dzięki czemu koszty wielojęzycznej komunikacji pomiędzy krajami członkowskimi mogą ulec zmniejszeniu. Komisja Europejska promuje rozwój tych par językowych, które powstały z inicjatywy i przy współudziale finansowym kolejnych państw.
Projekt MATCHPAD[ 110] to przykład zaangażowania polskich instytucji naukowo-badawczych w realizowanie międzynarodowych projektów finansowanych w ramach programu Information Society Technologies (5 Program Ramowy) przez Komisję Europejską.
Celem programu MATCHPAD było stworzenie systemów tłumaczenia maszynowego z języka angielskiego na węgierski i polski oraz z języka węgierskiego i polskiego na francuski poprzez stworzenie oprogramowania wspierającego proces tłumaczenia dokumentów. Wymienione cztery pary językowe mają dołączyć do grupy par obsługiwanych przez EC SYSTRAN. MATCHPAD skierowany jest do administracji publicznej oraz wszystkich instytucji, które zajmują się tłumaczeniem oficjalnych dokumentów z języków i na te języki, które objął projekt. Zakłada się, że MATCHPAD znacznie przyspieszy tempo tłumaczenia oficjalnych dokumentów, a także ułatwi komunikację pomiędzy instytucjami Unii i jej krajami członkowskimi, a kontaktującą się z nimi administracją na Węgrzech i w Polsce, zmniejszając bariery językowe pomiędzy urzędnikami tych krajów a administracją krajów UE, co z pewnością pogłębi proces integracji europejskiej.
Partnerami projektu są: firma Systran S.A. z Francji, specjalizująca się od kilkudziesięciu lat w technologii tłumaczenia maszynowego oraz Uniwersytet w Paryżu, Instytut Lingwistyki Węgierskiej Akademii Nauk, Uniwersytet Śląski (Instytut Filologii Romańskiej - prof. Wiesław Banyś), Uniwersytet Warszawski (Instytut Romanistyki - prof. Bohdan Bogacki) oraz urzędy administracji publicznej - ze strony polskiej Urząd Komitetu Integracji Europejskiej (Robert Polkowski)[ 111]. Ośrodki naukowe odpowiedzialne są za teoretyczny opis składni języka, natomiast urzędy administracji dostarczają terminologię oraz przeprowadzają test oprogramowania. Szczególnie interesujący jest naukowy aspekt prac związany z tworzeniem algorytmów tłumaczących, ponieważ struktura języków ugrofińskich (do których należy węgierski) i słowiańskich (polski) jest o wiele bardziej skomplikowana niż struktura większości języków już istniejących w systemach SYSTRAN. Chociaż MATCHPAD skierowany jest głównie do sektora administracji publicznej, projekt może być w przyszłości rozszerzony na inne dziedziny, np. specjalistyczne tłumaczenia handlowe, inżynierskie lub tłumaczenia stron WWW z wykorzystaniem przeglądarki internetowej.
Zakładano, że projekt MATCHPAD będzie działał w latach 2000-2002, jego koszt wyniesie 1 430 000 euro, zaś dofinansowanie z Unii Europejskiej 1 025 000 euro[ 112]. Realizacja projektu w zakresie języka polskiego została podzielona na dwa roczne etapy: automatyczne tłumaczenie z angielskiego na polski oraz automatyczne tłumaczenie z polskiego na francuski.
W 2001 roku planowo zakończono prace nad pierwszą częścią projektu. Przykładowo, tłumaczenie z angielskiego na polski składa się z następujących modułów[ 113]:
Segmentacja tekstu na wyrazy i zdania.
Analiza fleksyjna i składniowa tekstu angielskiego.
Zastosowanie reguł transferowych angielsko-polskich (składniowych i leksykalnych).
Zastosowanie składniowych reguł syntezy (dotyczących języka polskiego).
Odszukanie w słowniku polskich ekwiwalentów.
Odmiana wyrazów polskich i generowanie właściwych form.
Druga część programu (rok 2002), czyli opracowanie systemu tłumaczącego z języka polskiego na francuski, objęła[ 114]:
Opracowanie i zastosowanie analizy syntaktycznej.
Zgromadzenie danych językowych i utworzenie programów do transferu i syntezy.
Opracowanie danych terminologicznych.
Współpraca znanych ośrodków naukowych i najlepszej na rynku firmy specjalizującej się w tłumaczeniach maszynowych oraz fakt finansowania projektu w dużej części przez Unię Europejską budzi nadzieję uzyskania systemu tłumaczącego wysokiej jakości mogącego stanowić pomoc nie tylko dla tłumaczy zajmujących się przekładem, ale także pracowników administracji obecnych i przyszłych krajów członkowskich, inwestorów i innych osób, dla których poznanie tekstu dokumentów w językach polskim czy węgierskim lub komunikacja w tych językach jest koniecznością.
POLENG jest systemem tłumaczenia tekstów, głównie z dziedziny informatyki, prawa, ekonomii i bankowości, z języka polskiego na język angielski. Projekt systemu powstał na Wydziale Matematyki i Informatyki Uniwersytetu im. Adama Mickiewicza w Poznaniu. Jego koordynatorem jest dr Krzysztof Jassem z Zakładu Metod Numerycznych. W latach 1999-2001 projekt był realizowany na Uniwersytecie w ramach grantu Komitetu Badań Naukowych. Od tamtego czasu środki na jego rozwój zdobywane są w środowisku komercyjnym, przykładowo w roku 2002 w projekt POLENG zainwestował Allied Irish Bank z Irlandii.
Do głównych zadań systemu zalicza się umożliwienie tłumaczenia dokumentów podczas pracy z aplikacjami pakietu Microsoft Office takimi jak Word, Excel, PowerPoint; tłumaczenie listów elektronicznych z poziomu popularnych programów pocztowych, tłumaczenie stron WWW (system współpracuje z przeglądarką Internet Explorer), jak również umożliwienie korzystania z systemu za pośrednictwem sieci Internet.
W rozwoju sytemu można wyróżnić 3 etapy (wersje) nazywane kolejno POLENG-1, POLENG-2 i POLENG-3[ 115]. W roku 2002 zostały zakończone prace nad wersją POLENG-3. Skupiły się one na dopracowaniu systemu na potrzeby tłumaczenia lokalnego i przez Internet. W przeciwieństwie do poprzednich wersji w systemie POLENG-3 poszczególne etapy tłumaczenia zostały rozdzielone i wykonywane są przez niezależne od siebie moduły[ 116]. Dzięki rozdzieleniu poszczególnych etapów możliwa jest większa kontrola poprawności reguł, liczba reguł uległa zmniejszeniu, a ponadto poszczególne moduły mogą zostać wydzielone i wykorzystywane w innych zastosowaniach, np. narzędzia obsługi pozostałych modułów mogą być wykorzystane do tłumaczenia pomiędzy innymi parami języków. Wersja POLENG-3 różni się także od poprzednich nowym formalizmem gramatyki języka polskiego, możliwościami korzystania z systemu POLENG razem z aplikacjami Microsoft Office, rozszerzeniem liczby fraz słownikowych ("zwrotów" tłumaczonych jako całość), ulepszeniem formuły sprawdzania pisowni, poszerzeniem słownika (w tym o terminologię z zakresu bankowości).
Planowana struktura systemu POLENG przedstawia się następująco:
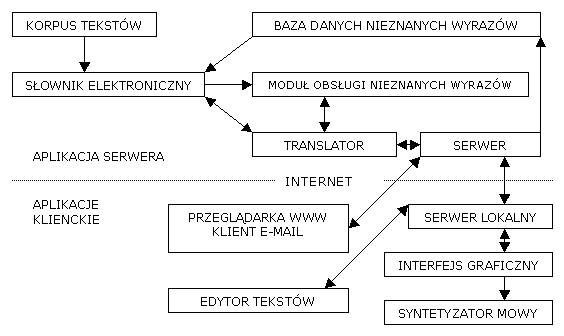
System POLENG składa się z wielu współpracujących ze sobą elementów. W ramach projektu gromadzi się korpus tekstów, co pozwala na wyłonienie leksemów stanowiących bazę leksykalną dla polsko-angielskiego słownika elektronicznego. Przykładowo został zgromadzony korpus tekstów informatycznych o objętości ponad miliona wyrazów, korpus ten pozwolił na wyłonienie ok. 20 000 leksemów stanowiących bazę leksykalną dla polsko-angielskiego słownika elektronicznego.
Elektroniczny słownik polsko-angielski jest istotnym elementem tego systemu tłumaczenia automatycznego. Pełni on rolę obiektu ustalającego cechy morfologiczne, syntaktyczne i semantyczne wyrazów lub fraz tekstu źródłowego. Składa się z pojedynczych haseł (leksemów) oraz kilkudziesięciu tysięcy fraz leksykalnych z dziedziny informatyki, prawa i ekonomii wyselekcjonowanych w wyniku analizy częstości wyrazów w korpusach tekstowych, oraz w oparciu o istniejące słowniki tematyczne. Słownik ma uniwersalny format SGML, który jest przekształcany następnie do postaci binarnej, pozwalającej na efektywne wyszukiwanie wyrazów na potrzeby algorytmu tłumaczenia.
Kolejnym elementem jest moduł obsługi nieznanych wyrazów, służy on do automatycznego poprawiania tzw. literówek w tekstach wejściowych oraz tworzenia hipotez co do własności morfologicznych i syntaktycznych wyrazów spoza słownika.
Translator jest implementacją algorytmu tłumaczenia tekstów zawartych w zbiorze typowych konstrukcji języka polskiego[ 118]. Moduł korzysta z informacji zawartych w słowniku elektronicznym oraz z modułu obsługi nieznanych wyrazów w przypadku wystąpienia w tekście wyrazów spoza słownika.
Zadaniami modułu serwera systemu POLENG są: przetwarzanie tekstu, organizowanie pracy systemu tłumaczenia oraz obsługa aplikacji klienckich. W szczególności wyróżnić można: wstępną obróbkę tekstu oraz obsługę różnych standardów kodowania znaków, obsługę kont wielu klientów, tłumaczenie drogą e-mail, obsługę bazy danych nierozpoznanych przez słownik wyrazów.
Baza danych nieznanych wyrazów zawiera listę wyrazów nie znalezionych w słowniku, ułatwiając kolejne aktualizacje zasobów leksykalnych systemu.
Aplikacja serwera lokalnego jest swego rodzaju translatorem protokołów. Serwer lokalny jest klientem aplikacji serwera systemu POLENG i komunikuje się z nią na pomocą protokołów internetowych. Z drugiej strony serwer lokalny dostarcza usługi tłumaczenia automatycznego poprzez łącza IPC (Inter-Process Communication) dla aplikacji pracujących na komputerze klienta. Możliwe będzie połączenie modułów serwera oraz serwera lokalnego oraz wyeliminowanie kanału internetowego.
Graficzny interfejs użytkownika systemu POLENG składa się z okna edycji tekstu polskiego oraz z okna edycji tekstu angielskiego zsynchronizowanymi tak, by zachować odpowiedniość między zdaniami źródłowymi oraz wynikowymi. W obu oknach edycji dopuszczalne są standardowe techniki edytowania tekstów. Tekst z okna edycji tekstu polskiego przesyłany jest do serwera, skąd w postaci przetłumaczonej, wzbogacony o dodatkowe informacje wraca do aplikacji klienta. Tutaj trafia odpowiednio do okien źródłowego i docelowego. Interfejs graficzny wyświetla warianty tłumaczeń (w oknie edycji tekstu angielskiego) oraz podpowiedzi modułu obsługi nieznanych wyrazów (w oknie źródłowym).
Wyjście głosowe w języku angielskim realizowane jest za pomocą oddzielnego systemu syntezatora mowy Text-to-Speech działającego w środowisku aplikacji klienta. Synteza mowy tekstu angielskiego ma w założeniach ułatwić pracę użytkownika kontrolującego proces translacji.
Moduł "Edytor tekstu" reprezentuje oprogramowanie napisane w języku skryptowym edytora tekstu, odpowiedzialne za automatyczne tłumaczenie tekstów z poziomu edytora przy pomocy lokalnego serwera tłumaczeń. Planowane jest napisanie modułu o powyższych własnościach dla aplikacji Word firmy Microsoft.
Moduł "Przeglądarka internetowa/Klient e-mail" to usługa serwera polegająca na tłumaczeniu tekstu przy wykorzystaniu protokołów internetowych. Użytkownik systemu będzie miał możliwość, stosując standardową przeglądarkę internetową, wpisania w oknie formularza strony internetowej tekstu w języku polskim, który zostanie przetłumaczony oraz odesłany do użytkownika. Drugim wariantem korzystania z systemu za pomocą narzędzi sieciowych będzie tłumaczenie poprzez e-mail (na diagramie "Klient e-mail").
Użytkownik systemu POLENG może w wybranych aplikacjach pakietu MS-Office zainstalować makra, które umożliwiają tłumaczenie całego dokumentu lub jego fragmentu, a także przesłanie zaznaczonego fragmentu do systemu POLENG i pobranie przetłumaczonego fragmentu z systemu POLENG.
Proces tłumaczenia podzielony jest na etapy[ 119]. Pierwszym z nich jest TOKENIZACJA, w trakcie której tekst zostaje podzielony na najmniejsze logicznie części - tokeny - są to wyrazy, liczby, znaki interpunkcyjne itp.
Następnie rozpoczyna się PODZIAŁ NA ZDANIA, kiedy to w zdania zostają połączone listy tokenów.
Trzecim etapem jest ANALIZA LEKSYKALNA, podczas której dla poszczególnych wyrazów zdania odszukiwany jest ich opis w słowniku systemu. Dla wyrazów których system nie odnalazł w słowniku stosowane są procedury pomocnicze takie jak: odszukanie w słowniku wyrazów ortograficznie podobnych lub wyrazów o tej samej podstawie słowotwórczej. Podczas analizy leksykalnej dokonywane jest również łączenie wyrażeń, które ortograficznie stanowią ciąg kilku wyrazów, natomiast z punktu widzenia dalszej analizy stanowią jeden wyraz, np. przysłówek "na pewno".
Kolejnym etapem jest ANALIZA SYNTAKTYCZNA - W wersjach POLENG-1 i POLENG-2 analiza syntaktyczna odbywała sięmetodą zstępującą w głąb[ 120].W systemie POLENG-3 analiza odbywa się metodą wstępującą wszerz- wychodząc od wyrażenia wejściowego przy wykorzystaniu reguł gramatyki dochodzi się do najbardziej ogólnego symbolu gramatyki. Metoda ta ma dwie następujące zalety: mniejsza złożoność obliczeniowa (czyli szybsze działanie), oraz możliwość korzystania z wyników częściowych, gdy okazuje się, że analizowane zdanie jest z punktu widzenia gramatyki systemu niepoprawne lub zawiera wyraz spoza leksykonu systemu. Warto dodać, że podczas analizy syntaktycznej dokonywane są pewne obliczenia na poziomie semantycznym (na przykład zweryfikowanie cech semantycznych dopełnień czasownika).
Dalszym etapem procesu tłumaczenia jest WYBÓR REPREZENTACJI ZDANIA. W efekcie analizy metodą wstępującą otrzymuje się z reguły wiele możliwych reprezentacji analizowanego zdania. Niezbędne jest wybranie - do etapu transferu - jednej, najbardziej prawdopodobnej reprezentacji. W systemie POLENG algorytm wyboru bierze pod uwagę wagę reguł oraz prawdopodobieństwo poszczególnych interpretacji niejednoznacznych wyrazów.
Następnie odbywa się TRANSFER na podstawie reguł transferu opisanych przy pomocy specjalnie opracowanego języka. Składnia języka reguł zbliżona jest do składni języka C, zawiera jednak dodatkowe funkcje, które umożliwiają przekształcenie reprezentacji zdania źródłowego w reprezentację zdania docelowego. Przykładowo: reguła transferu zdania polskiego z podmiotem domyślnym (np. Lubię grzyby)korzysta z funkcji, która reprezentację odpowiadającego zdania angielskiego uzupełnia o podmiot.
Następny etap to MODYFIKACJA SKŁADNIOWA. W tym etapie ustalana jest pożądana kolejność składowych w zdaniu wyjściowym (np. kolejność: podmiot orzeczenie, dopełnienie bliższe, dopełnienie dalsze dla klasycznego zdania prostego), jak również dokonywane są modyfikacje niektórych atrybutów (np. w celu ustawienia czasu zdania podrzędnego). Modyfikacja składniowa dokonywana jest na podstawie reguł zapisanych w tym samym języku co reguły transferu (jednak reguły modyfikacji wymagają nieco innego podejścia).
Przedostatnim etapem jest SYNTEZA MORFOLOGICZNA. W tej fazie tworzone są formy fleksyjne poszczególnych wyrazów języka docelowego, np. went jako forma czasu Past Simple dla czasownika go. Proces ten opiera się o reguły zapisane w tym samym formalizmie co reguły transferu i modyfikacji składniowej.
Proces kończy SYNTEZA POWIERZCHNIOWA. Ten etap to proste wybranie wyrazów (i innych tokenów) z reprezentacji składniowej i połączenie ich w jeden napis.
Graficznym interfejsem użytkownika ułatwiającym korzystanie z systemu tłumaczenia maszynowego POLENG może być program POLENG SHELL[ 121]. Program POLENG SHELL jest wyspecjalizowanym edytorem tekstu przystosowanym do pracy nad tekstem polskim i jego tłumaczeniem na język angielski. Jest to aplikacja przeznaczona dla systemu operacyjnego Windows.
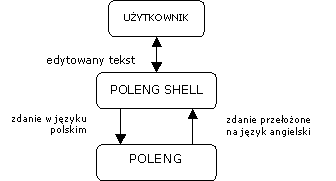
Aby w pełni wykorzystać możliwości programu POLENG SHELL, należy wcześniej uruchomić program POLENG. Program POLENG pracuje w tle jako tzw. serwer DDE[ 123], czyli program przyjmujący komunikaty od innych programów i wysyłający tymże programom odpowiednie dane, natomiast POLENG SHELL jest klientem DDE w stosunku do POLENGA: wysyła do niego tekst polskiego zdania, a odbiera angielskie tłumaczenie.
Początkowo puste okno edycyjne zostaje podzielone na dwa podokna: górne podokno polskie tzn. zawierające oryginalny tekst polski oraz dolne podokno angielskie, w którym pojawi się angielskie tłumaczenie tekstu z podokna polskiego (rys. 23). Istnieje możliwość otwarcia dowolnej liczby okien edycyjnych, dzięki temu można na przykład konfrontować różne teksty, czy też różne wersje przekładu.
Tekst polski można wprowadzać do podokna polskiego na kilka sposobów: można wczytać cały tekst z pliku, wkleić tekst skopiowany z innej aplikacji albo po prostu wpisać tekst za pomocą klawiatury. W obu podoknach okna edycyjnego dostępne są podstawowe możliwości edycyjne wspólne dla wszystkich aplikacji przeznaczonych do edycji tekstów w systemie Windows, tzn. zaznaczanie bloku tekstu, dopisywanie, usuwanie, kopiowanie, wycinanie i wklejanie. Wśród dostępnych opcji możliwe jest wybranie wariantów "Przetłumacz wszystko" lub po zaznaczeniu odpowiedniego akapitu lub zdania - "Przetłumacz fragment".
Od strony technicznej proces tłumaczenia realizowany jest w następujący sposób: za pomocą mechanizmów DDE POLENG SHELL przesyła zdanie po zdaniu tekst przeznaczony do tłumaczenia do programu POLENG, następnie POLENG odsyła tłumaczenie każdego zdania już w wersji angielskiej.
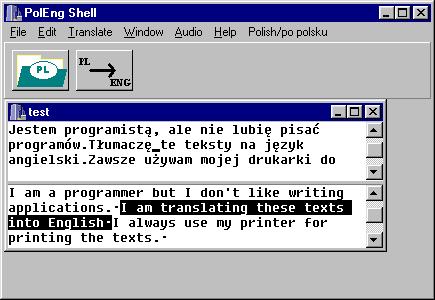
Analizowane zdania oznaczane są za pomocą różnych kolorów, np. nieprzetłumaczone jeszcze zdanie polskie (albo zdanie, które uległo po przetłumaczeniu modyfikacji) wyświetlane jest w kolorze niebieskim, zdanie polskie, które nie mogło zostać w pełni przetłumaczone przez program POLENG (np. zawierające wyrazy, które nie znaleziono w słowniku), zaznaczane jest kolorem czerwonym itp. Ponadto użytkownik ma możliwość korzystania z list wyboru dla poszczególnych wyrazów (tzw. alternatywne tłumaczenia).
System POLENG jest wciąż udoskonalany. W tej chwili (rok 2003) trwają prace nad POLENG 3.1 i przygotowaniem wersji komercyjnej systemu tłumaczącego w obie strony. Powinna ukazać się pod koniec 2003 roku. Główny nacisk kładzie się na tłumaczenie z języka angielskiego na język polski. Pozostałe cele, jakie zespół wyznaczył sobie na ten rok, to znaczne poszerzenie słownika ogólnego (na bazie słownika Oxford), redukcja wymagań pamięciowych oraz obliczeniowych, nowy moduł sprawdzania pisowni oraz udostępnienie tłumaczenia w programach Lotus Notes oraz Internet Explorer.
LexiTools to słowniki i oprogramowanie narzędziowe związane z wykorzystaniem komputerów w lingwistyce - a zwłaszcza w tłumaczeniu tekstów[ 125]. Prace nad projektem prowadzone są przez firmę "Tenar" z województwa podkarpackiego. Podstawową dziedziną działalności firmy "Tenar" jest integracja systemów informatycznych oraz tworzenie własnego oprogramowania[ 126].
Dla poprawnego działania systemu LexiTools wymagane jest zainstalowanie słownika języka polskiego i co najmniej jednego słownika dwujęzycznego. Podstawowy słownik polsko-angielski i angielsko-polski zbudowany został na bazie języka polskiego. Oprócz podstawowego słownictwa zawiera neologizmy, wyrażenia, nazwy własne i idiomy typowe dla języka polskiego. Baza słownikowa jest stale weryfikowana, uzupełniana i uaktualniana, a słowniki (oraz usługi do korzystania z nich i uzupełniania ich zawartości) dostępne są poprzez Internet lub na CD-ROM do samodzielnej instalacji na własnym komputerze. Istnieje możliwość tworzenia własnego słownika. Otwarta architektura LexiTools umożliwia instalację w systemie dowolnych słowników, jednak wersje instalowanych słowników muszą być ze sobą zgodne. Po zainstalowaniu każdego nowego słownika tworzony jest na nowo wspólny indeks umożliwiający przeglądanie ich razem, a hasła z różnych słowników są rozróżniane poprzez wyświetlanie w różnych kolorach.
Ściśle związany z LexiTools, choć rozwijany jako odrębny produkt, jest moduł Pamięci słownikowej (Tenar Translation Memory), dzięki której możliwe jest łatwe tworzenie własnych słowników, wspólny dostęp do bazy słownikowej wielu tłumaczy i wspólna praca nad projektami tłumaczenia. Pamięć słownikowa to nowoczesna metoda półautomatycznego tłumaczenia. Powstała wtedy, kiedy okazało się, że w pełni maszynowe tłumaczenie jest trudne do zrealizowania z powodu złożoności reguł językowych i zmienności żywego języka. Metoda pamięci tłumaczeniowej umożliwia stałe uzupełnianie reguł, które później wykorzystywane są przy półautomatycznym tłumaczeniu.
LexiTools oferuje tłumaczenie wspomagane maszynowo w wersji polsko-angielskiej przy wykorzystaniu modułu Asystenta Tłumacza. Jednak istnieje szereg reguł dotyczących konstrukcji tekstu w języku polskim, aby uzyskać tłumaczenie niezłej jakości w języku angielskim, m.in. zaleca się, aby na ogół używać rzeczowników w liczbie pojedynczej, dodatkowo poprzedzać je przedimkami ("a/an" dla rzeczowników w liczbie pojedynczej. i "the" w liczbie mnogiej), przymiotniki powinny występować w rodzaju męskim, czasowniki (z wyjątkiem ułomnych) powinny być poprzedzone słowem "to". Asystent Tłumacza umożliwia częściowo automatyczną analizę zdań i wybór domyślnych znaczeń. Wynik tłumaczenia zależy od zawartości słownika i współpracy operatora z programem. Użytkownik może wykonać następujące operacje: wybrać znaczenia i formy słowa, zmienić rozbiór gramatyczny i kolejność słów, a także podać własne znaczenie danego słowa bądź zwrotu. Wybór znaczenia słowa wpływa na dalsze wykorzystanie słownika, ponieważ znaczenia, które są najczęściej wybierane traktowane są jako domyślne. Jeśli mamy zainstalowany serwer Pamięci słownikowej, to wszelkie wprowadzane korekty zostają zapamiętane i są używane przy następnych tłumaczeniach, mogą być także wymieniane między różnymi tłumaczami i posłużyć do generowania nowych słowników.
Po uruchomieniu modułu wyświetlane jest okno:
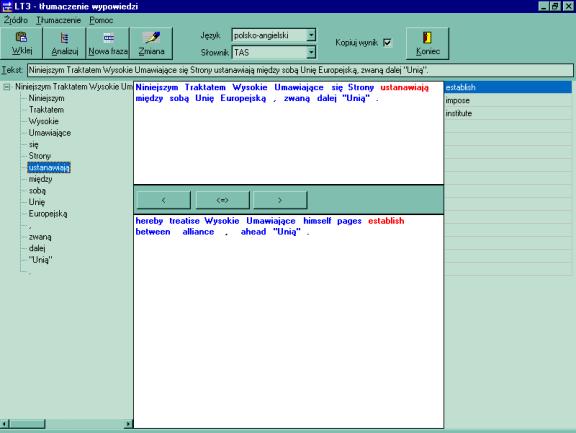
Jak widać w oknie górnym wyświetlany jest tekst źródłowy, a w oknie dolnym tekst przetłumaczony. Po lewej stronie przedstawione jest drzewo rozbioru gramatycznego zdania (rozbiór odbywa się w oparciu o uproszczoną gramatykę zdań otwartych), po prawej wyświetlane są alternatywne możliwości wyboru znaczenia słów lub zwrotów. Wśród dostępnych opcji pracy z tłumaczonym tekstem warto wymienić możliwość zmiany kolejności słów w zdaniu.
W procesie tłumaczenia bardzo wygodne jest używanie przeglądarki słowników. Po jej uruchomieniu możemy wyszukać dowolne hasło i skopiować jego tłumaczenie do schowka. Prezentacja haseł została umyślnie dobrana w taki sposób, by nie przenosić zbędnych informacji. Wszystkie dodatkowe informacje są wyświetlane poza głównym oknem przeglądarki. Po zamknięciu przeglądarki i przejściu do innego programu tekst pozostaje w schowku, z którego możemy go skopiować.
Po połączeniu z Pamięcią słownikową uzyskujemy inteligentny system uczący się. Celem dalszych prac firmy Tenar jest maksymalna automatyzacja procesu tłumaczenia.
Struktura systemu LexiTools to system otwarty. System bazowy, czyli oprogramowanie obsługujące bezpośredni dostęp do słowników jest powszechnie dostępne, nie jest udostępniane ze źródłem, ale jest darmowe. Pozostałe moduły mogą być rozwijane zarówno na zasadach komercyjnych, jak też wolnego oprogramowania. Sposób tworzenia i rozpowszechniania słowników zależy od autorów.
Poza Asystentem Tłumacza do komponentów systemu LexiTools zalicza się także Przeglądarka słowników, Administrator, Edytor oraz Dostęp do słowników internetowych. Przeglądarka słowników działa w następujący sposób: po zainstalowaniu słowników tworzony jest indeks słów i zwrotów, który umożliwia przeglądanie alfabetyczne. Wszystkie zainstalowane słowniki mają wspólny indeks. Dlatego wyszukiwanie jest bardzo wygodne (wystarczy podać początek słów lub zwrotów), wyświetlają się znaczenia ze wszystkich słowników na raz, a jeśli pochodzą one z różnych słowników jest to zaznaczone odpowiednim kolorem.
Program administratora umożliwia przeglądanie pojedynczych słowników (program Przeglądarki umożliwia jedynie przeglądanie ich sumarycznie), odtworzenie struktur słowników (indeksów, zbioru semantycznego i zbioru dodatkowych informacji), rejestrację słowników i oprogramowania, konfigurację powiązań z innymi programami (MS Word, Internet Explorer), czy konfigurację parametrów generatorów mowy. System LexiTools jest zintegrowany z innymi programami użytecznymi w pracy translatorskiej - przykładowo Microsoft Word współpracuje z Przeglądarką słowników i Asystentem Tłumacza.
[ 104] Wagner E., Translation of Multilingual Instruments in the EU, SdT, Bruksela 2000; str. 1.
[ 105] Wykaz wspólnotowych aktów prawnych przedkładanych stronie kandydującej do celów negocjacji, a obejmującym najważniejsze przepisy z danej dziedziny.
[ 106] Por. Rzewuska M., Tłumaczenie acquis communautaire, Biuletyn Analiz UKIE nr 6, Urząd Komitetu Integracji Europejskiej, Warszawa 2001; str. 5.
[ 107] Dostępna także na stronach internetowych UKIE w postaci selektywnego eksportu: http://www.ukie.gov.pl/.
[ 108] CC to angielski skrót dla krajów kandydujących - Candidate Countries.
[ 109] Po wejściu w życie Traktatu z Nicei Dziennik Urzędowy Wspólnot Europejskich będzie nosił nazwę Dziennika Urzędowego Unii Europejskiej.
[ 110] Skrót od Machine Translation Systems for the use of Czech, Hungarian and Polish Administrations.
[ 111] Por. Tłumaczenie maszynowe w projekcie MATCHPAD; http://dach.ipipan.waw.pl/NLP-SEMINAR/ 020116.txt (20.05.03).
[ 112] MATCHPAD Machine Translation Systems for the use of Hungarian and Polish Administrations, Project Facts and Consortium Information; http://www.elpub.org/factsheets/inform/hlt/matchpad.html (18.05.03).
[ 113] Tłumaczenie maszynowe w projekcie MATCHPAD; http://dach.ipipan.waw.pl/NLP-SEMINAR/ 020116.txt (20.05.03).
[ 114] Por. MATCHPAD Machine Translation Systems for the use of Hungarian and Polish Administrations, Project Facts and Consortium Information; http://www.elpub.org/factsheets/inform/hlt/matchpad.html (18.05.03).
[ 115] Por. Strona główna projektu: http://www.ceti.pl/~poleng/ (02.06.03); POLENG jest systemem tłumaczenia tekstów polskich na język angielski...
[ 116] W systemie POLENG-2 wszystkie etapy tłumaczenia są ze sobą powiązane - np. jedna reguła odpowiada zarówno za analizę tekstu polskiego, transfer na język angielski i poprawność składniową tekstu angielskiego.
[ 117] Podstrona projektu: http://www.ceti.pl/~poleng/opis/nowa_wersja/index.html (02.06.03); Nowa wersja systemu, Informacje ogólne...
[ 118] Gramatyka oparta jest głównie na opisie zawartym w książce S. Szpakowicza Formalny opis składniowy zdań polskich, Wydawnictwo Uniwersytetu Warszawskiego, Warszawa 1983.
[ 119] Por. Podstrona projektu: http://www.ceti.pl/~poleng/opis/poleng3.html (02.06.03); POLENG-3, Modułowość...
[ 120] Metoda ta polega na tym, że wychodząc od najbardziej ogólnego symbolu gramatyki, np. reprezentującego zdanie, dochodzi się, przy wykorzystaniu reguł gramatyki, do wyrażenia wejściowego.
[ 121] Por. Graliński F., Wypych M., POLENG SHELL - graficzny interfejs użytkownika dla systemu tłumaczenia maszynowego POLENG (w:) Speech and Language Technology. Volume 3, Poznań 1999; str. 152.
[122] Tamże, str. 152.
[ 123] Dynamic Data Exchange - jeden ze sposobów wymiany danych między procesami w systemie MS-Windows.
[ 124] Graliński F., Wypych M., POLENG SHELL - graficzny interfejs użytkownika dla systemu tłumaczenia maszynowego POLENG (w:) Speech and Language Technology. Volume 3, Poznań 1999; str. 155.
[ 125] Strona projektu: http://tenar.tpi.pl/lexitools/indexp.htm (19.05.03); Co to jest LexiTools...
[ 126] Oficjalna strona firmy Tenar: http://tenar.tpi.pl/ (19.05.03); Otwarty słownik języka polskiego to projekt...
Powstałe w Polsce systemy LexiTools i POLENG zostały sprawdzone pod kątem możliwości wykorzystania ich w tłumaczeniu dokumentów z zakresu prawodawstwa unijnego: traktatów i dyrektyw. Dodatkowo do rozdziału dodano w formie załączników treść wywiadów przeprowadzonych w formie korespondencji za pośrednictwem poczty elektronicznej z koordynatorem projektu POLENG dr Krzysztofem Jassemem z Wydziału Matematyki i Informatyki (Zakład Metod Numerycznych) Uniwersytetu im. Adama Mickiewicza w Poznaniu, a także jednym z jego współpracowników przy tym projekcie - mgr Mikołajem Wypychem, absolwentem Wydziału Matematyki i Informatyki UAM i doktorantem na Wydziale Neofilologii tego samego Uniwersytetu.
Użyty do testu system POLENG dostępny jest w wersji testowej poprzez stronę internetową http://www.ceti.pl/~poleng/zasoby/tlumaczenie/index.htmlhttp://www.ceti.pl/~poleng/zasoby/tlumaczenie/index.html .
Do badań wykorzystano także pełną wersję systemu LexiTools pobraną ze strony http://tenar.tpi.pl/lexitools/indexp.htmhttp://tenar.tpi.pl/lexitools/indexp.htm dnia 2 sierpnia 2003 roku, a następnie zainstalowaną na komputerze użytkownika. Podczas testu system korzystał ze Słownika turystycznego i ogólnego oferowanego przez producenta.
Analizowano fragmenty o różnorodnym zakresie tematycznym, z dziedziny m.in.: ekonomii, edukacji, współpracy międzynarodowej, rolnictwa, energetyki, czy transportu.
Badanie polegało na porównaniu próby tłumaczenia danego fragmentu tekstu z języka polskiego na język angielski przy wykorzystaniu wymienionych programów z oryginalnym angielskim tekstem traktatów (Traktatu o Unii Europejskiej i Traktatu Akcesyjnego) i fragmentów dwóch Dyrektyw.
Traktat o Unii Europejskiej (dokument, który ustanowił Unię Europejską), w wersji skonsolidowanej, składa się z 53 artykułów i 22 stron. Traktat Akcesyjny to umowa międzynarodowa między obecnymi piętnastoma członkami Unii Europejskiej, a dziesięcioma państwami europejskimi, które do niej wstąpią w maju 2004 roku. Jest to dokument niezwykle skomplikowany i obszerny, składający się z około 5,5 tys. stron. Dyrektywy są wytycznymi (zaleceniami) Komisji Europejskiej regulującymi działalność w wielu istotnych obszarach.
Porównania przedstawiają się następująco:
1. Fragmenty Traktatu o Unii Europejskiej (tekst skonsolidowany, uwzględniający zmiany wprowadzone Traktatem z Nicei) w językach polskim[127] i angielskim[ 128].
a. Traktat o Unii Europejskiej, Tytuł I, Postanowienia wspólne, Artykuł A:
Niniejszym Traktatem Wysokie Umawiające się Strony ustanawiają między sobą Unię Europejską, zwaną dalej "Unią".
Niniejszy Traktat wyznacza nowy etap w procesie tworzenia coraz ściślejszego związku między narodami Europy, w którym decyzje podejmowane są jak najbliżej obywateli.
Unię stanowią Wspólnoty Europejskie, uzupełnione politykami i formami współpracy przewidzianymi niniejszym Traktatem. Jej zadaniem jest kształtowanie w sposób spójny i solidarny stosunków między Państwami Członkowskimi oraz między ich narodami[ 129].

b. Traktat o Unii Europejskiej, Artykuł 28:
3. Wydatki operacyjne ponoszone w związku z wprowadzaniem w życie tych postanowień są również pokrywane z budżetu Wspólnot Europejskich, z wyjątkiem wydatków przypadających na operacje mające wpływ na kwestie wojskowe i polityczno-obronne oraz przypadków, gdy Rada, stanowiąc jednomyślnie, postanowi inaczej.
Jeśli wydatki nie są pokrywane z budżetu Wspólnot Europejskich, ponoszą je Państwa Członkowskie według kryterium produktu krajowego brutto, chyba że Rada, stanowiąc jednomyślnie, postanowi inaczej. Państwa Członkowskie, których przedstawiciele w Radzie złożyli formalne oświadczenie na podstawie artykułu 23 ustęp 1 drugi akapit, nie są zobowiązane do wnoszenia wkładu w finansowanie operacji mających wpływ na kwestie wojskowe lub polityczno-obronne[ 130].

c. Traktat o Unii Europejskiej, Artykuł 49:
Każde Państwo europejskie, które szanuje zasady określone w artykule 6 ustęp 1, może się ubiegać o członkostwo w Unii. W tym celu składa ono swój wniosek Radzie, która podejmuje decyzje, stanowiąc jednomyślnie po zasięgnięciu opinii Komisji oraz po otrzymaniu zgody Parlamentu Europejskiego, udzielonej bezwzględną większością głosów jego członków.
Warunki przyjęcia i wynikające z tego przyjęcia dostosowania w Traktatach stanowiących podstawę Unii są przedmiotem umowy między Państwami Członkowskimi a Państwem ubiegającym się o członkostwo. Umowa ta podlega ratyfikacji przez wszystkie umawiające się Państwa, zgodnie z ich odpowiednimi wymogami konstytucyjnymi[ 131].

2. Fragmenty Traktatu Akcesyjnego w języku polskim[132] i angielskim[ 133]:
a. Traktat Akcesyjny, Punkt 4. Prawo spółek, C. Prawo Własności Przemysłowej, I. Wspólnotowy znak towarowy:
2. Nie można odmówić rejestracji wspólnotowego znaku towarowego, będącego przedmiotem zgłoszenia w dniu przystąpienia, na podstawie którejkolwiek z bezwzględnych podstaw odmowy rejestracji wymienionych w art. 7 ust. 1, jeżeli możliwość zastosowania tych podstaw wynikałaby z samego faktu przystąpienia nowego Państwa Członkowskiego[ 134].

b. Traktat Akcesyjny, Punkt 6. Rolnictwo, Punkt A. Ustawodawstwo rolne, punkt 13c:
W artykule 11, po drugim akapicie dodaje się następujący akapit:
"Jednakże, dla Republiki Czeskiej, Estonii, Cypru, Łotwy, Litwy, Węgier, Polski, Słowenii i Słowacji cechami charakterystycznymi mleka, które jest uważane za reprezentatywne są te z roku kalendarzowego 2001 reprezentatywna średnia krajowa zawartość tłuszczu w dostarczonym mleku jest ustalona na 4,21% dla Republiki Czeskiej, 4,31% dla Estonii, 3,46% dla Cypru, 4,07% dla Łotwy, 3,99% dla Litwy, 3,85% dla Węgier, 3,90% dla Polski, 4,13% dla Słowenii, oraz 3,71% dla Słowacji.;"[ 135]

c. Traktat Akcesyjny, Punkt 6. Rolnictwo, Punkt B. Ustawodawstwo weterynaryjne i fitosanitarne, I. Ustawodawstwo weterynaryjne:
Punkt 26b.: Irlandia, Cypr, Malta oraz Zjednoczone Królestwo mogą, nie naruszając przepisów ust. 2 i 3, utrzymać krajowe regulacje dotyczące kwarantanny obejmującej wszystkie ssaki mięsożerne, ssaki z rzędu naczelnych, nietoperze oraz inne zwierzęta, u których możliwe jest wystąpienie wścieklizny, objęte przez niniejszą dyrektywę, jeżeli w stosunku do powyżej wymienionych zwierząt nie można wykazać, iż urodziły się w gospodarstwie pochodzenia i od urodzenia były przetrzymywane w zamknięciu, choć utrzymanie tych regulacji nie może przeszkodzić w zniesieniu kontroli weterynaryjnej na granicach pomiędzy Państwami Członkowskimi."[ 136]

d. Traktat Akcesyjny, Punkt 12. Energia, Punkt A. Przepisy ogólne:
Punkt 8d.: Przy uwzględnianiu indykatywnych wartości bazowych określonych w Załączniku, Republika Czeska zwraca uwagę na fakt, iż osiągnięcie wskazanego celu w wysokim stopniu zależy od czynników klimatycznych w znaczny sposób oddziałujących na ilość energii elektrycznej wytwarzanej w elektrowniach wodnych oraz wykorzystanie energii słonecznej i wiatru.
Narodowy program efektywnego zarządzania zasobami energetycznymi i użycia energii ze źródeł odnawialnych został zatwierdzony przez Rząd w październiku 2001 i zakłada on osiągnięcie do 2005 r. udziału energii elektrycznej ze źródeł odnawialnych na poziomie 3,0% krajowego zużycia brutto energii elektrycznej (z wyłączeniem dużych elektrowni wodnych powyżej 10 MW) oraz na poziomie 5,1 % (włączając w to duże elektrownie wodne powyżej 10 MW).
Przy braku zasobów naturalnych nie jest możliwe dodatkowe znaczące zwiększenie produkcji zarówno dużych jak i małych elektrowni wodnych[ 137].

e. Traktat Akcesyjny, Punkt 16. Środowisko naturalne, D. Kontrola zanieczyszczeń przemysłowych i zarządzanie ryzykiem.
Powyższe krajowe pułapy emisji są wyznaczone w celu szerokiego osiągnięcia przejściowych celów środowiskowych wyznaczonych w art. 5. Oczekuje się, iż osiągnięcie tych celów spowoduje zmniejszanie eutrofizacji gleby w takim stopniu, iż na obszarze Wspólnoty, gdzie osadzanie się azotu pochodzącego z substancji odżywczych przekracza ładunki krytyczne zostanie ograniczone o około 30 % w porównaniu z sytuacją w 1990 r.[ 138]

f. Traktat Akcesyjny, Punkt 18. Współpraca w zakresie wymiaru sprawiedliwości i spraw wewnętrznych, B. Polityka wizowa, Punkt (g):
Cudzoziemiec, który chce podjąć studia na terytorium może przedstawić jako dowód posiadania środków na swój pobyt, dokument potwierdzający zobowiązanie organów państwowych lub osoby prawnej do pokrycia kosztów pobytu cudzoziemca przez dostarczenie mu środków odpowiadających minimum socjalnemu na potrzeby osobiste na 1 miesiąc przewidywanego pobytu, lub dokument poświadczający, że wszystkie koszty związane z jego studiami i pobytem będą pokryte przez organizację przyjmującą (szkołę). Jeżeli suma wymieniona w zobowiązaniu nie osiąga tego poziomu, cudzoziemiec jest zobowiązany przedstawić dokument poświadczający posiadanie środków odpowiadających różnicy pomiędzy minimum socjalnym na potrzeby osobiste i sumą zobowiązania na okres przewidywanego pobytu, jednakże nie więcej niż sześciokrotność minimum socjalnego na potrzeby osobiste. Dokument o przyznaniu środków na pobyt może być zastąpiony decyzją lub porozumieniem o przyznaniu grantu nabytego na mocy traktatu międzynarodowego, który wiąże Republikę Czeską[ 139].

g. Traktat Akcesyjny, Załączniki: Załącznik II: Wykaz, o którym mowa w artykule 20 Aktu Przystąpienia, punkt 8. Polityka transportowa, punkt E. transport Śródlądowy, punkt 2:
W części oznaczonej jako "ROZDZIAŁ I", "Strefa 1" dodaje się następujące pozycje:
"Rzeczpospolita Polska
Część Zatoki Pomorskiej na południe od linii łączącej Północny Perd na wyspie Rugia z latarnią Niechorze.
Część Zatoki Gdańskiej na południe od linii łączącej latarnię Hel oraz boję wejściową do portu w Bałtijsku.";[ 140]

h. Traktat Akcesyjny, Punkt C. Wzajemne uznawanie kwalifikacji zawodowych, III. Zawody medyczne i paramedyczne, Punkt 2. Pielęgniarki, Artykuł 4b.:
W odniesieniu do polskich kwalifikacji pielęgniarek odpowiedzialnych za opiekę ogólną, będą stosowane jedynie następujące przepisy dotyczące praw nabytych:
W przypadku obywateli Państw Członkowskich, których dyplomy, świadectwa i inne dokumenty potwierdzające kwalifikacje pielęgniarki odpowiedzialnej za opiekę ogólną zostały wydane lub których kształcenie zaczęło się w Polsce przed dniem przystąpienia i które nie spełniają minimalnych wymogów szkolenia określonych w artykule 1 dyrektywy 77/453/EWG,
Państwa Członkowskie uznają następujące dyplomy, świadectwa i inne dokumenty potwierdzające kwalifikacje w zakresie pielęgniarskiej opieki ogólnej jako wystarczające dowody, jeśli będzie do nich załączone zaświadczenie stwierdzające, że ci obywatele Państw Członkowskich rzeczywiście i zgodnie z prawem prowadzili działalność pielęgniarki odpowiedzialnej za opiekę ogólną w Polsce w niżej wymienionych okresach: (...)[ 141]

3. Dyrektywy Unii Europejskiej:
a. Dyrektywa Rady Wspólnot Europejskich 93/43/EEC z dnia 14 czerwca 1993 roku w sprawie higieny artykułów żywnościowych.
Art. 2
Dla celów niniejszej Dyrektywy:
- higiena żywności, zwana dalej "higieną" oznaczać będzie wszelkie środki niezbędne dla zapewnienia bezpieczeństwa i zdrowotności artykułów spożywczych.
Środki te będą obejmować wszystkie etapy od momentu produkcji pierwotnej (ta ostatnia obejmuje, na przykład, zbiór, ubój lub wydojenie zwierząt), w czasie przygotowania, przetwarzania, produkowania, pakowania, przechowywania, transportowania, dystrybucji, przeładowywania oraz oferowania do sprzedaży lub dostarczenia konsumentowi;
- przedsiębiorstwo sektora spożywczego oznaczać będzie wszelkie przedsięwzięcie, dla zysku lub nie, państwowe lub prywatne, wykonujące wszystkie razem czy też niektóre z poniżej wymienionych czynności: (...)
- zdrowa żywność oznaczać będzie żywność która nadaje się, jeśli chodzi o higienę, do spożycia przez ludzi[ 142].

b. Dyrektywa Rady Numer 96/51/EC z dnia 23 lipca 1996 roku wnosząca poprawki do Dyrektywy numer 70/524/EEC dotyczącej dodatków do pasz,Dystrybucja i użytkowanie dodatków, Artykuł 9(k):
1. Państwo Członkowskie zagwarantuje, że w dziedzinie żywienia zwierząt wprowadzone do obiegu będą tylko te dodatki, na które zezwolenie zostało wydane zgodnie z niniejszą dyrektywą; Państwo Członkowskie zagwarantuje także, że dodatki będą stosowane tylko jeśli są częścią paszy, co jest zgodne z warunkami określonymi w przepisie prawnym o zgodzie na użycie dodatków[ 143].

System POLENG pozwalał na jednorazowe wprowadzenie tekstu o długości do 500 znaków, który następnie był poddawany analizie (Rys. 24).
Prędkość analizy wynosiła średnio 2-3 sekundy dla każdego analizowanego fragmentu przy transferze rzędu nie więcej niż 115 kbit/s, co jest pełną przepustowością łącza SDI, za pomocą którego komputer łączył się z siecią.
Rysunek 4.1. Wersja testowa systemu POLENG dostępna w internecie - wprowadzenie tekstu do analizy[ 144].

Wynikowy tekst przedstawiany był wersalikami (Rys. 25). Tylko dwukrotnie zaistniała konieczność powtórzenia analizy pewnych fragmentów, prawdopodobnie z powodu obciążenia serwera, na którym pracuje system POLENG.
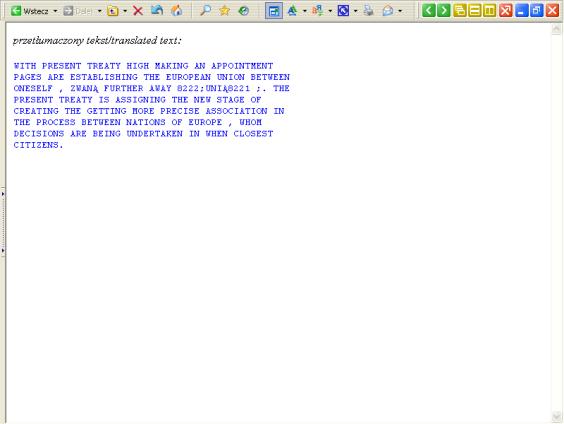
Praca z LexiTools wymagała większego nakładu czasu. Analiza jednego fragmentu zajmowała od 2 do 10 minut z uwagi na niestabilność pracy aplikacji Asystent tłumacza i konieczność częstego zamykania i ponownego uruchamiania programu, a co za tym idzie zmieniania ustawień (język źródłowy i docelowy) oraz ponownego wprowadzenia kolejnych zdań, często w coraz mniejszych fragmentach. Mimo tego niektórych fragmentów nie udało się przetłumaczyć wcale, po trzech nieudanych próbach fragmenty nie przetłumaczone oznaczono w tabelach kursywą. Podczas testu pojawiło się także kilka trudnych do zidentyfikowania komunikatów błędu uniemożliwiających dalszą pracę z programem.
W przypadku analizowanych fragmentów LexiTools nie radził sobie z doborem słownictwa, poprawnością gramatyczną i strukturą zdań. Dokonuje przekładu najprostszą metodą "wyraz po wyrazie" - tłumaczy tylko pojedyncze wyrazy, których odpowiedniki znajdują się w zasobach słownika, z którego korzysta system, często tylko wtedy kiedy są w podstawowej formie gramatycznej (np. rzeczownik w mianowniku). A zasoby słownikowe są ubogie i niewystarczające dla potrzeb tłumaczeń z zakresu prawa unijnego. Ignorowanie reguł gramatycznych widać m.in. na przykładzie tłumaczenia wyrażenia "nie można" jako "do not can", które w gramatyce języka angielskiego jest formą mocno niepoprawną. Konieczność zastosowania specjalistycznych, tematycznych słowników potwierdzają inne przykłady, np. podanie wyrażenia "central heating" (centralne ogrzewanie) jako angielskiego odpowiednika polskiego słowa "co" w tłumaczeniu Dyrektywy Rady Numer 96/51/EC. Jednak istnieją podstawy, aby przypuszczać, że nawet przy zastosowaniu innego, specjalistycznego słownika system ten nie miałby zastosowania w tłumaczeniu tego typu tekstów. Dodatkowo wynik próby przeniesienia przetłumaczonego fragmentu tekstu do aplikacji MS Word zakończył się uzyskaniem fragmentu tekstu niepełnego i wymagającego czasochłonnych poprawek, jak np. w przypadku fragmentu Traktatu o Unii Europejskiej. "(...) on prese*tatio* arty*ułu 2* rest room * anot*er in*ent , do n*t the* are *obowi*zane *p to cartr*dge a* back*ng op*ratio* imp*ct ag*inst *westi* or *olity*zno-o*ronne."
Nie jest wykluczone, że przy udoskonaleniu sposobu edycji tekstu LexiTools mógłby być narzędziem wspomagającym przekład tekstów o dużej powtarzalności, gdzie jego zadaniem mogłoby być zastępowanie określonych wyrażeń występujących z pewną częstotliwością (podobnie jak w przypadku opisywanego w drugim rozdziale systemu TMan). Dobrą stroną LexiTools jest możliwość opracowania i integracji z systemem własnych słowników, co umożliwia dodanie do systemu odpowiednich słowników tematycznych lub co może zaowocować dostosowaniem systemu do potrzeb indywidualnego tłumacza.
Dzięki łatwości stosowania i szybkości analizy, a przy stworzeniu i wykorzystaniu określonego słownika dostosowanego na potrzeby tego typu przekładów, POLENG może być pomocą w uzyskaniu "nieoszlifowanego" tłumaczenia, pozwalającego zrozumieć ogólne znaczenie danego tekstu. W założeniu system ten ma charakter uniwersalny, dlatego na obecnym etapie pojawiły się błędy wynikające z niewłaściwego doboru angielskich odpowiedników polskich słów, np. tłumaczenie "Rada" (zgromadzenie, zespół ludzi) jako "piece of advice" (czyli "rada" w znaczeniu "porada"), "ust." (skrót od "ustęp" - terminu z zakresu prawodawstwa) jako "mouth" (usta), czy słowa "ustęp" jako "toilet" (toaleta). Wyeliminowanie tego typu błędów byłoby możliwe przy zastosowaniu słownika tematycznego, w którym znaczenie słów byłoby zawężone do danej grupy tematycznej. POLENG w przeciwieństwie do LexiTools próbował dokonać przekładu wszystkich wyrazów i wyrażeń, ze wszystkich badanych fragmentów jedynie kilka wyrazów pozostało w swojej polskiej formie, były to następujące wyrazy: zwaną, "Unią", jednakże, mleka, mięsożerne, wścieklizny, pielęgniarek, wydojenie, sześciokrotność. W tym wypadku trudno jest znaleźć element łączący i jednocześnie tłumaczący obecność tych wyrazów w grupie pominiętej podczas tłumaczenia.
Wynik tłumaczenia tekstów z zakresu prawodawstwa unijnego obu systemów nie jest doskonały, jednak wyraźna przewaga pod względem doboru słownictwa i zgodności gramatycznej jest po stronie systemu POLENG.
[ 127] Traktat o Unii Europejskiej (wersja skonsolidowana), 7 lutego 1992 r.; http://www2.ukie.gov.pl/dokumenty/TUE.zip (09.07.03)
[ 128] Treaty on European Union, 7 lutego 1992 r.; http://www.vilp.de/Enpdf/e011.pdf (12.07.03)
[ 129] Traktat o Unii Europejskiej, str. 5.
[ 130] Traktat o Unii Europejskiej, str. 13.
[ 131] Traktat o Unii Europejskiej, str. 21.
[ 132] Traktat Akcesyjny, http://www.doc.ukie.gov.pl/dokumenty/traktat/traktat.zip (19.07.03).
[ 133] Treaty of Accession, http://europa.eu.int/comm/enlargement/negotiations/treaty_of_accession_ 2003/the_treaty_of_accession2003.zip (19.07.03).
[134] Traktat Akcesyjny, str. 1088.
[ 135] Traktat Akcesyjny, str. 1149.
[ 136] Traktat Akcesyjny, str. 1300.
[ 137] Traktat Akcesyjny, str. 1804.
[ 138] Traktat Akcesyjny, Załącznik I: Krajowe poziomy emisji dla SO2 Nox, LZO oraz NH3, które mają zostać osiągnięte do 2010 r., str. 2074.
[139] Traktat Akcesyjny, str. 2135.
[ 140] Traktat Akcesyjny, str. 1578.
[ 141] Traktat Akcesyjny, str. 977.
[ 142] Dyrektywa Rady Wspólnot Europejskich 93/43/EEC z dnia 14 czerwca 1993 roku w sprawie higieny artykułów żywnościowych; http://www.wetgiw.gov.pl/przepisy_wet/Dyrektywy/93_43.htm (10.08.03).
[ 143] Dyrektywa Rady Numer 96/51/EC z dnia 23 lipca 1996 roku wnosząca poprawki do Dyrektywy numer 70/524/EEC dotyczącej dodatków do pasz, Dystrybucja i użytkowanie dodatków, Artykuł 9(k): http://www.wetgiw.gov.pl/przepisy_wet/Dyrektywy/96_51.htm (10.08.03).
[ 144] http://www.ceti.pl/~poleng/zasoby/tlumaczenie/index.html (20.08.03)
[ 145] http://150.254.76.186/~poleng/cgi-bin/hello.pl (20.08.03)
Treść wywiadu przeprowadzonego w formie korespondencji za pośrednictwem poczty elektronicznej z koordynatorem projektu POLENG dr Krzysztofem Jassemem z Wydziału Matematyki i Informatyki (Zakład Metod Numerycznych) Uniwersytetu im. Adama Mickiewicza w Poznaniu.
Pytanie: Jak długo pracuje Pan nad projektem POLENG?
Krzysztof Jassem:Osobiście od 1995 roku - w trakcie przygotowywania pracy magisterskiej. Praca zespołowa datuje się od 1996 roku, a trzon obecnego zespołu ustanowił się w roku 1998.
Pytanie: Co skłoniło Pana do zaangażowania się w ten projekt?
Krzysztof Jassem:Praca doktorska - a potem próba rozwinięcia jej wyników.
Pytanie: Czy rozwija się on zgodnie z przyjętymi założeniami i planem?
Krzysztof Jassem:Co roku mamy inny plan - inny projekt. Są sukcesy (generalnie), ale jakość tłumaczenia pozostawia jeszcze wiele pola do popisu.
Pytanie: Jakie są jego najmocniejsze strony?
Krzysztof Jassem:Jedyny system tłumaczenia automatycznego w Europie Centralnej stosujący metodę transferu (a nie tłumaczenia bezpośredniego).
Pytanie: Co należałoby w nim jeszcze poprawić lub rozwinąć?
Krzysztof Jassem: Reguły parsingu i transferu. Uzupełnić słownik.
Pytanie: Czy i jak według Pana ten system mógłby pomóc tłumaczom pracującym nad przekładami prawa Unii Europejskiej?
Krzysztof Jassem: TAK. Ale trzeba by przystosować słownik systemu.
Pytanie: Czy zna pan inne projekty lub systemy wspomagające tłumaczenie?
Krzysztof Jassem: SYSTRAN tłumaczy prawo europejskie, TRADOS - pamięć tłumaczenia, ESTEam, tłumaczenia oparte na przykładach to najbardziej popularne w Europie.
Treść wywiadu przeprowadzonego w formie korespondencji za pośrednictwem poczty elektronicznej z mgr Mikołajem Wypychem, absolwentem Wydziału Matematyki i Informatyki UAM i doktorantem na Wydziale Neofilologii tego samego Uniwersytetu pracującym nad projektem POLENG.
Pytanie: Jak długo pracuje Pan nad projektem POLENG i jakie zadania zostały Panu przydzielone?
Mikołaj Wypych: Od sześciu lat. W projekcie POLENG zajmuję się: architekturą systemu (reprezentacja wiedzy, sterowanie), ujednoznacznianiem (disambiguation) struktur syntaktycznych, automatyczną korektą błędów pisowni (spell-checkingiem), integracją systemu POLENG z oprogramowaniem zewnętrznym (np. Lotus Notes).
Pytanie: Co skłoniło Pana do zaangażowania się w ten projekt?
Mikołaj Wypych: Hmmm... ogólnie zainteresowanie przetwarzaniem języka naturalnego.
Pytanie: Czy rozwija się on zgodnie z przyjętymi założeniami i planem?
Mikołaj Wypych: Z reguły określamy plany roczne/dwuletnie. Te plany staramy się realizować w całości. Dłużejterminowych planów nie snujemy...
Pytanie: Jakie są jego najmocniejsze strony?
Mikołaj Wypych: Wydaje się, że najskuteczniejsze reguły transferu dla języka polskiego, rozbudowane moduły analizy tekstu, zasoby słownikowe na bazie słownika z Oxfordu, integracja z aplikacjami MsOffice (Word, Excel, PowerPoint, Outlook), MsInternetExplorer, Lotus Notes.
Pytanie: Co należałoby w nim poprawić lub rozwinąć?
Mikołaj Wypych: Metody analizy i transferu tekstu (i tak będzie już zawsze...)
Pytanie: Czy i jak ten system mógłby pomóc tłumaczom pracującym nad przekładami prawa Unii Europejskiej?
Mikołaj Wypych: Myślę, że przy odpowiedniej organizacji pracy tłumaczów oraz rozwinięciu słownika o terminologię prawniczą POLENG mógłby przyspieszyć przekład prawa UE.
Pytanie: Czy zna pan inne projekty lub systemy wspomagające tłumaczenie?
Mikołaj Wypych: Najsławniejszy jest chyba Systran. Dla języka polskiego mamy EnglishTranslator.
Rozwój narzędzi wspomagających tłumaczenie w widoczny sposób usprawnił pracę Służb Tłumaczeniowych, które obecnie tak jak i Unia stoją w obliczu największego rozszerzenia w swojej dotychczasowej historii. Wykorzystanie posiadanego doświadczenia i sposób wdrożenia nowych rozwiązań wyznaczy system ich pracy w rozszerzonej Unii. Polska także od kilku lat przygotowuje się do wejścia w wielojęzyczne struktury Wspólnoty.
Obecna sytuacja polityczna, w jakiej znajduje się Polska, powoduje, że narzędzia wspomagające pracę tłumacza powinny być rozwijane nie tylko dla samych tłumaczy. Język polski jest słabo znany poza granicami naszego kraju, więc dla dobra kontaktów międzynarodowych czy wzrostu poziomu inwestycji rozwój i dostępność systemów tłumaczenia maszynowego, pozwalającego zapewnić chociaż "nieoszlifowaną" wersję tłumaczenia, ułatwiłby komunikację i wzajemne zrozumienie pomiędzy przedstawicielami Polski i innych państw.
Znając wynik prac nad innymi parami systemu EC-Systran duże nadzieje budził projekt MATCHPAD, ponieważ rozwijany był m.in. pod znaną marką firmy Systran. Niestety ostatnia dostępna informacja o projekcie pochodzi z połowy 2002 roku, a jakakolwiek założona polska para językowa wciąż jest nieobecna wśród testowych par systemu Systran, co uniemożliwia dokładne przyjrzenie się jego możliwościom i sprawdzenie ich w teście.
Należy dalej przyglądać się rozwojowi projektu POLENG, który od samego początku konsekwentnie realizuje założone cele, a jeśli z równym wynikiem zostaną zrealizowane kolejne założenia, POLENG może okazać się najlepszym systemem niekomercyjnym dostępnym na potrzeby tłumaczenia polsko-angielskiego i angielsko-polskiego.
Konieczność ograniczenia celów i zakresu tej pracy uniemożliwiła zajęcie się komercyjnymi programami tłumaczącymi, a także porównaniem poziomu rozwoju podobnych narzędzi w innych krajach, szczególnie przyszłych państwach członkowskich Unii Europejskiej.
[ 1] Andersen P., Translation Tools for the CEEC Candidates for EU Membership - an Overview, SdT, Luksemburg 1998. http://europa.eu.int/comm/translation/reading/articles/pdf/1998_01_tt_andersen.pdfhttp://europa.eu.int/comm/translation/reading/articles/pdf/1998_01_tt_andersen.pdf (22.04.03).
[ 2] Blatt A., EURAMIS: Added Value by Integration, SdT, Luksemburg 1998. http://europa.eu.int/comm/translation/reading/articles/pdf/1998_01_tt_blatt2.pdfhttp://europa.eu.int/comm/translation/reading/articles/pdf/1998_01_tt_blatt2.pdf (25.04.03) .
[ 3] Blatt A., Translation Technology at the European Commission: Description of a Workflow, SdT, Luksemburg 1998. http://europa.eu.int/comm/translation/reading/articles/pdf/1998_01_tt_blatt1.pdfhttp://europa.eu.int/comm/translation/reading/articles/pdf/1998_01_tt_blatt1.pdf (22.04.03).
[ 4] Celex Expert Search Service, Visual Quickstart Guide, Biuro Publikacji Wspólnot Europejskich, Bruksela 2001. http://europa.eu.int/celex/htm/doc/en/ expguide_en.pdfhttp://europa.eu.int/celex/htm/doc/en/ expguide_en.pdf (22.04.03).
[ 5] Cunningham K., Translating for a larger Union - can we cope with more than 11 languages?, SdT, Bruksela 2001. http://europa.eu.int/comm/translation/reading/articles/pdf/2001_cunningham.pdfhttp://europa.eu.int/comm/translation/reading/articles/pdf/2001_cunningham.pdf (25.04.03).
[ 6] Dell P., Celex reference manual, Biuro Publikacji Wspólnot Europejskich, Bruksela 2002. http://europa.eu.int/celex/htm/doc/en/referencemanual_en.pdfhttp://europa.eu.int/celex/htm/doc/en/referencemanual_en.pdf (25.04.03).
[ 9] Graliński F., Wypych M., POLENG SHELL - graficzny interfejs użytkownika dla systemu tłumaczenia maszynowego POLENG (w:) Speech and Language Technology. Volume 3, Poznań 1999..
[ 10] Guide for freelance translators and typists, SdT, Bruksela 1999. http://europa.eu.int/comm/dgs/translation/workingwithus/freelance/guide/freelance_guide_en.pdfhttp://europa.eu.int/comm/dgs/translation/workingwithus/freelance/guide/freelance_guide_en.pdf (28.04.03).
[ 12] Inciarte M. M., Translating for a multilingual community,SdT, Bruksela 2002.http://europa.eu.int/comm/dgs/translation/bookshelf/booklet_2002_en.pdf (22.04.03).
[ 13] Lavigne E., Tools and Workflow at the Translation Service of the European Commission, SdT, Bruksela 2002. http://europa.eu.int/comm/dgs/translation/bookshelf/2002_tools_and_workflow_en.pdfhttp://europa.eu.int/comm/dgs/translation/bookshelf/2002_tools_and_workflow_en.pdf (22.04.03).
[ 14] MATCHPAD Machine Translation Systems for the use of Hungarian and Polish Administrations, Project Facts and Consortium Information; http://www.elpub.org/factsheets/inform/hlt/http://www.elpub.org/factsheets/inform/hlt/matchpad.html (18.05.03)..
[ 15] Michałowska-Gorywoda K., Służby lingwistyczne Unii Europejskiej, Kwartalnik Studia Europejskie nr 03/2001, Centrum Europejskie Uniwersytetu Warszawskiego, Warszawa 2001..
[ 16] Multilingualism in the European Commission: A long-standing tradition and an asset to the European Union, (Memorandum) MEMO/03/37, Bruksela 2003. http://tinyurl.com/7wekhttp://tinyurl.com/7wek (28.04.03).
[ 17] Petrits A., EC SYSTRAN: The Commision's Machine Translation System, SdT, Bruksela 2001. http://europa.eu.int/comm/translation/reading/articles/pdf/2001_mt_mtfullen.pdfhttp://europa.eu.int/comm/translation/reading/articles/pdf/2001_mt_mtfullen.pdf (18.05.03).
[ 19] Rzewuska M., Przygotowania służb tłumaczeniowych instytucji UE do rozszerzenia, Biuletyn Analiz UKIE nr 8, Urząd Komitetu Integracji Europejskiej, Warszawa 2002..
[ 20] Rzewuska M., Tłumaczenie acquis communautaire, Biuletyn Analiz UKIE nr 6, Urząd Komitetu Integracji Europejskiej, Warszawa 2001. .
[ 21] Sauer-Stipperger R., SYSTRAN Funnies, SdT, Bruksela 1998. http://europa.eu.int/comm/translation/reading/articles/pdf/1998_01_tt_sauerstipperger2.pdfhttp://europa.eu.int/comm/translation/reading/articles/pdf/1998_01_tt_sauerstipperger2.pdf (18.05.03).
[ 22] Słownik współczesnego języka polskiego, Wydawnictwo Przegląd Reader's Digest, Warszawa 1998, tom 2..
[ 23] Strona główna projektu LexiTools i podstrony:http://tenar.tpi.pl/lexitools/indexp.htm (19.05.03)..
[ 25] Theologitis D., ...and the Profession? (The Impact of New Technology on the Translator), SdT, Bruksela 1998. http://europa.eu.int/comm/translation/reading/articles/pdf/1998_01_tt_theologitis.pdfhttp://europa.eu.int/comm/translation/reading/articles/pdf/1998_01_tt_theologitis.pdf (25.04.03).
[ 26] Tłumaczenie maszynowe w projekcie MATCHPAD; http://dach.ipipan.waw.pl/NLP-SEMINAR/http://dach.ipipan.waw.pl/NLP-SEMINAR/ 020116.txt (20.05.03). .
[27] Traktat Akcesyjny, http://www.doc.ukie.gov.pl/dokumenty/http://www.doc.ukie.gov.pl/dokumenty/traktat/ traktat.zip (19.07.03)..
[28] Traktat Amsterdamski z 2 października 1997 r., http://www2.ukie.gov.pl/dokumenty/XVII.ziphttp://www2.ukie.gov.pl/dokumenty/XVII.zip (24.05.03)..
[29] Traktat o Unii Europejskiej z 7 lutego 1992 r., http://www2.ukie.gov.pl/dokumenty/XVI.ziphttp://www2.ukie.gov.pl/dokumenty/XVI.zip (24.05.03). .
[30] Traktat o Unii Europejskiej (wersja skonsolidowana) z 7 lutego 1992 r., http://www2.ukie.gov.pl/dokumenty/TUE.ziphttp://www2.ukie.gov.pl/dokumenty/TUE.zip (09.07.03).
[31] Traktat o Wspólnocie Europejskiej (Traktat Rzymski) z 25 marca 1957 r., http://www2.ukie.gov.pl/dokumenty/I.ziphttp://www2.ukie.gov.pl/dokumenty/I.zip (24.05.03)..
[32] Treaty of Accession (Traktat Akcesyjny w języku angielskim), http://europa.eu.int/comm/enlargement/negotiationshttp://europa.eu.int/comm/enlargement/negotiations/treaty_of_accession_2003/the_treaty_of_accession2003.zip (19.07.03)..
[ 33] Treaty on European Union - consolidated version (Traktat o Unii Europejskiej - wersja skonsolidowana, w języku angielskim),http://www.vilp.de/Enpdf/e011.pdf (12.07.03).
[ 34] Wagner E., Translation of Multilingual Instruments in the EU, SdT, Bruksela 2000. http://europa.eu.int/comm/translation/reading/http://europa.eu.int/comm/translation/reading/articles/pdf/2000_tp_wagner.pdf (25.04.03).